Google Scholar
Recent First, Most Cited First
Conference
-
 Harvey, W., Naderiparizi, S., Masrani, V., Weilbach, C., & Wood, F. (2022). Flexible Diffusion Modeling of Long Videos. Thirty-Sixth Conference on Neural Information Processing Systems (NeurIPS). PDF
Harvey, W., Naderiparizi, S., Masrani, V., Weilbach, C., & Wood, F. (2022). Flexible Diffusion Modeling of Long Videos. Thirty-Sixth Conference on Neural Information Processing Systems (NeurIPS). PDF@inproceedings{harvey2022flexible, title = {Flexible Diffusion Modeling of Long Videos}, author = {Harvey, William and Naderiparizi, Saeid and Masrani, Vaden and Weilbach, Christian and Wood, Frank}, booktitle = {Thirty-sixth Conference on Neural Information Processing Systems (NeurIPS)}, archiveprefix = {arXiv}, eprint = {2205.11495}, year = {2022} } -
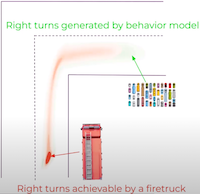 Liu, Y., Lavington, J. W., Ścibior, A., & Wood, F. (2022). Vehicle Type Specific Waypoint Generation. IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). PDF
Liu, Y., Lavington, J. W., Ścibior, A., & Wood, F. (2022). Vehicle Type Specific Waypoint Generation. IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). PDF@inproceedings{liu2022iros, title = {Vehicle Type Specific Waypoint Generation}, author = {Liu, Yunpeng and Lavington, Jonathan Wilder and {\'S}cibior, Adam and Wood, Frank}, booktitle = {IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)}, archiveprefix = {arXiv}, eprint = {2208.04987}, year = {2022} } -
 Yoo, J., & Wood, F. (2022). BayesPCN: A Continually Learnable Predictive Coding Associative Memory. Thirty-Sixth Conference on Neural Information Processing Systems (NeurIPS).
Yoo, J., & Wood, F. (2022). BayesPCN: A Continually Learnable Predictive Coding Associative Memory. Thirty-Sixth Conference on Neural Information Processing Systems (NeurIPS).@inproceedings{yoo2022bayespcn, title = {Bayes{PCN}: A Continually Learnable Predictive Coding Associative Memory}, author = {Yoo, Jason and Wood, Frank}, booktitle = {Thirty-sixth Conference on Neural Information Processing Systems (NeurIPS)}, archiveprefix = {arXiv}, eprint = {2205.09930}, year = {2022} } -
Munk, A., Zwartsenberg, B., Ścibior, A., Baydin, A. G., Stewart, A. L., Fernlund, G., Poursartip, A., & Wood, F. (2022). Probabilistic Surrogate Networks for Simulators with Unbounded Randomness . The 38th Conference on Uncertainty in Artificial Intelligence.
@inproceedings{munk2022probabilistic, title = {Probabilistic Surrogate Networks for Simulators with Unbounded Randomness }, author = {Munk, Andreas and Zwartsenberg, Berend and {\'S}cibior, Adam and Baydin, Atilim Gunes and Stewart, Andrew Lawrence and Fernlund, Goran and Poursartip, Anoush and Wood, Frank}, booktitle = {The 38th Conference on Uncertainty in Artificial Intelligence}, year = {2022} } -
Naderiparizi, S., Ścibior, A., Munk, A., Ghadiri, M., Baydin, A. G., Gram-Hansen, B. J., De Witt, C. A. S., Zinkov, R., Torr, P., Rainforth, T., & others. (2022). Amortized rejection sampling in universal probabilistic programming . International Conference on Artificial Intelligence and Statistics, 8392–8412.
@inproceedings{naderiparizi2022amortized, title = {Amortized rejection sampling in universal probabilistic programming }, author = {Naderiparizi, Saeid and {\'S}cibior, Adam and Munk, Andreas and Ghadiri, Mehrdad and Baydin, Atilim Gunes and Gram-Hansen, Bradley J and De Witt, Christian A Schroeder and Zinkov, Robert and Torr, Philip and Rainforth, Tom and others}, booktitle = {International Conference on Artificial Intelligence and Statistics}, pages = {8392--8412}, year = {2022}, organization = {PMLR} } -
Bateni, P., Barber, J., van de Meent, J.-W., & Wood, F. (2022). Enhancing Few-Shot Image Classification With Unlabelled Examples. Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), 2796–2805.
@inproceedings{Bateni_2022_WACV, author = {Bateni, Peyman and Barber, Jarred and van de Meent, Jan-Willem and Wood, Frank}, title = {Enhancing Few-Shot Image Classification With Unlabelled Examples}, booktitle = {Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV)}, month = jan, year = {2022}, pages = {2796-2805} } -
Harvey, W., Naderiparizi, S., & Wood, F. (2022). Conditional Image Generation by Conditioning Variational Auto-Encoders. International Conference on Learning Representations.
@inproceedings{harvey2022conditional, title = {Conditional Image Generation by Conditioning Variational Auto-Encoders}, author = {Harvey, William and Naderiparizi, Saeid and Wood, Frank}, booktitle = {International Conference on Learning Representations}, year = {2022} } -
Bateni, P., Barber, J., van de Meent, J.-W., & Wood, F. (2022). Enhancing Few-Shot Image Classification with Unlabelled Examples. WACV.
@inproceedings{bateni2020enhancing, title = {Enhancing Few-Shot Image Classification with Unlabelled Examples}, author = {Bateni, Peyman and Barber, Jarred and van de Meent, Jan-Willem and Wood, Frank}, booktitle = {WACV}, year = {2022} } -
Masrani, V., Brekelmans, R., Bui, T., Nielsen, F., Galstyan, A., Ver Steeg, G., & Wood, F. (2021). q-Paths: Generalizing the geometric annealing path using power means. In C. de Campos & M. H. Maathuis (Eds.), Proceedings of the Thirty-Seventh Conference on Uncertainty in Artificial Intelligence (Vol. 161, pp. 1938–1947). PMLR.
@inproceedings{pmlr-v161-masrani21a, title = {q-Paths: Generalizing the geometric annealing path using power means}, author = {Masrani, Vaden and Brekelmans, Rob and Bui, Thang and Nielsen, Frank and Galstyan, Aram and Ver Steeg, Greg and Wood, Frank}, booktitle = {Proceedings of the Thirty-Seventh Conference on Uncertainty in Artificial Intelligence}, pages = {1938--1947}, year = {2021}, editor = {de Campos, Cassio and Maathuis, Marloes H.}, volume = {161}, series = {Proceedings of Machine Learning Research}, month = {27--30 Jul}, publisher = {PMLR} } -
Munk, A., Harvey, W., & Wood, F. (2021). Assisting the Adversary to Improve GAN Training . 2021 International Joint Conference on Neural Networks (IJCNN), 1–8. https://doi.org/10.1109/IJCNN52387.2021.9533449
@inproceedings{9533449, author = {Munk, Andreas and Harvey, William and Wood, Frank}, booktitle = {2021 International Joint Conference on Neural Networks (IJCNN)}, title = {Assisting the Adversary to Improve {GAN} Training }, year = {2021}, pages = {1-8}, doi = {10.1109/IJCNN52387.2021.9533449} } -
Ścibior, A., Lioutas, V., Reda, D., Bateni, P., & Wood, F. (2021). Imagining The Road Ahead: Multi-Agent Trajectory Prediction via Differentiable Simulation . IEEE Intelligent Transportation Systems Conference (ITSC).
@inproceedings{scibior2021imagining, title = {{I}magining {T}he {R}oad {A}head: Multi-Agent Trajectory Prediction via Differentiable Simulation }, author = {{\'S}cibior, Adam and Lioutas, Vasileios and Reda, Daniele and Bateni, Peyman and Wood, Frank}, booktitle = {IEEE Intelligent Transportation Systems Conference (ITSC)}, year = {2021}, eprint = {2104.11212}, archiveprefix = {arXiv} } -
Ścibior, A., Masrani, V., & Wood, F. (2021). Differentiable Particle Filtering without Modifying the Forward Pass. International Conference on Probabilistic Programming (PROBPROG).
@inproceedings{scibior2021differentiable, title = {Differentiable Particle Filtering without Modifying the Forward Pass}, author = {{\'S}cibior, Adam and Masrani, Vaden and Wood, Frank}, booktitle = {International Conference on Probabilistic Programming (PROBPROG)}, archiveprefix = {arXiv}, eid = {arXiv:2106.10314}, eprint = {2106.10314}, year = {2021} } -
Beronov, B., Weilbach, C., Wood, F., & Campbell, T. (2021). Sequential Core-Set Monte Carlo. Conference on Uncertainty in Artificial Intelligence (UAI).
@inproceedings{beronovsequential, title = {Sequential Core-Set {M}onte {C}arlo}, author = {Beronov, Boyan and Weilbach, Christian and Wood, Frank and Campbell, Trevor}, booktitle = {Conference on Uncertainty in Artificial Intelligence (UAI)}, year = {2021} } -
Masrani, V., Brekelmans, R., Bui, T., Nielsen, F., Galstyan, A., Steeg, G. V., & Wood, F. (2021). q-Paths: Generalizing the Geometric Annealing Path using Power Means. Conference on Uncertainty in Artificial Intelligence (UAI).
@inproceedings{MAS-21, title = {q-{P}aths: Generalizing the Geometric Annealing Path using Power Means}, author = {Masrani, Vaden and Brekelmans, Rob and Bui, Thang and Nielsen, Frank and Galstyan, Aram and Steeg, Greg Ver and Wood, Frank}, booktitle = {Conference on Uncertainty in Artificial Intelligence (UAI)}, archiveprefix = {arXiv}, eid = {arXiv:2107.00745}, eprint = {2107.00745}, year = {2021} } -
Warrington, A., Lavington, J. W., Ścibior, A., Schmidt, M., & Wood, F. (2021). Robust asymmetric learning in POMDPs . International Conference on Machine Learning (ICML), 11013–11023.
@inproceedings{warrington2021robust, title = {Robust asymmetric learning in {POMDP}s }, author = {Warrington, Andrew and Lavington, Jonathan W and {\'S}cibior, Adam and Schmidt, Mark and Wood, Frank}, booktitle = {International Conference on Machine Learning (ICML)}, pages = {11013--11023}, year = {2021}, organization = {PMLR} } -
 Nguyen, V., Masrani, V., Brekelmans, R., Osborne, M., & Wood, F. (2020). Gaussian Process Bandit Optimization of the Thermodynamic Variational Objective. Advances in Neural Information Processing Systems (NeurIPS). PDF
Nguyen, V., Masrani, V., Brekelmans, R., Osborne, M., & Wood, F. (2020). Gaussian Process Bandit Optimization of the Thermodynamic Variational Objective. Advances in Neural Information Processing Systems (NeurIPS). PDFAchieving the full promise of the Thermodynamic Variational Objective (TVO), a recently proposed variational lower bound on the log evidence involving a one-dimensional Riemann integral approximation, requires choosing a "schedule" of sorted discretization points. This paper introduces a bespoke Gaussian process bandit optimization method for automatically choosing these points. Our approach not only automates their one-time selection, but also dynamically adapts their positions over the course of optimization, leading to improved model learning and inference. We provide theoretical guarantees that our bandit optimization converges to the regret-minimizing choice of integration points. Empirical validation of our algorithm is provided in terms of improved learning and inference in Variational Autoencoders and Sigmoid Belief Networks.
