
Dr. Gujarati wins Best Paper for work on Machine Learning reliability
Machine Learning (ML) and the integrity of data is becoming more and more important in safety-critical systems like autonomous (self-driving) vehicles and medical imaging. If the data is either mislabelled, missing, or duplicated, it can significantly increase the chance of misclassification. When it comes to making a medical diagnosis or allowing a vehicle to drive itself, faulty data can have some very serious consequences. We need to find ways to minimize these possibilities.

That’s essentially what led Dr. Arpan Gujarati, a research associate in the UBC Computer Science Department, along with his colleagues, to submit their paper, “Understanding the Resilience of Neural Network Ensembles against Faulty Training Data” to QRS 2021, which ultimately won them a Best Paper award.
From rejection to Best Paper
The journey had begun in 2020. Dr. Gujarati and several of his co-authors started working together when he was completing his PhD in Germany at the Max Planck Institute for Software Systems (MPI-SWS). The others, Professor Karthik Pattabiraman and Associate Professor Dr. Sathish Gopalakrishnan, were based (and still are) at UBC’s Department of Electrical and Computer Engineering (ECE).
The team centred their research around the topic of reliability in terms of next-generation ML-based applications for autonomous vehicles.
“Initially, we wrote a short workshop paper together, mainly looking at theoretical models of reliability for these kinds of systems,” said Dr. Gujarati. “Our work evolved from there, and then last year in the middle of the pandemic, I moved to Vancouver to join the CS department here at UBC as a research associate.” The team came together with two additional ECE members, PhD student Abraham Chan and Masters student Niranjhana Narayanan.
When they first submitted their work at a different conference, it was rejected. “This can often be the case,” Arpan shrugged. “But it was an opportunity for us to pitch the solution in a different way. Rather than providing a definitive blanket solution, we restructured our paper around being more of a quantitative evaluation of our approach.”
It seems the rewrite did the trick.
“We were happy to get positive reviews because coming from a rejection, that feels like such a big difference! But getting a best paper award at QRS? We did not expect it at all, so that was indeed a nice surprise for us,” he said.
QRS is the IEEE international conference on Software Quality, Reliability, and Security. It brings together engineers and scientists from industry and academia to present and discuss their work on the development of reliable, secure, and trustworthy systems.
Switching gears to solve a problem
“We decided to look at the problem of data reliability from a different lens: the lens of classic software engineering,” Arpan said. “Take an airplane for example. If a company requires a critical piece of software for the plane, they might employ three teams to design software in parallel, then deploy all three in modular fashion. The expectation is that a combination of these three software pieces is likely to never fail. In other words, if there is a bug in one, the same bug will not be tied into the other software. All redundant components will not fail together at the same time, which is called modular redundancy. In our machine learning research, we decided to apply this same concept.”
“With machine learning, people are not developing the final software component entirely by hand,” Arpan explained. “So you’re not incurring the cost of multiple software designs. And once you have the training data, it's possible to download different kinds of models. I can train 10 different models using the same training data to do the same job without needing 10 different software engineering teams.”
“This is what the reviewers seemed to like: that we were looking at the problem of ML reliability from the perspective of software engineering,” he said. “It is a simpler approach than looking at the intricacies of a machine learning model’s math.”
After a process of injecting artificial faults into training data, and reasoning about them using diversity metrics, what the researchers found is that machine learning ensembles (groups of diverse models) are more resilient than any individual model, thanks to the high consensus level achieved.
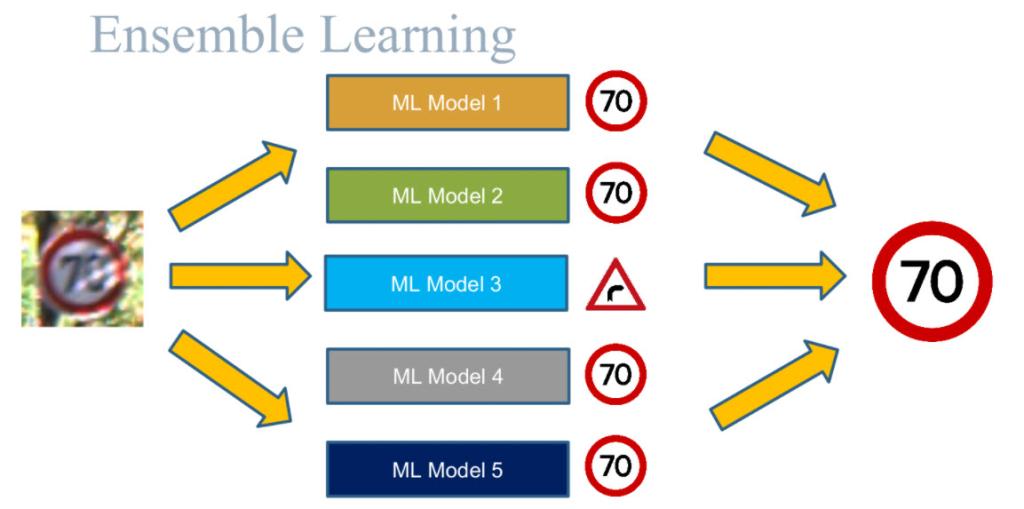
“These findings can help machine learning developers build ensembles that are both more resilient and more efficient,” Arpan explained.
Trying his hand at robotic security
When he’s not submitting papers about neural network ensembles, Arpan is researching the security of lab automation. He is collaborating with members of the Department of Chemistry who have a sizeable lab full of robotic arms and other software-controlled equipment. Because there are dangerous chemicals in the lab, security is important. “And because the robotic arms are operated online and remotely, they are susceptible to remote attacks exploiting vulnerabilities in the software stack,” Arpan said. “So we're looking at different types of techniques, some based on machine learning, and some based on classic security techniques, to improve the security of the infrastructure.”
Arpan says that over the next few months, an undergrad student will be helping to build a testbed of robotic arms and other equipment in the Systopia computer science lab, to which Arpan belongs. He is also continuing the work he started with Sathish, Karthik and Abraham. “We are comparing our simple approach with other approaches that alter the mathematical functions underlying the ML models and seeing which one is better quantitatively for different data sets.”
Whether it’s self-driving cars or robotic arms, Arpan Gujarati is certainly gaining traction in the software systems research world and being recognized for his efforts.