Algorithm research gets maximum results
Data, data, data. We use it for just about everything.
Today’s world is often interpreted and improved upon by recording and analyzing data. For example, consider Amazon reviews, detecting credit card fraud, or determining the likelihood of an individual contracting a specific disease.
But what about cases where the data we collect is incomplete or has missing values? When there is missing data, one can use predictive modelling to help fill in the blanks. Yet ideally, the results of these predictions need to take into account multiple likely values, rather than just the most likely (which might be misleading if there are many reasonable values).
This is where recent work on the expectation-maximization (EM) algorithm comes in, and has earned a group of researchers – UBC Computer Science PhD student Frederik Kunstner, Cornell University PhD student Raunak Kumar (previously a 2018 UBC BSc grad), and UBC CS Professor Dr. Mark Schmidt – top marks from the 2021 International Conference on Artificial Intelligence and Statistics (AISTATS).

Best Paper and top marks

In total, there were 1,527 submissions for the AISTATS conference, and their paper, "Homeomorphic-Invariance of EM: Non-Asymptotic Convergence in KL Divergence for Exponential Families via Mirror Descent" was the one selected as Best Paper by conference reviewers.
“Two of the final reviewers gave us a score of 10 out of 10, which I don't think I've ever got before on a paper,” said Mark. “It rarely happens, and to get that from multiple reviewers was such a shocking outcome. Typically, scores ranging from 4-6 are given even for good papers, as it’s the reviewers’ job to poke holes in your results.”

The expectation-maximization algorithm (EM) has a long and lustrous history with input from various statisticians, as well as from researchers in other fields like machine learning, optimization and information theory. But it was the momentous paper written in 1977 by Dempster et al. called ‘Maximum Likelihood from Incomplete Data via the EM Algorithm,’ that truly defined and named the algorithm for the first time. The paper has been cited over 60,000 times and is amongst the 100 most-cited papers in history across all fields.
“There have been over 200 papers over the past 40 years on the topic of how EM works,” said Mark. “But they all have problems in describing how the algorithm works on real data.”
But first, what exactly is the expectation-maximization algorithm?
The expectation-maximization algorithm is a method for performing the maximum likelihood estimation in the presence of unobserved data. It is an iterative process, first estimating the possible values of the missing data, then optimizing the model, then repeating these two steps until they stop making significant progress in fitting the data better.
“Even as recently as 2021, people are still finding new ways to use the EM algorithm to deal with missing data,” said Mark. “One of the most famous was in the 80s, when the algorithm was applied to astronomy data and found new types of stars.”
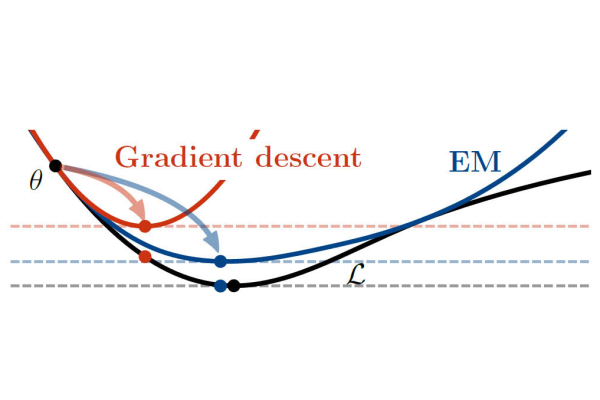
EM is just one way to find an explanation of the data with a high likelihood. The most popular alternate algorithm in Machine Learning to find a high likelihood is ‘gradient descent.' Mark explained how the two compare. “If you start out really close to a solution in your missing data problem, then EM is better than gradient descent. But in the case where you are very far from a solution, much research has been done in trying to figure out how EM can help you arrive at one. Our paper is the first work to show that, even when you're far from the solution, EM is actually faster than gradient descent, and could be infinitely faster for some datasets.”
Mark’s grad student, Frederik Kunstner, is first author on the paper and Mark attributes the success of their Best Paper award to him. “Fred really is the star. It was very impressive how he synthesized some very new ideas from optimization with some very old ideas from statistics and information theory and put them all together. Fred also did a fantastic job of using imagery in the paper to illustrate the dependencies that explained all the concepts. Most people don’t know all the aspects of the various fields that come into play here. There are maybe eight people in the world who do understand them all. So Fred’s inclusion of illustrations in the paper really helps those outside this very niche group, to comprehend the significance of the research findings.”
Mark’s interest in this topic first started when he took a course in statistics at UBC as a PhD student in 2006, although his work on the project started with Raunak’s summer research in 2018 at UBC.
Mark also explained that their paper doesn't look like a typical machine learning paper because there are no experiments, nor are there new models.
"Our paper is the first work to show that, even when you're far from the solution, EM is actually faster than gradient descent, and could be infinitely faster for some datasets.” ~ Dr. Mark Schmidt
“It’s just an explanation for how this algorithm actually works,” Mark explained. “But having said that, we believe this is one of the most significant advances in our understanding of EM since the Dempster article. I’m quite certain this research will be in textbooks and replace many ideas that came before.”
One could surmise that Mark and his research team have already exceeded even their own maximum expectations for their work's impact.