@inproceedings{nguyen2020gaussian, title = {Gaussian Process Bandit Optimization of the Thermodynamic Variational Objective}, author = {Nguyen, Vu and Masrani, Vaden and Brekelmans, Rob and Osborne, Michael and Wood, Frank}, booktitle = {Advances in Neural Information Processing Systems (NeurIPS)}, year = {2020}, url_link = {https://proceedings.neurips.cc/paper/2020/hash/3f2dff7862a70f97a59a1fa02c3ec110-Abstract.html}, url_paper = {https://proceedings.neurips.cc/paper/2020/file/3f2dff7862a70f97a59a1fa02c3ec110-Paper.pdf}, url_arxiv = {https://arxiv.org/abs/2010.15750}, support = {D3M} } -
 Le, T. A., Kosiorek, A. R., Siddharth, N., Teh, Y. W., & Wood, F. (2020). Revisiting Reweighted Wake-Sleep for Models with Stochastic Control Flow. In R. P. Adams & V. Gogate (Eds.), Uncertainty in Artificial Intelligence (UAI) (Vol. 115, pp. 1039–1049). PMLR. PDF
Le, T. A., Kosiorek, A. R., Siddharth, N., Teh, Y. W., & Wood, F. (2020). Revisiting Reweighted Wake-Sleep for Models with Stochastic Control Flow. In R. P. Adams & V. Gogate (Eds.), Uncertainty in Artificial Intelligence (UAI) (Vol. 115, pp. 1039–1049). PMLR. PDFStochastic control-flow models (SCFMs) are a class of generative models that involve branching on choices from discrete random variables. Amortized gradient-based learning of SCFMs is challenging as most approaches targeting discrete variables rely on their continuous relaxations—which can be intractable in SCFMs, as branching on relaxations requires evaluating all (exponentially many) branching paths. Tractable alternatives mainly combine REINFORCE with complex control-variate schemes to improve the variance of naive estimators. Here, we revisit the reweighted wake-sleep (RWS) [5] algorithm, and through extensive evaluations, show that it outperforms current state-of-the-art methods in learning SCFMs. Further, in contrast to the importance weighted autoencoder, we observe that RWS learns better models and inference networks with increasing numbers of particles. Our results suggest that RWS is a competitive, often preferable, alternative for learning SCFMs.
@inproceedings{Le-20, title = {Revisiting Reweighted Wake-Sleep for Models with Stochastic Control Flow}, author = {Le, Tuan Anh and Kosiorek, Adam R. and Siddharth, N. and Teh, Yee Whye and Wood, Frank}, pages = {1039--1049}, year = {2020}, editor = {Adams, Ryan P. and Gogate, Vibhav}, volume = {115}, series = {Proceedings of Machine Learning Research}, booktitle = {Uncertainty in Artificial Intelligence (UAI)}, address = {Tel Aviv, Israel}, month = {22--25 Jul}, publisher = {PMLR}, url_link = {http://proceedings.mlr.press/v115/le20a.html}, url_paper = {http://proceedings.mlr.press/v115/le20a/le20a.pdf}, support = {D3M} } -
Teng, M., Le, T. A., Scibior, A., & Wood, F. (2020). Semi-supervised Sequential Generative Models. Conference on Uncertainty in Artificial Intelligence (UAI). PDF
@inproceedings{TEN-20, title = {Semi-supervised Sequential Generative Models}, author = {Teng, Michael and Le, Tuan Anh and Scibior, Adam and Wood, Frank}, booktitle = {Conference on Uncertainty in Artificial Intelligence (UAI)}, eid = {arXiv:2007.00155}, archiveprefix = {arXiv}, eprint = {2007.00155}, url_link = {http://www.auai.org/~w-auai/uai2020/accepted.php}, url_paper = {http://www.auai.org/uai2020/proceedings/272_main_paper.pdf}, url_arxiv = {https://arxiv.org/abs/2007.00155}, support = {D3M}, year = {2020} } -
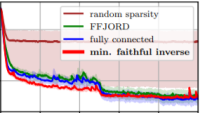 Weilbach, C., Beronov, B., Wood, F., & Harvey, W. (2020). Structured Conditional Continuous Normalizing Flows for Efficient Amortized Inference in Graphical Models. Proceedings of the Twenty Third International Conference on Artificial Intelligence and Statistics (AISTATS), 4441–4451. PDF
Weilbach, C., Beronov, B., Wood, F., & Harvey, W. (2020). Structured Conditional Continuous Normalizing Flows for Efficient Amortized Inference in Graphical Models. Proceedings of the Twenty Third International Conference on Artificial Intelligence and Statistics (AISTATS), 4441–4451. PDFWe exploit minimally faithful inversion of graphical model structures to specify sparse continuous normalizing flows (CNFs) for amortized inference. We find that the sparsity of this factorization can be exploited to reduce the numbers of parameters in the neural network, adaptive integration steps of the flow, and consequently FLOPs at both training and inference time without decreasing performance in comparison to unconstrained flows. By expressing the structure inversion as a compilation pass in a probabilistic programming language, we are able to apply it in a novel way to models as complex as convolutional neural networks. Furthermore, we extend the training objective for CNFs in the context of inference amortization to the symmetric Kullback-Leibler divergence, and demonstrate its theoretical and practical advantages.
@inproceedings{WEI-20, title = {Structured Conditional Continuous Normalizing Flows for Efficient Amortized Inference in Graphical Models}, author = {Weilbach, Christian and Beronov, Boyan and Wood, Frank and Harvey, William}, booktitle = {Proceedings of the Twenty Third International Conference on Artificial Intelligence and Statistics (AISTATS)}, pages = {4441--4451}, year = {2020}, url_link = {http://proceedings.mlr.press/v108/weilbach20a.html}, url_paper = {http://proceedings.mlr.press/v108/weilbach20a/weilbach20a.pdf}, url_poster = {https://github.com/plai-group/bibliography/blob/master/presentations_posters/PROBPROG2020_WEI.pdf}, support = {D3M}, bibbase_note = {PMLR 108:4441-4451} } -
 Naderiparizi, S., Ścibior, A., Munk, A., Ghadiri, M., Baydin, A. G., Gram-Hansen, B., de Witt, C. S., Zinkov, R., Torr, P. H. S., Rainforth, T., & others. (2020). Amortized rejection sampling in universal probabilistic programming. International Conference on Probabilistic Programming (PROBPROG). PDF
Naderiparizi, S., Ścibior, A., Munk, A., Ghadiri, M., Baydin, A. G., Gram-Hansen, B., de Witt, C. S., Zinkov, R., Torr, P. H. S., Rainforth, T., & others. (2020). Amortized rejection sampling in universal probabilistic programming. International Conference on Probabilistic Programming (PROBPROG). PDFExisting approaches to amortized inference in probabilistic programs with unbounded loops can produce estimators with infinite variance. An instance of this is importance sampling inference in programs that explicitly include rejection sampling as part of the user-programmed generative procedure. In this paper we develop a new and efficient amortized importance sampling estimator. We prove finite variance of our estimator and empirically demonstrate our method’s correctness and efficiency compared to existing alternatives on generative programs containing rejection sampling loops and discuss how to implement our method in a generic probabilistic programming framework.
@inproceedings{NAD-20, title = {Amortized rejection sampling in universal probabilistic programming}, author = {Naderiparizi, Saeid and {\'S}cibior, Adam and Munk, Andreas and Ghadiri, Mehrdad and Baydin, At{\i}l{\i}m G{\"u}ne{\c{s}} and Gram-Hansen, Bradley and de Witt, Christian Schroeder and Zinkov, Robert and Torr, Philip HS and Rainforth, Tom and others}, booktitle = {International Conference on Probabilistic Programming (PROBPROG)}, year = {2020}, eid = {arXiv:1910.09056}, archiveprefix = {arXiv}, eprint = {1910.09056}, url_paper = {https://arxiv.org/pdf/1910.09056.pdf}, url_arxiv = {https://arxiv.org/abs/1910.09056}, url_poster = {https://github.com/plai-group/bibliography/blob/master/presentations_posters/PROBPROG2020_NAD.pdf}, support = {D3M,ETALUMIS} } -
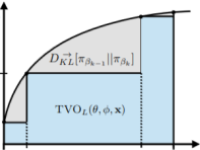 Brekelmans, R., Masrani, V., Wood, F., Ver Steeg, G., & Galstyan, A. (2020, July). All in the Exponential Family: Bregman Duality in Thermodynamic Variational Inference. Thirty-Seventh International Conference on Machine Learning (ICML 2020). PDF
Brekelmans, R., Masrani, V., Wood, F., Ver Steeg, G., & Galstyan, A. (2020, July). All in the Exponential Family: Bregman Duality in Thermodynamic Variational Inference. Thirty-Seventh International Conference on Machine Learning (ICML 2020). PDFThe recently proposed Thermodynamic Variational Objective (TVO) leverages thermodynamic integration to provide a family of variational inference objectives, which both tighten and generalize the ubiquitous Evidence Lower Bound (ELBO). However, the tightness of TVO bounds was not previously known, an expensive grid search was used to choose a "schedule" of intermediate distributions, and model learning suffered with ostensibly tighter bounds. In this work, we propose an exponential family interpretation of the geometric mixture curve underlying the TVO and various path sampling methods, which allows us to characterize the gap in TVO likelihood bounds as a sum of KL divergences. We propose to choose intermediate distributions using equal spacing in the moment parameters of our exponential family, which matches grid search performance and allows the schedule to adaptively update over the course of training. Finally, we derive a doubly reparameterized gradient estimator which improves model learning and allows the TVO to benefit from more refined bounds. To further contextualize our contributions, we provide a unified framework for understanding thermodynamic integration and the TVO using Taylor series remainders.
@inproceedings{BRE-20, author = {{Brekelmans}, Rob and {Masrani}, Vaden and {Wood}, Frank and {Ver Steeg}, Greg and {Galstyan}, Aram}, title = {All in the Exponential Family: Bregman Duality in Thermodynamic Variational Inference}, booktitle = {Thirty-seventh International Conference on Machine Learning (ICML 2020)}, keywords = {Computer Science - Machine Learning, Statistics - Machine Learning}, year = {2020}, month = jul, eid = {arXiv:2007.00642}, archiveprefix = {arXiv}, eprint = {2007.00642}, url_link = {https://proceedings.icml.cc/book/2020/hash/12311d05c9aa67765703984239511212}, url_paper = {https://proceedings.icml.cc/static/paper_files/icml/2020/2826-Paper.pdf}, url_arxiv = {https://arxiv.org/abs/2007.00642}, support = {D3M} } -
 Warrington, A., Naderiparizi, S., & Wood, F. (2020). Coping With Simulators That Don’t Always Return. The 23rd International Conference on Artificial Intelligence and Statistics (AISTATS). PDF
Warrington, A., Naderiparizi, S., & Wood, F. (2020). Coping With Simulators That Don’t Always Return. The 23rd International Conference on Artificial Intelligence and Statistics (AISTATS). PDFDeterministic models are approximations of reality that are easy to interpret and often easier to build than stochastic alternatives. Unfortunately, as nature is capricious, observational data can never be fully explained by deterministic models in practice. Observation and process noise need to be added to adapt deterministic models to behave stochastically, such that they are capable of explaining and extrapolating from noisy data. We investigate and address computational inefficiencies that arise from adding process noise to deterministic simulators that fail to return for certain inputs; a property we describe as "brittle." We show how to train a conditional normalizing flow to propose perturbations such that the simulator succeeds with high probability, increasing computational efficiency.
@inproceedings{WAR-20, title = {Coping With Simulators That Don’t Always Return}, author = {Warrington, A and Naderiparizi, S and Wood, F}, booktitle = {The 23rd International Conference on Artificial Intelligence and Statistics (AISTATS)}, archiveprefix = {arXiv}, eprint = {1906.05462}, year = {2020}, url_link = {http://proceedings.mlr.press/v108/warrington20a.html}, url_paper = {http://proceedings.mlr.press/v108/warrington20a/warrington20a.pdf}, url_poster = {https://github.com/plai-group/bibliography/blob/master/presentations_posters/WAR-20.pdf}, url_arxiv = {https://arxiv.org/abs/2003.12908}, keywords = {simulators, smc, autoregressive flow}, support = {D3M,ETALUMIS}, bibbase_note = {PMLR 108:1748-1758} } -
 Harvey, W., Munk, A., Baydin, A. G., Bergholm, A., & Wood, F. (2020). Attention for Inference Compilation. The Second International Conference on Probabilistic Programming (PROBPROG). PDF
Harvey, W., Munk, A., Baydin, A. G., Bergholm, A., & Wood, F. (2020). Attention for Inference Compilation. The Second International Conference on Probabilistic Programming (PROBPROG). PDFWe present a new approach to automatic amortized inference in universal probabilistic programs which improves performance compared to current methods. Our approach is a variation of inference compilation (IC) which leverages deep neural networks to approximate a posterior distribution over latent variables in a probabilistic program. A challenge with existing IC network architectures is that they can fail to model long-range dependencies between latent variables. To address this, we introduce an attention mechanism that attends to the most salient variables previously sampled in the execution of a probabilistic program. We demonstrate that the addition of attention allows the proposal distributions to better match the true posterior, enhancing inference about latent variables in simulators.
@inproceedings{HAR-20, title = {Attention for Inference Compilation}, author = {Harvey, W and Munk, A and Baydin, AG and Bergholm, A and Wood, F}, booktitle = {The second International Conference on Probabilistic Programming (PROBPROG)}, year = {2020}, archiveprefix = {arXiv}, eprint = {1910.11961}, support = {D3M,LwLL}, url_paper = {https://arxiv.org/pdf/1910.11961.pdf}, url_arxiv = {https://arxiv.org/abs/1910.11961}, url_poster = {https://github.com/plai-group/bibliography/blob/master/presentations_posters/PROBPROG2020_HAR.pdf} } -
 Munk, A., Ścibior, A., Baydin, A. G., Stewart, A., Fernlund, A., Poursartip, A., & Wood, F. (2020). Deep probabilistic surrogate networks for universal simulator approximation. The Second International Conference on Probabilistic Programming (PROBPROG). PDF
Munk, A., Ścibior, A., Baydin, A. G., Stewart, A., Fernlund, A., Poursartip, A., & Wood, F. (2020). Deep probabilistic surrogate networks for universal simulator approximation. The Second International Conference on Probabilistic Programming (PROBPROG). PDFWe present a framework for automatically structuring and training fast, approximate, deep neural surrogates of existing stochastic simulators. Unlike traditional approaches to surrogate modeling, our surrogates retain the interpretable structure of the reference simulators. The particular way we achieve this allows us to replace the reference simulator with the surrogate when undertaking amortized inference in the probabilistic programming sense. The fidelity and speed of our surrogates allow for not only faster "forward" stochastic simulation but also for accurate and substantially faster inference. We support these claims via experiments that involve a commercial composite-materials curing simulator. Employing our surrogate modeling technique makes inference an order of magnitude faster, opening up the possibility of doing simulator-based, non-invasive, just-in-time parts quality testing; in this case inferring safety-critical latent internal temperature profiles of composite materials undergoing curing from surface temperature profile measurements.
@inproceedings{MUN-20, title = {Deep probabilistic surrogate networks for universal simulator approximation}, author = {Munk, Andreas and Ścibior, Adam and Baydin, AG and Stewart, A and Fernlund, A and Poursartip, A and Wood, Frank}, booktitle = {The second International Conference on Probabilistic Programming (PROBPROG)}, year = {2020}, archiveprefix = {arXiv}, eprint = {1910.11950}, support = {D3M,ETALUMIS}, url_paper = {https://arxiv.org/pdf/1910.11950.pdf}, url_arxiv = {https://arxiv.org/abs/1910.11950}, url_poster = {https://github.com/plai-group/bibliography/blob/master/presentations_posters/PROBPROG2020_MUN.pdf} } -
Bateni, P., Goyal, R., Masrani, V., Wood, F., & Sigal, L. (2020). Improved Few-Shot Visual Classification. Conference on Computer Vision and Pattern Recognition (CVPR). PDF
Few-shot learning is a fundamental task in computer vision that carries the promise of alleviating the need for exhaustively labeled data. Most few-shot learning approaches to date have focused on progressively more complex neural feature extractors and classifier adaptation strategies, as well as the refinement of the task definition itself. In this paper, we explore the hypothesis that a simple class-covariance-based distance metric, namely the Mahalanobis distance, adopted into a state of the art few-shot learning approach (CNAPS) can, in and of itself, lead to a significant performance improvement. We also discover that it is possible to learn adaptive feature extractors that allow useful estimation of the high dimensional feature covariances required by this metric from surprisingly few samples. The result of our work is a new "Simple CNAPS" architecture which has up to 9.2% fewer trainable parameters than CNAPS and performs up to 6.1% better than state of the art on the standard few-shot image classification benchmark dataset.
@inproceedings{BAT-20, author = {{Bateni}, Peyman and {Goyal}, Raghav and {Masrani}, Vaden and {Wood}, Frank and {Sigal}, Leonid}, title = {Improved Few-Shot Visual Classification}, booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)}, keywords = {LwLL, Computer Science - Computer Vision and Pattern Recognition}, year = {2020}, eid = {arXiv:1912.03432}, archiveprefix = {arXiv}, eprint = {1912.03432}, support = {D3M,LwLL}, url_link = {https://openaccess.thecvf.com/content_CVPR_2020/html/Bateni_Improved_Few-Shot_Visual_Classification_CVPR_2020_paper.html}, url_paper = {http://openaccess.thecvf.com/content_CVPR_2020/papers/Bateni_Improved_Few-Shot_Visual_Classification_CVPR_2020_paper.pdf}, url_arxiv = {https://arxiv.org/abs/1912.03432} } -
 Teng, M., Le, T. A., Scibior, A., & Wood, F. (2019). Imitation Learning of Factored Multi-agent Reactive Models. PDF
Teng, M., Le, T. A., Scibior, A., & Wood, F. (2019). Imitation Learning of Factored Multi-agent Reactive Models. PDFWe apply recent advances in deep generative modeling to the task of imitation learning from biological agents. Specifically, we apply variations of the variational recurrent neural network model to a multi-agent setting where we learn policies of individual uncoordinated agents acting based on their perceptual inputs and their hidden belief state. We learn stochastic policies for these agents directly from observational data, without constructing a reward function. An inference network learned jointly with the policy allows for efficient inference over the agent’s belief state given a sequence of its current perceptual inputs and the prior actions it performed, which lets us extrapolate observed sequences of behavior into the future while maintaining uncertainty estimates over future trajectories. We test our approach on a dataset of flies interacting in a 2D environment, where we demonstrate better predictive performance than existing approaches which learn deterministic policies with recurrent neural networks. We further show that the uncertainty estimates over future trajectories we obtain are well calibrated, which makes them useful for a variety of downstream processing tasks.
@unpublished{TEN-19, title = {Imitation Learning of Factored Multi-agent Reactive Models}, author = {Teng, Michael and Le, Tuan Anh and Scibior, Adam and Wood, Frank}, archiveprefix = {arXiv}, eprint = {1903.04714}, year = {2019}, url_paper = {https://arxiv.org/pdf/1903.04714.pdf}, url_arxiv = {https://arxiv.org/abs/1903.04714}, support = {D3M} } -
 Masrani, V., Le, T. A., & Wood, F. (2019). The Thermodynamic Variational Objective. Thirty-Third Conference on Neural Information Processing Systems (NeurIPS). PDF
Masrani, V., Le, T. A., & Wood, F. (2019). The Thermodynamic Variational Objective. Thirty-Third Conference on Neural Information Processing Systems (NeurIPS). PDFWe introduce the thermodynamic variational objective (TVO) for learning in both continuous and discrete deep generative models. The TVO arises from a key connection between variational inference and thermodynamic integration that results in a tighter lower bound to the log marginal likelihood than the standard variational variational evidence lower bound (ELBO) while remaining as broadly applicable. We provide a computationally efficient gradient estimator for the TVO that applies to continuous, discrete, and non-reparameterizable distributions and show that the objective functions used in variational inference, variational autoencoders, wake sleep, and inference compilation are all special cases of the TVO. We use the TVO to learn both discrete and continuous deep generative models and empirically demonstrate state of the art model and inference network learning.
@inproceedings{MAS-19, title = {The Thermodynamic Variational Objective}, author = {Masrani, Vaden and Le, Tuan Anh and Wood, Frank}, booktitle = {Thirty-third Conference on Neural Information Processing Systems (NeurIPS)}, archiveprefix = {arXiv}, eprint = {1907.00031}, url_paper = {https://arxiv.org/pdf/1907.00031.pdf}, url_arxiv = {https://arxiv.org/abs/1907.00031}, url_poster = {https://github.com/plai-group/bibliography/blob/master/presentations_posters/neurips_tvo_poster.pdf}, support = {D3M}, year = {2019} } -
Gunes Baydin, A., Heinrich, L., Bhimji, W., Gram-Hansen, B., Louppe, G., Shao, L., Cranmer, K., Wood, F., & others. (2019). Efficient Probabilistic Inference in the Quest for Physics Beyond the Standard Model. Advances in Neural Information Processing Systems 32 (2019).
@article{gunes2019efficient, title = {Efficient Probabilistic Inference in the Quest for Physics Beyond the Standard Model}, author = {Gunes Baydin, Atilim and Heinrich, Lukas and Bhimji, Wahid and Gram-Hansen, Bradley and Louppe, Gilles and Shao, Lei and Cranmer, Kyle and Wood, Frank and others}, journal = {Advances in Neural Information Processing Systems 32 (2019)}, year = {2019} } -
 Baydin, A. G., Shao, L., Bhimji, W., Heinrich, L., Meadows, L., Liu, J., Munk, A., Naderiparizi, S., Gram-Hansen, B., Louppe, G., & others. (2019). Etalumis: Bringing Probabilistic Programming to Scientific Simulators at Scale. The International Conference for High Performance Computing, Networking, Storage and Analysis (SC ’19). https://doi.org/10.1145/3295500.3356180 PDF
Baydin, A. G., Shao, L., Bhimji, W., Heinrich, L., Meadows, L., Liu, J., Munk, A., Naderiparizi, S., Gram-Hansen, B., Louppe, G., & others. (2019). Etalumis: Bringing Probabilistic Programming to Scientific Simulators at Scale. The International Conference for High Performance Computing, Networking, Storage and Analysis (SC ’19). https://doi.org/10.1145/3295500.3356180 PDFProbabilistic programming languages (PPLs) are receiving widespread attention for performing Bayesian inference in complex generative models. However, applications to science remain limited because of the impracticability of rewriting complex scientific simulators in a PPL, the computational cost of inference, and the lack of scalable implementations. To address these, we present a novel PPL framework that couples directly to existing scientific simulators through a cross-platform probabilistic execution protocol and provides Markov chain Monte Carlo (MCMC) and deep-learning-based inference compilation (IC) engines for tractable inference. To guide IC inference, we perform distributed training of a dynamic 3DCNN–LSTM architecture with a PyTorch-MPI-based framework on 1,024 32-core CPU nodes of the Cori supercomputer with a global minibatch size of 128k: achieving a performance of 450 Tflop/s through enhancements to PyTorch. We demonstrate a Large Hadron Collider (LHC) use-case with the C++ Sherpa simulator and achieve the largest-scale posterior inference in a Turing-complete PPL.
@inproceedings{BAY-19, title = {Etalumis: Bringing Probabilistic Programming to Scientific Simulators at Scale}, author = {Baydin, At{\i}l{\i}m G{\"u}ne{\c{s}} and Shao, Lei and Bhimji, Wahid and Heinrich, Lukas and Meadows, Lawrence and Liu, Jialin and Munk, Andreas and Naderiparizi, Saeid and Gram-Hansen, Bradley and Louppe, Gilles and others}, booktitle = {the International Conference for High Performance Computing, Networking, Storage and Analysis (SC ’19)}, archiveprefix = {arXiv}, eprint = {1907.03382}, support = {D3M,ETALUMIS}, url_paper = {https://arxiv.org/pdf/1907.03382.pdf}, url_arxiv = {https://arxiv.org/abs/1907.03382}, year = {2019}, doi = {10.1145/3295500.3356180} } -
 Goliński, A., Wood, F., & Rainforth, T. (2019). Amortized Monte Carlo Integration. ICML. PDF
Goliński, A., Wood, F., & Rainforth, T. (2019). Amortized Monte Carlo Integration. ICML. PDF@article{golinski2019amortized, title = {Amortized Monte Carlo Integration}, author = {Goli{\'n}ski, Adam and Wood, Frank and Rainforth, Tom}, journal = {ICML}, year = {2019} } -
 Zhou, Y., Gram-Hansen, B. J., Kohn, T., Rainforth, T., Yang, H., & Wood, F. (2019). LF-PPL: A Low-Level First Order Probabilistic Programming Language for Non-Differentiable Models. Proceedings of the Twentieth International Conference on Artificial Intelligence and Statistics. PDF
Zhou, Y., Gram-Hansen, B. J., Kohn, T., Rainforth, T., Yang, H., & Wood, F. (2019). LF-PPL: A Low-Level First Order Probabilistic Programming Language for Non-Differentiable Models. Proceedings of the Twentieth International Conference on Artificial Intelligence and Statistics. PDF@inproceedings{zhou2019lf, title = {{LF-PPL}: A Low-Level First Order Probabilistic Programming Language for Non-Differentiable Models}, author = {Zhou, Yuan and Gram-Hansen, Bradley J and Kohn, Tobias and Rainforth, Tom and Yang, Hongseok and Wood, Frank}, booktitle = {Proceedings of the Twentieth International Conference on Artificial Intelligence and Statistics}, year = {2019} } -
 Teng, M., & Wood, F. (2018). Bayesian Distributed Stochastic Gradient Descent. Advances in Neural Information Processing Systems, 6378–6388. PDF
Teng, M., & Wood, F. (2018). Bayesian Distributed Stochastic Gradient Descent. Advances in Neural Information Processing Systems, 6378–6388. PDF@inproceedings{teng2018bayesian, title = {Bayesian Distributed Stochastic Gradient Descent}, author = {Teng, Michael and Wood, Frank}, booktitle = {Advances in Neural Information Processing Systems}, pages = {6378--6388}, year = {2018} } -
 Webb, S., Golinski, A., Zinkov, R., Narayanaswamy, S., Rainforth, T., Teh, Y. W., & Wood, F. (2018). Faithful inversion of generative models for effective amortized inference. Advances in Neural Information Processing Systems, 3070–3080. PDF
Webb, S., Golinski, A., Zinkov, R., Narayanaswamy, S., Rainforth, T., Teh, Y. W., & Wood, F. (2018). Faithful inversion of generative models for effective amortized inference. Advances in Neural Information Processing Systems, 3070–3080. PDF@inproceedings{webb2018faithful, title = {Faithful inversion of generative models for effective amortized inference}, author = {Webb, Stefan and Golinski, Adam and Zinkov, Rob and Narayanaswamy, Siddharth and Rainforth, Tom and Teh, Yee Whye and Wood, Frank}, booktitle = {Advances in Neural Information Processing Systems}, pages = {3070--3080}, year = {2018} } -
 Rainforth, T., Cornish, R., Yang, H., Warrington, A., & Wood, F. (2018). On Nesting Monte Carlo Estimators. ICML. PDF
Rainforth, T., Cornish, R., Yang, H., Warrington, A., & Wood, F. (2018). On Nesting Monte Carlo Estimators. ICML. PDF@inproceedings{rainforth2018nesting, title = {On Nesting Monte Carlo Estimators}, author = {Rainforth, Tom and Cornish, Robert and Yang, Hongseok and Warrington, Andrew and Wood, Frank}, booktitle = {ICML}, year = {2018} } -
 Rainforth, T., Kosiorek, A. R., Le, T. A., Maddison, C. J., Igl, M., Wood, F., & Teh, Y. W. (2018). Tighter variational bounds are not necessarily better. ICML. PDF
Rainforth, T., Kosiorek, A. R., Le, T. A., Maddison, C. J., Igl, M., Wood, F., & Teh, Y. W. (2018). Tighter variational bounds are not necessarily better. ICML. PDF@inproceedings{rainforth2018tighter, title = {Tighter variational bounds are not necessarily better}, author = {Rainforth, Tom and Kosiorek, Adam R and Le, Tuan Anh and Maddison, Chris J and Igl, Maximilian and Wood, Frank and Teh, Yee Whye}, booktitle = {ICML}, year = {2018} } -
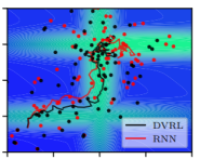 Igl, M., Zintgraf, L., Le, T. A., Wood, F., & Whiteson, S. (2018). Deep Variational Reinforcement Learning for POMDPs. ICML. PDF
Igl, M., Zintgraf, L., Le, T. A., Wood, F., & Whiteson, S. (2018). Deep Variational Reinforcement Learning for POMDPs. ICML. PDF@inproceedings{igl2018deep, title = {Deep Variational Reinforcement Learning for POMDPs}, author = {Igl, Maximilian and Zintgraf, Luisa and Le, Tuan Anh and Wood, Frank and Whiteson, Shimon}, booktitle = {ICML}, year = {2018} } -
 Siddarth, N., Paige, B., Desmaison, A., van de Meent, J. W., Wood, F., Goodman, N., Kohli, P., & Torr, P. H. S. (2017). Learning Disentangled Representations with Semi-Supervised Deep Generative Models. NeurIPS. PDF
Siddarth, N., Paige, B., Desmaison, A., van de Meent, J. W., Wood, F., Goodman, N., Kohli, P., & Torr, P. H. S. (2017). Learning Disentangled Representations with Semi-Supervised Deep Generative Models. NeurIPS. PDF@inproceedings{iffsidnips2017, title = {Learning Disentangled Representations with Semi-Supervised Deep Generative Models}, author = {Siddarth, N. and Paige, B. and Desmaison, A. and van~de~Meent, J.W. and Wood, F. and Goodman, N. and Kohli, P. and Torr, P.H.S}, booktitle = {NeurIPS}, year = {2017} } -
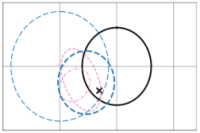 Le, T. A., Baydin, A. G., Zinkov, R., & Wood, F. (2017). Using Synthetic Data to Train Neural Networks is Model-Based Reasoning. 30th International Joint Conference on Neural Networks, May 14–19, 2017, Anchorage, AK, USA. PDF
Le, T. A., Baydin, A. G., Zinkov, R., & Wood, F. (2017). Using Synthetic Data to Train Neural Networks is Model-Based Reasoning. 30th International Joint Conference on Neural Networks, May 14–19, 2017, Anchorage, AK, USA. PDF@inproceedings{le2016synthetic, author = {Le, Tuan Anh and Baydin, Atılım Güneş and Zinkov, Robert and Wood, Frank}, booktitle = {30th International Joint Conference on Neural Networks, May 14--19, 2017, Anchorage, AK, USA}, title = {Using Synthetic Data to Train Neural Networks is Model-Based Reasoning}, year = {2017} } -
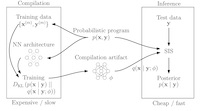 Le, T. A., Baydin, A. G., & Wood, F. (2017). Inference Compilation and Universal Probabilistic Programming. 20th International Conference on Artificial Intelligence and Statistics, April 20–22, 2017, Fort Lauderdale, FL, USA. PDF
Le, T. A., Baydin, A. G., & Wood, F. (2017). Inference Compilation and Universal Probabilistic Programming. 20th International Conference on Artificial Intelligence and Statistics, April 20–22, 2017, Fort Lauderdale, FL, USA. PDF@inproceedings{le2016inference, author = {Le, Tuan Anh and Baydin, Atılım Güneş and Wood, Frank}, booktitle = {20th International Conference on Artificial Intelligence and Statistics, April 20--22, 2017, Fort Lauderdale, FL, USA}, title = {Inference {C}ompilation and {U}niversal {P}robabilistic {P}rogramming}, year = {2017}, file = {../assets/pdf/le2016inference.pdf}, link = {https://arxiv.org/abs/1610.09900} } -
 Rainforth, T., Le, T. A., van de Meent, J.-W., Osborne, M. A., & Wood, F. (2016). Bayesian Optimization for Probabilistic Programs. Advances in Neural Information Processing Systems (NeurIPS), 280–288. PDF
Rainforth, T., Le, T. A., van de Meent, J.-W., Osborne, M. A., & Wood, F. (2016). Bayesian Optimization for Probabilistic Programs. Advances in Neural Information Processing Systems (NeurIPS), 280–288. PDF@inproceedings{rainforth-nips-2016, title = {{B}ayesian {O}ptimization for {P}robabilistic {P}rograms}, author = {Rainforth, Tom and Le, Tuan Anh and van de Meent, Jan-Willem and Osborne, Michael A and Wood, Frank}, booktitle = {Advances in Neural Information Processing Systems (NeurIPS)}, year = {2016}, pages = {280--288} } -
 Dhir, N., Perov, Y., & Wood, F. (2016). Nonparametric Bayesian Models for Unsupervised Activity Recognition and Tracking. IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS 2016). PDF
Dhir, N., Perov, Y., & Wood, F. (2016). Nonparametric Bayesian Models for Unsupervised Activity Recognition and Tracking. IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS 2016). PDF@inproceedings{Dhir-IROS-2016, author = {Dhir, Neil and Perov, Yura and Wood, Frank}, title = {Nonparametric Bayesian Models for Unsupervised Activity Recognition and Tracking}, booktitle = {IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS 2016)}, year = {2016} } -
 Staton, S., Yang, H., Heunen, C., Kammar, O., & Wood, F. (2016). Semantics for probabilistic programming: higher-order functions, continuous distributions, and soft constraints. Thirty-First Annual ACM/IEEE Symposium on Logic In Computer Science. PDF
Staton, S., Yang, H., Heunen, C., Kammar, O., & Wood, F. (2016). Semantics for probabilistic programming: higher-order functions, continuous distributions, and soft constraints. Thirty-First Annual ACM/IEEE Symposium on Logic In Computer Science. PDF@inproceedings{staton2016semanticslics, title = {Semantics for probabilistic programming: higher-order functions, continuous distributions, and soft constraints}, author = {Staton, S. and Yang, H. and Heunen, C. and Kammar, O. and Wood, F.}, booktitle = {Thirty-First Annual ACM/IEEE Symposium on Logic In Computer Science}, year = {2016} } -
 Perov, Y., & Wood, F. (2016). Automatic Sampler Discovery via Probabilistic Programming and Approximate Bayesian Computation. Artificial General Intelligence, 262–273. PDF
Perov, Y., & Wood, F. (2016). Automatic Sampler Discovery via Probabilistic Programming and Approximate Bayesian Computation. Artificial General Intelligence, 262–273. PDF@inproceedings{perov-agi-2016, author = {Perov, Y. and Wood, F.}, booktitle = {Artificial General Intelligence}, title = {Automatic Sampler Discovery via Probabilistic Programming and Approximate {B}ayesian Computation}, pages = {262--273}, year = {2016} } -
 Paige, B., Sejdinovic, D., & Wood, F. (2016). Super-sampling with Reservoir. Proceedings of the 32nd Annual Conference on Uncertainty in Artificial Intelligence (UAI-2016). PDF
Paige, B., Sejdinovic, D., & Wood, F. (2016). Super-sampling with Reservoir. Proceedings of the 32nd Annual Conference on Uncertainty in Artificial Intelligence (UAI-2016). PDF@inproceedings{paige2016supersampling, author = {Paige, Brooks and Sejdinovic, Dino and Wood, Frank}, title = {Super-sampling with Reservoir}, booktitle = {Proceedings of the 32nd Annual Conference on Uncertainty in Artificial Intelligence (UAI-2016)}, publisher = {{AUAI Press}}, year = {2016} } -
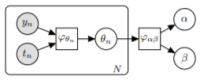 Paige, B., & Wood, F. (2016). Inference Networks for Sequential Monte Carlo in Graphical Models. Proceedings of the 33rd International Conference on Machine Learning, 48. PDF
Paige, B., & Wood, F. (2016). Inference Networks for Sequential Monte Carlo in Graphical Models. Proceedings of the 33rd International Conference on Machine Learning, 48. PDF@inproceedings{paige2016inference, title = {Inference Networks for Sequential {M}onte {C}arlo in Graphical Models}, author = {Paige, B. and Wood, F.}, booktitle = {Proceedings of the 33rd International Conference on Machine Learning}, series = {JMLR}, volume = {48}, year = {2016} } -
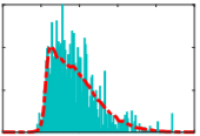 Rainforth, T., Naesseth, C. A., Lindsten, F., Paige, B., van de Meent, J. W., Doucet, A., & Wood, F. (2016). Interacting Particle Markov Chain Monte Carlo. Proceedings of the 33rd International Conference on Machine Learning, 48. PDF
Rainforth, T., Naesseth, C. A., Lindsten, F., Paige, B., van de Meent, J. W., Doucet, A., & Wood, F. (2016). Interacting Particle Markov Chain Monte Carlo. Proceedings of the 33rd International Conference on Machine Learning, 48. PDF@inproceedings{rainforth2016interacting, title = {Interacting Particle {M}arkov Chain {M}onte {C}arlo}, author = {Rainforth, T. and Naesseth, C.A. and Lindsten, F. and Paige, B. and van de Meent, J.W. and Doucet, A. and Wood, F.}, booktitle = {Proceedings of the 33rd International Conference on Machine Learning}, series = {JMLR}, volume = {48}, year = {2016} } -
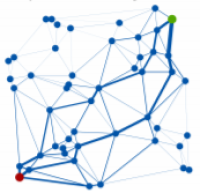 van de Meent, J. W., Tolpin, D., Paige, B., & Wood, F. (2016). Black-Box Policy Search with Probabilistic Programs. Proceedings of the Nineteenth International Conference on Artificial Intelligence and Statistics, 1195–1204. PDF
van de Meent, J. W., Tolpin, D., Paige, B., & Wood, F. (2016). Black-Box Policy Search with Probabilistic Programs. Proceedings of the Nineteenth International Conference on Artificial Intelligence and Statistics, 1195–1204. PDF@inproceedings{vandemeent16, author = {van de Meent, J.~W. and Tolpin, D. and Paige, B. and Wood, F.}, booktitle = {Proceedings of the Nineteenth International Conference on Artificial Intelligence and Statistics}, title = {Black-Box Policy Search with Probabilistic Programs}, pages = {1195--1204}, year = {2016} } -
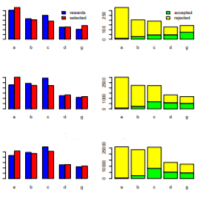 Tolpin, D., van de Meent, J.-W., & Paige, F., Brooks Wood. (2015). Output-Sensitive Adaptive Metropolis-Hastings for Probabilistic Programs. ECML PKDD 2015. PDF
Tolpin, D., van de Meent, J.-W., & Paige, F., Brooks Wood. (2015). Output-Sensitive Adaptive Metropolis-Hastings for Probabilistic Programs. ECML PKDD 2015. PDF@inproceedings{Tolpin-ECMLPKDD-2015, author = {Tolpin, David and van de Meent, Jan-Willem and Paige, Brooks Wood, Frank}, booktitle = {ECML PKDD 2015}, title = {{Output-Sensitive Adaptive Metropolis-Hastings for Probabilistic Programs}}, year = {2015} } -
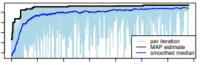 Tolpin, D., & Wood, F. (2015). Maximum a Posteriori Estimation by Search in Probabilistic Programs. Eighth Annual Symposium on Combinatorial Search, 201–205. PDF
Tolpin, D., & Wood, F. (2015). Maximum a Posteriori Estimation by Search in Probabilistic Programs. Eighth Annual Symposium on Combinatorial Search, 201–205. PDF@inproceedings{Tolpin-SOCS-2015, title = {Maximum a Posteriori Estimation by Search in Probabilistic Programs}, author = {Tolpin, David and Wood, Frank}, booktitle = {Eighth Annual Symposium on Combinatorial Search}, pages = {201-205}, year = {2015} } -
 Tolpin, D., van de Meent, J.-W., & Wood, F. (2015). Probabilistic Programming in Anglican. In A. Bifet, M. May, B. Zadrozny, R. Gavalda, D. Pedreschi, F. Bonchi, J. Cardoso, & M. Spiliopoulou (Eds.), Machine Learning and Knowledge Discovery in Databases (Vol. 9286, pp. 308–311). Springer International Publishing. https://doi.org/10.1007/978-3-319-23461-8_36 PDF
Tolpin, D., van de Meent, J.-W., & Wood, F. (2015). Probabilistic Programming in Anglican. In A. Bifet, M. May, B. Zadrozny, R. Gavalda, D. Pedreschi, F. Bonchi, J. Cardoso, & M. Spiliopoulou (Eds.), Machine Learning and Knowledge Discovery in Databases (Vol. 9286, pp. 308–311). Springer International Publishing. https://doi.org/10.1007/978-3-319-23461-8_36 PDF@incollection{Tolpin-ECML-Anglican-DemoTrack, year = {2015}, isbn = {978-3-319-23460-1}, booktitle = {Machine Learning and Knowledge Discovery in Databases}, volume = {9286}, series = {Lecture Notes in Computer Science}, editor = {Bifet, Albert and May, Michael and Zadrozny, Bianca and Gavalda, Ricard and Pedreschi, Dino and Bonchi, Francesco and Cardoso, Jaime and Spiliopoulou, Myra}, doi = {10.1007/978-3-319-23461-8_36}, title = {Probabilistic Programming in Anglican}, url = {http://dx.doi.org/10.1007/978-3-319-23461-8_36}, publisher = {Springer International Publishing}, keywords = {Probabilistic programming}, author = {Tolpin, David and van de Meent, Jan-Willem and Wood, Frank}, pages = {308-311}, language = {English} } -
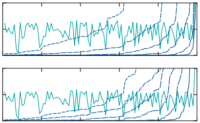 van de Meent, J.-W., Yang, H., Mansinghka, V., & Wood, F. (2015). Particle Gibbs with Ancestor Sampling for Probabilistic Programs. Artificial Intelligence and Statistics. PDF
van de Meent, J.-W., Yang, H., Mansinghka, V., & Wood, F. (2015). Particle Gibbs with Ancestor Sampling for Probabilistic Programs. Artificial Intelligence and Statistics. PDF@inproceedings{vandeMeent-AISTATS-2015, archiveprefix = {arXiv}, arxivid = {1501.06769}, author = {van de Meent, Jan-Willem and Yang, Hongseok and Mansinghka, Vikash and Wood, Frank}, booktitle = {Artificial Intelligence and Statistics}, eprint = {1501.06769}, title = {{Particle Gibbs with Ancestor Sampling for Probabilistic Programs}}, year = {2015} } -
 Paige, B., Wood, F., Doucet, A., & Teh, Y. W. (2014). Asynchronous Anytime Sequential Monte Carlo. Advances in Neural Information Processing Systems, 3410–3418. PDF
Paige, B., Wood, F., Doucet, A., & Teh, Y. W. (2014). Asynchronous Anytime Sequential Monte Carlo. Advances in Neural Information Processing Systems, 3410–3418. PDF@inproceedings{Paige-NIPS-2014, author = {Paige, B. and Wood, F. and Doucet, A. and Teh, Y.W.}, booktitle = {Advances in Neural Information Processing Systems}, title = {Asynchronous Anytime Sequential Monte Carlo}, pages = {3410--3418}, year = {2014} } -
 Dhir, N., & Wood, F. (2014). Improved Activity Recognition via Kalman Smoothing and Multiclass Linear Discriminant Analysis. Proceedings of the 36th IEEE Conference on Engineering in Medicine and Biological Systems. PDF
Dhir, N., & Wood, F. (2014). Improved Activity Recognition via Kalman Smoothing and Multiclass Linear Discriminant Analysis. Proceedings of the 36th IEEE Conference on Engineering in Medicine and Biological Systems. PDF@inproceedings{Dhir-EMBS-2014, author = {Dhir, N. and Wood, F.}, booktitle = {Proceedings of the 36th IEEE Conference on Engineering in Medicine and Biological Systems}, title = {Improved Activity Recognition via Kalman Smoothing and Multiclass Linear Discriminant Analysis}, year = {2014} } -
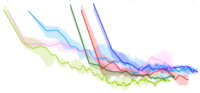 Paige, B., & Wood, F. (2014). A Compilation Target for Probabilistic Programming Languages. JMLR; ICML 2014, 1935–1943. PDF
Paige, B., & Wood, F. (2014). A Compilation Target for Probabilistic Programming Languages. JMLR; ICML 2014, 1935–1943. PDF@inproceedings{Paige-ICML-2014, title = {A Compilation Target for Probabilistic Programming Languages}, author = {Paige, Brooks and Wood, Frank}, booktitle = {JMLR; ICML 2014}, pages = {1935--1943}, year = {2014} } -
 Wood, F., van de Meent, J. W., & Mansinghka, V. (2014). A New Approach to Probabilistic Programming Inference. Artificial Intelligence and Statistics, 1024–1032. PDF
Wood, F., van de Meent, J. W., & Mansinghka, V. (2014). A New Approach to Probabilistic Programming Inference. Artificial Intelligence and Statistics, 1024–1032. PDF@inproceedings{Wood-AISTATS-2014, author = {Wood, F. and van de Meent, J. W. and Mansinghka, V.}, booktitle = {Artificial Intelligence and Statistics}, title = {A New Approach to Probabilistic Programming Inference}, pages = {1024--1032}, year = {2014} } -
 Neiswanger, W., Wood, F., & Xing, E. (2014). The Dependent Dirichlet Process Mixture of Objects for Detection-free Tracking and Object Modeling. Artificial Intelligence and Statistics, 660–668. PDF
Neiswanger, W., Wood, F., & Xing, E. (2014). The Dependent Dirichlet Process Mixture of Objects for Detection-free Tracking and Object Modeling. Artificial Intelligence and Statistics, 660–668. PDF@inproceedings{Neiswanger-AISTATS-2014, author = {Neiswanger, W. and Wood, F. and Xing, E.}, booktitle = {Artificial Intelligence and Statistics}, title = { The Dependent {D}irichlet Process Mixture of Objects for Detection-free Tracking and Object Modeling}, pages = {660--668}, year = {2014} } -
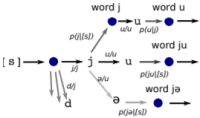 Elsner, M., Goldwater, S., Feldman, N., & Wood, F. (2013). A Joint Learning Model of Word Segmentation, Lexical Acquisition, and Phonetic Variability. Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, 42–54. PDF
Elsner, M., Goldwater, S., Feldman, N., & Wood, F. (2013). A Joint Learning Model of Word Segmentation, Lexical Acquisition, and Phonetic Variability. Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, 42–54. PDF@inproceedings{Elsner-EMNLP-2013, author = {Elsner, M. and Goldwater, S. and Feldman, N. and Wood, F.}, title = {A Joint Learning Model of Word Segmentation, Lexical Acquisition, and Phonetic Variability}, booktitle = {Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing}, month = oct, year = {2013}, address = {Seattle, Washington, USA}, publisher = {Association for Computational Linguistics}, pages = {42--54} } -
 van de Meent, J. W., Bronson, J. E., Jr., R. L. G., Wood, F., & Wiggins, C. H. (2013). Learning biochemical kinetic models from single-molecule data with hierarchically-coupled hidden Markov models. International Conference on Machine Learning, 361–369. PDF
van de Meent, J. W., Bronson, J. E., Jr., R. L. G., Wood, F., & Wiggins, C. H. (2013). Learning biochemical kinetic models from single-molecule data with hierarchically-coupled hidden Markov models. International Conference on Machine Learning, 361–369. PDF@inproceedings{vandeMeent-ICML-2013, author = {van de Meent, J.W. and Bronson, J. E. and Jr., R. L. Gonzalez and Wood, F. and Wiggins, C. H.}, booktitle = {International Conference on Machine Learning}, title = {Learning biochemical kinetic models from single-molecule data with hierarchically-coupled hidden {M}arkov models}, year = {2013}, pages = {361--369} } -
 Smith, C., Wood, F., & Paninski, L. (2012). Low rank continuous-space graphical models. Artificial Intelligence and Statistics, 1064–1072. PDF
Smith, C., Wood, F., & Paninski, L. (2012). Low rank continuous-space graphical models. Artificial Intelligence and Statistics, 1064–1072. PDF@inproceedings{Smith-AISTATS-2012, author = {Smith, C. and Wood, F. and Paninski, L.}, booktitle = {Artificial Intelligence and Statistics}, title = { Low rank continuous-space graphical models}, pages = {1064--1072}, year = {2012} } -
 Perotte, A., Bartlett, N., Elhadad, N., & Wood, F. (2011). Hierarchically Supervised Latent Dirichlet Allocation. Advances in Neural Information Processing Systems, 2609–2617. PDF
Perotte, A., Bartlett, N., Elhadad, N., & Wood, F. (2011). Hierarchically Supervised Latent Dirichlet Allocation. Advances in Neural Information Processing Systems, 2609–2617. PDF@inproceedings{Perotte-NIPS-2011, author = {Perotte, A. and Bartlett, N. and Elhadad, N. and Wood, F.}, booktitle = {Advances in Neural Information Processing Systems}, title = {Hierarchically Supervised Latent {D}irichlet Allocation}, year = {2011}, pages = {2609--2617} } -
 Bartlett, N., & Wood, F. (2011). Deplump for Streaming Data. Data Compression Conference, 363–372. PDF
Bartlett, N., & Wood, F. (2011). Deplump for Streaming Data. Data Compression Conference, 363–372. PDF@inproceedings{Bartlett-DCC-2011, author = {Bartlett, N. and Wood, F.}, booktitle = {Data Compression Conference}, title = {Deplump for Streaming Data}, pages = {363--372}, year = {2011} } -
 Pfau, D., Bartlett, N., & Wood, F. (2011). Probabilistic Deterministic Infinite Automata. Advances in Neural Information Processing Systems, 1930–1938. PDF
Pfau, D., Bartlett, N., & Wood, F. (2011). Probabilistic Deterministic Infinite Automata. Advances in Neural Information Processing Systems, 1930–1938. PDF@inproceedings{Pfau-NIPS-2011, author = {Pfau, D. and Bartlett, N. and Wood, F.}, booktitle = {Advances in Neural Information Processing Systems}, title = {Probabilistic Deterministic Infinite Automata}, year = {2011}, pages = {1930--1938} } -
 Bartlett, N., Pfau, D., & Wood, F. (2010). Forgetting Counts : Constant Memory Inference for a Dependent Hierarchical Pitman-Yor Process. Proceedings of the 26th International Conference on Machine Learning, 63–70. PDF
Bartlett, N., Pfau, D., & Wood, F. (2010). Forgetting Counts : Constant Memory Inference for a Dependent Hierarchical Pitman-Yor Process. Proceedings of the 26th International Conference on Machine Learning, 63–70. PDF@inproceedings{Bartlett-ICML-2010, author = {Bartlett, N. and Pfau, D. and Wood, F.}, booktitle = {Proceedings of the 26th International Conference on Machine Learning}, title = {Forgetting Counts : Constant Memory Inference for a Dependent Hierarchical {P}itman-{Y}or Process}, year = {2010}, pages = {63--70} } -
 Gasthaus, J., Wood, F., & Teh, Y. W. (2010). Lossless compression based on the Sequence Memoizer . Data Compression Conference, 337–345. PDF
Gasthaus, J., Wood, F., & Teh, Y. W. (2010). Lossless compression based on the Sequence Memoizer . Data Compression Conference, 337–345. PDF@inproceedings{Gasthaus-DCC-2010, author = {Gasthaus, J. and Wood, F. and Teh, Y.W.}, booktitle = {Data Compression Conference}, pages = {337--345}, title = {Lossless compression based on the {S}equence {M}emoizer }, year = {2010} } -
 Wood, F., Archambeau, C., Gasthaus, J., James, L., & Teh, Y. W. (2009). A Stochastic Memoizer for Sequence Data . Proceedings of the 26th International Conference on Machine Learning, 1129–1136. PDF
Wood, F., Archambeau, C., Gasthaus, J., James, L., & Teh, Y. W. (2009). A Stochastic Memoizer for Sequence Data . Proceedings of the 26th International Conference on Machine Learning, 1129–1136. PDF@inproceedings{Wood-ICML-2009, author = {Wood, F. and Archambeau, C. and Gasthaus, J. and James, L. and Teh, Y.W.}, booktitle = {Proceedings of the 26th International Conference on Machine Learning}, pages = {1129--1136}, title = {A Stochastic Memoizer for Sequence Data }, year = {2009} } -
 Wood, F., & Teh, Y. W. (2009). A Hierarchical Nonparametric Bayesian Approach to Statistical Language Model Domain Adaptation. Artificial Intelligence and Statistics, 607–614. PDF
Wood, F., & Teh, Y. W. (2009). A Hierarchical Nonparametric Bayesian Approach to Statistical Language Model Domain Adaptation. Artificial Intelligence and Statistics, 607–614. PDF@inproceedings{Wood-AISTATS-2009, author = {Wood, F. and Teh, Y.W.}, booktitle = {Artificial Intelligence and Statistics}, pages = {607--614}, title = { A Hierarchical Nonparametric {B}ayesian Approach to Statistical Language Model Domain Adaptation}, year = {2009} } -
 Gasthaus, J., Wood, F., Görür, D., & Teh, Y. W. (2009). Dependent Dirichlet Process Spike Sorting. Advances in Neural Information Processing Systems, 497–504. PDF
Gasthaus, J., Wood, F., Görür, D., & Teh, Y. W. (2009). Dependent Dirichlet Process Spike Sorting. Advances in Neural Information Processing Systems, 497–504. PDF@inproceedings{Gasthaus-NIPS-2009, author = {Gasthaus, J. and Wood, F. and G\"{o}r\"{u}r, D. and Teh, Y.W.}, booktitle = {Advances in Neural Information Processing Systems}, pages = {497--504}, title = {Dependent {D}irichlet Process Spike Sorting}, year = {2009} } -
 Berkes, P., Pillow, J. W., & Wood, F. (2009). Characterizing neural dependencies with Poisson copula models. Advances in Neural Information Processing Systems, 129–136. PDF
Berkes, P., Pillow, J. W., & Wood, F. (2009). Characterizing neural dependencies with Poisson copula models. Advances in Neural Information Processing Systems, 129–136. PDF@inproceedings{Berkes-NIPS-2009, author = {Berkes, P. and Pillow, J.W. and Wood, F.}, booktitle = {Advances in Neural Information Processing Systems}, pages = {129 -- 136}, title = {Characterizing neural dependencies with {P}oisson copula models}, year = {2009} } -
 Wood, F., & Griffiths, T. L. (2006). Particle Filtering for Non-Parametric Bayesian Matrix Factorization. Advances in Neural Information Processing Systems, 1513–1520. PDF
Wood, F., & Griffiths, T. L. (2006). Particle Filtering for Non-Parametric Bayesian Matrix Factorization. Advances in Neural Information Processing Systems, 1513–1520. PDF@inproceedings{Wood-NIPS-2006, author = {Wood, F. and Griffiths, T. L.}, booktitle = {Advances in Neural Information Processing Systems}, pages = {1513--1520}, title = {Particle Filtering for Non-Parametric {B}ayesian Matrix Factorization}, year = {2006} } -
 Wood, F., Goldwater, S., & Black, M. J. (2006). A Non-Parametric Bayesian Approach to Spike Sorting. Proceedings of the 28th IEEE Conference on Engineering in Medicine and Biological Systems, 1165–1169. PDF
Wood, F., Goldwater, S., & Black, M. J. (2006). A Non-Parametric Bayesian Approach to Spike Sorting. Proceedings of the 28th IEEE Conference on Engineering in Medicine and Biological Systems, 1165–1169. PDF@inproceedings{Wood-EMBS-2006, author = {Wood, F. and Goldwater, S. and Black, M. J.}, booktitle = {Proceedings of the 28th IEEE Conference on Engineering in Medicine and Biological Systems}, pages = {1165--1169}, title = {A Non-Parametric {B}ayesian Approach to Spike Sorting}, year = {2006} } -
 Wood, F., Griffiths, T. L., & Ghahramani, Z. (2006). A Non-Parametric Bayesian Method for Inferring Hidden Causes. Proceedings of the 22nd Conference on Uncertainty in Artificial Intelligence , 536–543. PDF
Wood, F., Griffiths, T. L., & Ghahramani, Z. (2006). A Non-Parametric Bayesian Method for Inferring Hidden Causes. Proceedings of the 22nd Conference on Uncertainty in Artificial Intelligence , 536–543. PDF@inproceedings{Wood-UAI-2006, author = {Wood, F. and Griffiths, T. L. and Ghahramani, Z.}, booktitle = {Proceedings of the 22nd Conference on Uncertainty in Artificial Intelligence }, pages = {536--543}, title = {A Non-Parametric {B}ayesian Method for Inferring Hidden Causes}, year = {2006} } -
 Kim, S. P., Wood, F., & Black, M. J. (2006). Statistical Analysis of the Non-stationarity of Neural Population Codes. The First IEEE / RAS-EMBS International Conference on Biomedical Robotics and Biomechatronics, 259–299. PDF
Kim, S. P., Wood, F., & Black, M. J. (2006). Statistical Analysis of the Non-stationarity of Neural Population Codes. The First IEEE / RAS-EMBS International Conference on Biomedical Robotics and Biomechatronics, 259–299. PDF@inproceedings{Kim-BioRob-2006, author = {Kim, S. P. and Wood, F. and Black, M. J.}, booktitle = {The First IEEE / RAS-EMBS International Conference on Biomedical Robotics and Biomechatronics}, pages = {259--299}, title = {Statistical Analysis of the Non-stationarity of Neural Population Codes}, year = {2006} } -
 Wood, F., Roth, S., & Black, M. J. (2005). Modeling neural population spiking activity with Gibbs distributions. Advances in Neural Information Processing Systems, 1527–1544. PDF
Wood, F., Roth, S., & Black, M. J. (2005). Modeling neural population spiking activity with Gibbs distributions. Advances in Neural Information Processing Systems, 1527–1544. PDF@inproceedings{Wood-NIPS-2005, author = {Wood, F. and Roth, S. and Black, M. J.}, booktitle = {Advances in Neural Information Processing Systems}, pages = {1527--1544}, title = {Modeling neural population spiking activity with {G}ibbs distributions}, year = {2005} } -
 Wood, F., Prabhat, Donoghue, J. P., & Black, M. J. (2005). Inferring Attentional State and Kinematics from Motor Cortical Firing Rates. Proceedings of the 27th IEEE Conference on Engineering in Medicine and Biological Systems, 149–152. PDF
Wood, F., Prabhat, Donoghue, J. P., & Black, M. J. (2005). Inferring Attentional State and Kinematics from Motor Cortical Firing Rates. Proceedings of the 27th IEEE Conference on Engineering in Medicine and Biological Systems, 149–152. PDF@inproceedings{Wood-EMBS-2005, author = {Wood, F. and Prabhat and Donoghue, J. P. and Black, M. J.}, booktitle = {Proceedings of the 27th IEEE Conference on Engineering in Medicine and Biological Systems}, pages = {149--152}, title = {Inferring Attentional State and Kinematics from Motor Cortical Firing Rates}, year = {2005} } -
 Wood, F., Fellows, M., Donoghue, J. P., & Black, M. J. (2004). Automatic Spike Sorting for Neural Decoding. Proceedings of the 27th IEEE Conference on Engineering in Medicine and Biological Systems, 4126–4129. PDF
Wood, F., Fellows, M., Donoghue, J. P., & Black, M. J. (2004). Automatic Spike Sorting for Neural Decoding. Proceedings of the 27th IEEE Conference on Engineering in Medicine and Biological Systems, 4126–4129. PDF@inproceedings{Wood-EMBS-2004, author = {Wood, F. and Fellows, M. and Donoghue, J. P. and Black, M. J.}, booktitle = {Proceedings of the 27th IEEE Conference on Engineering in Medicine and Biological Systems}, pages = {4126--4129}, title = {Automatic Spike Sorting for Neural Decoding}, year = {2004} }
Journal
-
Lioutas, V., Ścibior, A., & Wood, F. (2022). TITRATED: Learned Human Driving Behavior without Infractions via Amortized Inference. Transactions in Machine Learning Research (TMLR).
@article{lioutas2022titrated, title = {{TITRATED}: Learned Human Driving Behavior without Infractions via Amortized Inference}, author = {Lioutas, Vasileios and {\'S}cibior, Adam and Wood, Frank}, journal = {Transactions in Machine Learning Research (TMLR)}, year = {2022} } -
Poole, D., & Wood, F. (2022). Probabilistic Programming Languages: Independent Choices and Deterministic Systems. In Probabilistic and Causal Inference: The Works of Judea Pearl (1st ed., pp. 691–712). Association for Computing Machinery.
@inbook{10.1145/3501714.3501753, author = {Poole, David and Wood, Frank}, title = {Probabilistic Programming Languages: Independent Choices and Deterministic Systems}, year = {2022}, isbn = {9781450395861}, publisher = {Association for Computing Machinery}, address = {New York, NY, USA}, edition = {1}, booktitle = {Probabilistic and Causal Inference: The Works of Judea Pearl}, pages = {691–712}, numpages = {22} } -
 Caron, F., Neiswanger, W., Wood, F., Doucet, A., & Davy, M. (2017). Generalized Pólya Urn for Time-Varying Pitman-Yor Processes. JMLR, 1–32. PDF
Caron, F., Neiswanger, W., Wood, F., Doucet, A., & Davy, M. (2017). Generalized Pólya Urn for Time-Varying Pitman-Yor Processes. JMLR, 1–32. PDF@article{Caron-2017-JMLR, title = {Generalized {P}\'olya Urn for Time-Varying {P}itman-{Y}or Processes}, author = {Caron, Francois and Neiswanger, Willie and Wood, Frank and Doucet, Arnaud and Davy, Manuel}, journal = {JMLR}, pages = {1--32}, year = {2017} } -
 Perotte, A., Pivovarov, R., Natarajan, K., Weiskopf, N., Wood, F., & Elhadad, N. (2014). Diagnosis code assignment: models and evaluation metrics. Journal of the American Medical Informatics Association, 21(2), 231–237. PDF
Perotte, A., Pivovarov, R., Natarajan, K., Weiskopf, N., Wood, F., & Elhadad, N. (2014). Diagnosis code assignment: models and evaluation metrics. Journal of the American Medical Informatics Association, 21(2), 231–237. PDF@article{Perotte-JAMIA-2013, title = {Diagnosis code assignment: models and evaluation metrics}, author = {Perotte, Adler and Pivovarov, Rimma and Natarajan, Karthik and Weiskopf, Nicole and Wood, Frank and Elhadad, No{\'e}mie}, journal = {Journal of the American Medical Informatics Association}, volume = {21}, number = {2}, pages = {231--237}, year = {2014}, publisher = {BMJ Publishing Group Ltd} } -
 Doshi-Velez, F., Pfau, D., Wood, F., & Roy, N. (2013). Bayesian Nonparametric Methods for Partially-Observable Reinforcement Learning. IEEE Transactions on Pattern Analysis and Machine Intelligence, 99, 1. PDF
Doshi-Velez, F., Pfau, D., Wood, F., & Roy, N. (2013). Bayesian Nonparametric Methods for Partially-Observable Reinforcement Learning. IEEE Transactions on Pattern Analysis and Machine Intelligence, 99, 1. PDF@article{Doshi-Velez-TPAMI-2013, author = {Doshi-Velez, F. and Pfau, D. and Wood, F. and Roy, N.}, title = {Bayesian Nonparametric Methods for Partially-Observable Reinforcement Learning}, journal = {IEEE Transactions on Pattern Analysis and Machine Intelligence}, volume = {99}, year = {2013}, pages = {1}, publisher = {IEEE Computer Society} } -
 Dewar, M., Wiggins, C., & Wood, F. (2012). Inference in Hidden Markov Models with Explicit State Duration Distributions. Signal Processing Letters, IEEE, 19(4), 235–238. PDF
Dewar, M., Wiggins, C., & Wood, F. (2012). Inference in Hidden Markov Models with Explicit State Duration Distributions. Signal Processing Letters, IEEE, 19(4), 235–238. PDF@article{Dewar-IEEE-2012, title = {Inference in Hidden {M}arkov Models with Explicit State Duration Distributions}, author = {Dewar, M. and Wiggins, C. and Wood, F.}, journal = {Signal Processing Letters, IEEE}, volume = {19}, number = {4}, pages = {235--238}, year = {2012} } -
 Wood, F., Gasthaus, J., Archambeau, C., James, L., & Teh, Y. W. (2011). The Sequence Memoizer. Communications of the ACM, 54(2), 91–98. PDF
Wood, F., Gasthaus, J., Archambeau, C., James, L., & Teh, Y. W. (2011). The Sequence Memoizer. Communications of the ACM, 54(2), 91–98. PDF@article{Wood-CACM-2011, author = {Wood, F. and Gasthaus, J. and Archambeau, C. and James, L. and Teh, Y.W.}, title = {The Sequence Memoizer}, year = {2011}, volume = {54}, number = {2}, pages = {91--98}, journal = {Communications of the ACM}, publisher = {ACM Press} } -
 Wood, F., & Black, M. J. (2008). A Non-parametric Bayesian alternative to spike sorting. Journal of Neuroscience Methods, 173, 1–12. PDF
Wood, F., & Black, M. J. (2008). A Non-parametric Bayesian alternative to spike sorting. Journal of Neuroscience Methods, 173, 1–12. PDF@article{Wood-JNM-2008, author = {Wood, F. and Black, M. J.}, journal = {Journal of Neuroscience Methods}, pages = {1--12}, title = {A Non-parametric {B}ayesian alternative to spike sorting}, volume = {173}, year = {2008} } -
 Grollman, D. H., Jenkins, O. C., & Wood, F. (2006). Discovering natural kinds of robot sensory experiences in unstructured environments. Journal of Field Robotics, 23, 1077–1089. PDF
Grollman, D. H., Jenkins, O. C., & Wood, F. (2006). Discovering natural kinds of robot sensory experiences in unstructured environments. Journal of Field Robotics, 23, 1077–1089. PDF@article{Grollman-JFR-2006, author = {Grollman, D. H. and Jenkins, O. C. and Wood, F.}, journal = {Journal of Field Robotics}, pages = {1077--1089}, title = {Discovering natural kinds of robot sensory experiences in unstructured environments}, volume = {23}, year = {2006} } -
 Wood, F., Fellows, M., Vargas-Irwin, C., Black, M. J., & Donoghue, J. P. (2004). On the Variability of Manual Spike Sorting. IEEE Transactions in Biomedical Engineering, 51, 912–918. PDF
Wood, F., Fellows, M., Vargas-Irwin, C., Black, M. J., & Donoghue, J. P. (2004). On the Variability of Manual Spike Sorting. IEEE Transactions in Biomedical Engineering, 51, 912–918. PDF@article{Wood-TBME-2004, author = {Wood, F. and Fellows, M. and Vargas-Irwin, C. and Black, M. J. and Donoghue, J. P.}, journal = {IEEE Transactions in Biomedical Engineering}, pages = {912-918}, title = {On the Variability of Manual Spike Sorting}, volume = {51}, year = {2004} } -
Wood, F., Brown, D., Amidon, B., Alferness, J., Joseph, B., Gillilan, R. E., & Faerman, C. (1996). Windowing and Telecollaboration for Virtual Reality with Applications to the Study of a Tropical Disease. IEEE Computer Graphics and Applications, 16, 72–78.
@article{Wood-IEEE-CompGraphics-1996, author = {Wood, F. and Brown, D. and Amidon, B. and Alferness, J. and Joseph, B. and Gillilan, R. E. and Faerman, C.}, journal = {IEEE Computer Graphics and Applications}, pages = {72--78}, title = {Windowing and Telecollaboration for Virtual Reality with Applications to the Study of a Tropical Disease}, volume = {16}, year = {1996} } -
 Gillilan, R. E., & Wood, F. (1995). Visualization, Virtual Reality, and Animation within the Data Flow Model of Computing. Computer Graphics, 29, 55–58. PDF
Gillilan, R. E., & Wood, F. (1995). Visualization, Virtual Reality, and Animation within the Data Flow Model of Computing. Computer Graphics, 29, 55–58. PDF@article{Gillilan-CompGraphics-1995, author = {Gillilan, R. E. and Wood, F.}, journal = {Computer Graphics}, pages = {55--58}, title = {Visualization, Virtual Reality, and Animation within the Data Flow Model of Computing}, volume = {29}, year = {1995} }
Technical Reports
-
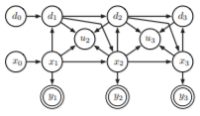
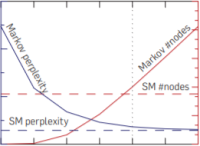
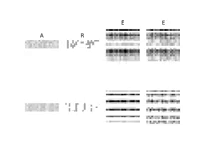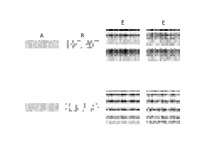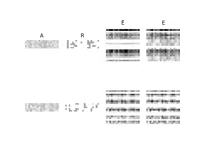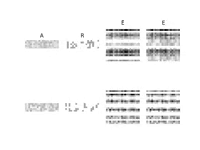 Weilbach, C., Harvey, W., & Wood, F. (2022). Graphically Structured Diffusion Models. ArXiv Preprint ArXiv:2210.11633. PDF
Weilbach, C., Harvey, W., & Wood, F. (2022). Graphically Structured Diffusion Models. ArXiv Preprint ArXiv:2210.11633. PDF@article{weilbach2022graphically, title = {Graphically Structured Diffusion Models}, author = {Weilbach, Christian and Harvey, William and Wood, Frank}, journal = {arXiv preprint arXiv:2210.11633}, year = {2022} } -
Zwartsenberg, B., Ścibior, A., Niedoba, M., Lioutas, V., Liu, Y., Sefas, J., Dabiri, S., Lavington, J. W., Campbell, T., & Wood, F. (2022). Conditional Permutation Invariant Flows. ArXiv Preprint ArXiv:2206.09021.
@article{zwartsenberg2022conditional, title = {Conditional Permutation Invariant Flows}, author = {Zwartsenberg, Berend and {\'S}cibior, Adam and Niedoba, Matthew and Lioutas, Vasileios and Liu, Yunpeng and Sefas, Justice and Dabiri, Setareh and Lavington, Jonathan Wilder and Campbell, Trevor and Wood, Frank}, journal = {arXiv preprint arXiv:2206.09021}, year = {2022} } -
 Lioutas, V., Lavington, J. W., Sefas, J., Niedoba, M., Liu, Y., Zwartsenberg, B., Dabiri, S., Wood, F., & Ścibior, A. (2022). Critic Sequential Monte Carlo. ArXiv Preprint ArXiv:2205.15460. PDF
Lioutas, V., Lavington, J. W., Sefas, J., Niedoba, M., Liu, Y., Zwartsenberg, B., Dabiri, S., Wood, F., & Ścibior, A. (2022). Critic Sequential Monte Carlo. ArXiv Preprint ArXiv:2205.15460. PDF@inproceedings{lioutas2022critic, title = {Critic Sequential Monte Carlo}, author = {Lioutas, Vasileios and Lavington, Jonathan Wilder and Sefas, Justice and Niedoba, Matthew and Liu, Yunpeng and Zwartsenberg, Berend and Dabiri, Setareh and Wood, Frank and {\'S}cibior, Adam}, journal = {arXiv preprint arXiv:2205.15460}, year = {2022} } -
Baydin, A. G., Pearlmutter, B. A., Syme, D., Wood, F., & Torr, P. (2022). Gradients without Backpropagation.
@unpublished{BAY-22, author = {Baydin, Atılım Güneş and Pearlmutter, Barak A. and Syme, Don and Wood, Frank and Torr, Philip}, keywords = {Machine Learning (cs.LG), Machine Learning (stat.ML), FOS: Computer and information sciences, FOS: Computer and information sciences, I.2.6; I.2.5, 68T07}, title = {Gradients without Backpropagation}, year = {2022}, eprint = {2202.08587}, archiveprefix = {arXiv}, note = {{\em arXiv preprint arXiv:2202.08587}} } -
Teng, M., van de Panne, M., & Wood, F. (2022). Exploration with Multi-Sample Target Values for Distributional Reinforcement Learning.
@unpublished{TEN-22, author = {Teng, Michael and van de Panne, Michiel and Wood, Frank}, keywords = {Machine Learning (cs.LG), Artificial Intelligence (cs.AI), FOS: Computer and information sciences, FOS: Computer and information sciences}, title = {Exploration with Multi-Sample Target Values for Distributional Reinforcement Learning}, year = {2022}, eprint = {2202.02693}, archiveprefix = {arXiv}, note = {{\em arXiv preprint arXiv:2202.02693}} } -
Bateni, P., Barber, J., Goyal, R., Masrani, V., van de Meent, J.-W., Sigal, L., & Wood, F. (2022). Beyond Simple Meta-Learning: Multi-Purpose Models for Multi-Domain, Active and Continual Few-Shot Learning.
@unpublished{BAT-22, author = {Bateni, Peyman and Barber, Jarred and Goyal, Raghav and Masrani, Vaden and van de Meent, Jan-Willem and Sigal, Leonid and Wood, Frank}, keywords = {Computer Vision and Pattern Recognition (cs.CV), FOS: Computer and information sciences, FOS: Computer and information sciences}, title = {Beyond Simple Meta-Learning: Multi-Purpose Models for Multi-Domain, Active and Continual Few-Shot Learning}, year = {2022}, eprint = {2201.05151}, archiveprefix = {arXiv}, note = {{\em arXiv preprint arXiv:2201.05151}} } -
Pfeffer, A., Call, C., Wood, F., Rosenberg, B., Bibbiani, K., Sigal, L., Shah, I., Erdogmus, D., Singh, S., & van de Meent, J. W. (2021). Probabilistic Label-Efficient Deep Generative Structures (PLEDGES). Charles River Analytics Inc.
@techreport{pfeffer2021probabilistic, title = {Probabilistic Label-Efficient Deep Generative Structures (PLEDGES)}, author = {Pfeffer, Avi and Call, Catherine and Wood, Frank and Rosenberg, Brad and Bibbiani, Kirstin and Sigal, Leonid and Shah, Ishaan and Erdogmus, Deniz and Singh, Sameer and van de Meent, Jan W}, year = {2021}, institution = {Charles River Analytics Inc.} } -
 Naderiparizi, S., Chiu, K., Bloem-Reddy, B., & Wood, F. (2020). Uncertainty in Neural Processes. In arXiv preprint arXiv:1906.05462. PDF
Naderiparizi, S., Chiu, K., Bloem-Reddy, B., & Wood, F. (2020). Uncertainty in Neural Processes. In arXiv preprint arXiv:1906.05462. PDFWe explore the effects of architecture and training objective choice on amortized posterior predictive inference in probabilistic conditional generative models. We aim this work to be a counterpoint to a recent trend in the literature that stresses achieving good samples when the amount of conditioning data is large. We instead focus our attention on the case where the amount of conditioning data is small. We highlight specific architecture and objective choices that we find lead to qualitative and quantitative improvement to posterior inference in this low data regime. Specifically we explore the effects of choices of pooling operator and variational family on posterior quality in neural processes. Superior posterior predictive samples drawn from our novel neural process architectures are demonstrated via image completion/in-painting experiments.
@unpublished{NAD-20a, title = {Uncertainty in Neural Processes}, author = {Naderiparizi, Saeid and Chiu, Kenny and Bloem-Reddy, Benjamin and Wood, Frank}, journal = {arXiv preprint arXiv:1906.05462}, year = {2020}, eid = {arXiv:2010.03753}, archiveprefix = {arXiv}, eprint = {2010.03753}, url_arxiv = {https://arxiv.org/abs/2010.03753}, url_paper = {https://arxiv.org/pdf/2010.03753.pdf}, support = {D3M,ETALUMIS} } -
 Yoo, J., Joseph, T., Yung, D., Nasseri, S. A., & Wood, F. (2020). Ensemble Squared: A Meta AutoML System. PDF
Yoo, J., Joseph, T., Yung, D., Nasseri, S. A., & Wood, F. (2020). Ensemble Squared: A Meta AutoML System. PDFThe continuing rise in the number of problems amenable to machine learning solutions, coupled with simultaneous growth in both computing power and variety of machine learning techniques has led to an explosion of interest in automated machine learning (AutoML). This paper presents Ensemble Squared (Ensemble2), a "meta" AutoML system that ensembles at the level of AutoML systems. Ensemble2 exploits the diversity of existing, competing AutoML systems by ensembling the top-performing models simultaneously generated by a set of them. Our work shows that diversity in AutoML systems is sufficient to justify ensembling at the AutoML system level. In demonstrating this, we also establish a new state of the art AutoML result on the OpenML classification challenge.
@unpublished{yoo2020ensemble, title = {Ensemble Squared: A Meta AutoML System}, author = {Yoo, Jason and Joseph, Tony and Yung, Dylan and Nasseri, S. Ali and Wood, Frank}, year = {2020}, eprint = {2012.05390}, archiveprefix = {arXiv}, primaryclass = {cs.LG}, url_arxiv = {https://arxiv.org/abs/2012.05390}, url_paper = {https://arxiv.org/pdf/2012.05390.pdf}, support = {D3M} } -
 van de Meent, J.-W., Paige, B., Yang, H., & Wood, F. (2018). An introduction to probabilistic programming. ArXiv Preprint ArXiv:1809.10756. PDF
van de Meent, J.-W., Paige, B., Yang, H., & Wood, F. (2018). An introduction to probabilistic programming. ArXiv Preprint ArXiv:1809.10756. PDF@article{van2018introduction, title = {An introduction to probabilistic programming}, author = {van de Meent, Jan-Willem and Paige, Brooks and Yang, Hongseok and Wood, Frank}, journal = {arXiv preprint arXiv:1809.10756}, year = {2018} } -
 Teng, M., Le, T. A., Scibior, A., & Wood, F. (2019). Imitation Learning of Factored Multi-agent Reactive Models. ArXiv Preprint ArXiv:1903.04714. PDF
Teng, M., Le, T. A., Scibior, A., & Wood, F. (2019). Imitation Learning of Factored Multi-agent Reactive Models. ArXiv Preprint ArXiv:1903.04714. PDF@article{teng2019imitation, title = {Imitation Learning of Factored Multi-agent Reactive Models}, author = {Teng, Michael and Le, Tuan Anh and Scibior, Adam and Wood, Frank}, journal = {arXiv preprint arXiv:1903.04714}, year = {2019} } -
Harvey, W., Teng, M., & Wood, F. (2019). Near-Optimal Glimpse Sequences for Improved Hard Attention Neural Network Training. ArXiv Preprint ArXiv:1906.05462. PDF
@article{harvey2019near, title = {Near-Optimal Glimpse Sequences for Improved Hard Attention Neural Network Training}, author = {Harvey, William and Teng, Michael and Wood, Frank}, journal = {arXiv preprint arXiv:1906.05462}, year = {2019} } -
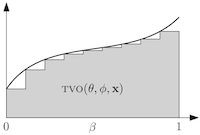 Masrani, V., Le, T. A., & Wood, F. (2019). The Thermodynamic Variational Objective. ArXiv Preprint ArXiv:1907.00031. PDF
Masrani, V., Le, T. A., & Wood, F. (2019). The Thermodynamic Variational Objective. ArXiv Preprint ArXiv:1907.00031. PDF@article{masrani2019thermodynamic, title = {The Thermodynamic Variational Objective}, author = {Masrani, Vaden and Le, Tuan Anh and Wood, Frank}, journal = {arXiv preprint arXiv:1907.00031}, year = {2019} } -
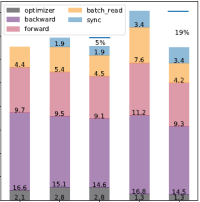 Baydin, A. G., Shao, L., Bhimji, W., Heinrich, L., Meadows, L., Liu, J., Munk, A., Naderiparizi, S., Gram-Hansen, B., Louppe, G., & others. (2019). Etalumis: Bringing Probabilistic Programming to Scientific Simulators at Scale. ArXiv Preprint ArXiv:1907.03382. PDF
Baydin, A. G., Shao, L., Bhimji, W., Heinrich, L., Meadows, L., Liu, J., Munk, A., Naderiparizi, S., Gram-Hansen, B., Louppe, G., & others. (2019). Etalumis: Bringing Probabilistic Programming to Scientific Simulators at Scale. ArXiv Preprint ArXiv:1907.03382. PDF@article{baydin2019etalumis, title = {Etalumis: Bringing Probabilistic Programming to Scientific Simulators at Scale}, author = {Baydin, At{\i}l{\i}m G{\"u}ne{\c{s}} and Shao, Lei and Bhimji, Wahid and Heinrich, Lukas and Meadows, Lawrence and Liu, Jialin and Munk, Andreas and Naderiparizi, Saeid and Gram-Hansen, Bradley and Louppe, Gilles and others}, journal = {arXiv preprint arXiv:1907.03382}, year = {2019} } -
Warrington, A., Spencer, A., & Wood, F. (2019). The Virtual Patch Clamp: Imputing C. elegans Membrane Potentials from Calcium Imaging. ArXiv Preprint ArXiv:1907.11075. PDF
@article{warrington2019virtual, title = {The Virtual Patch Clamp: Imputing C. elegans Membrane Potentials from Calcium Imaging}, author = {Warrington, Andrew and Spencer, Arthur and Wood, Frank}, journal = {arXiv preprint arXiv:1907.11075}, year = {2019} } -
Teng, M., Le, T. A., Scibior, A., & Wood, F. (2019). Imitation Learning of Factored Multi-agent Reactive Models. ArXiv Preprint ArXiv:1903.04714.
@article{teng2019imitatioo, title = {Imitation Learning of Factored Multi-agent Reactive Models}, author = {Teng, Michael and Le, Tuan Anh and Scibior, Adam and Wood, Frank}, journal = {arXiv preprint arXiv:1903.04714}, year = {2019} } -
Le, T. A., Kosiorek, A. R., Siddharth, N., Teh, Y. W., & Wood, F. (2018). Revisiting reweighted wake-sleep. ArXiv Preprint ArXiv:1805.10469.
@article{le2018revisiting, title = {Revisiting reweighted wake-sleep}, author = {Le, Tuan Anh and Kosiorek, Adam R and Siddharth, N and Teh, Yee Whye and Wood, Frank}, journal = {arXiv preprint arXiv:1805.10469}, year = {2018} } -
Rainforth, T., Zhou, Y., Lu, X., Teh, Y. W., Wood, F., Yang, H., & van de Meent, J.-W. (2018). Inference trees: Adaptive inference with exploration. ArXiv Preprint ArXiv:1806.09550.
@article{rainforth2018inference, title = {Inference trees: Adaptive inference with exploration}, author = {Rainforth, Tom and Zhou, Yuan and Lu, Xiaoyu and Teh, Yee Whye and Wood, Frank and Yang, Hongseok and van de Meent, Jan-Willem}, journal = {arXiv preprint arXiv:1806.09550}, year = {2018} } -
Cornish, R., Yang, H., & Wood, F. (2018). Towards a Testable Notion of Generalization for Generative Adversarial Networks.
@article{cornish2018towards, title = {Towards a Testable Notion of Generalization for Generative Adversarial Networks}, author = {Cornish, Robert and Yang, Hongseok and Wood, Frank}, year = {2018} } -
Milutinovic, M., Baydin, A. G., Zinkov, R., Harvey, W., Song, D., Wood, F., & Shen, W. (2017). End-to-end Training of Differentiable Pipelines Across Machine Learning Frameworks.
@article{milutinovic2017end, title = {End-to-end Training of Differentiable Pipelines Across Machine Learning Frameworks}, author = {Milutinovic, Mitar and Baydin, At{\i}l{\i}m G{\"u}ne{\c{s}} and Zinkov, Robert and Harvey, William and Song, Dawn and Wood, Frank and Shen, Wade}, year = {2017} } -
Warrington, A., & Wood, F. (2017). Updating the VESICLE-CNN Synapse Detector. ArXiv Preprint ArXiv:1710.11397.
@article{warrington2017updating, title = {Updating the VESICLE-CNN Synapse Detector}, author = {Warrington, Andrew and Wood, Frank}, journal = {arXiv preprint arXiv:1710.11397}, year = {2017} } -
Casado, M. L., Baydin, A. G., Rubio David Martı́nez, Le, T. A., Wood, F., Heinrich, L., Louppe, G., Cranmer, K., Ng, K., Bhimji, W., & others. (2017). Improvements to Inference Compilation for Probabilistic Programming in Large-Scale Scientific Simulators. ArXiv Preprint ArXiv:1712.07901.
@article{casado2017improvements, title = {Improvements to Inference Compilation for Probabilistic Programming in Large-Scale Scientific Simulators}, author = {Casado, Mario Lezcano and Baydin, Atilim Gunes and Rubio, David Mart{\'\i}nez and Le, Tuan Anh and Wood, Frank and Heinrich, Lukas and Louppe, Gilles and Cranmer, Kyle and Ng, Karen and Bhimji, Wahid and others}, journal = {arXiv preprint arXiv:1712.07901}, year = {2017} } -
Warrington, A., & and Wood, F. (2016). Optimizing Neuron Generation Model Parameters for Top-Down Segmentation Regularization. NIPS Workshop on Connectomics II: Opportunities and Challenges for Machine Learning.
@inproceedings{WarringtonWood-NEURO-OPT-NIPS-2016, author = {Warrington, Andrew and and Wood, Frank}, booktitle = {NIPS Workshop on Connectomics II: Opportunities and Challenges for Machine Learning}, title = {Optimizing Neuron Generation Model Parameters for Top-Down Segmentation Regularization}, year = {2016} } -
Le, T. A., Baydin, A. G., & Wood, F. (2016). Inference Compilation and Universal Probabilistic Programming. ArXiv Preprint ArXiv:1610.09900. PDF
@article{le2016inference, title = {Inference Compilation and Universal Probabilistic Programming}, author = {Le, Tuan Anh and Baydin, Atılım Güneş and Wood, Frank}, journal = {arXiv preprint arXiv:1610.09900}, year = {2016} } -
Paige, B., & Wood, F. (2016). Inference Networks for Sequential Monte Carlo in Graphical Models. ArXiv Preprint ArXiv:1602.06701.
@article{paige2016inferencenetworks, title = {Inference Networks for Sequential Monte Carlo in Graphical Models}, author = {Paige, Brooks and Wood, Frank}, journal = {arXiv preprint arXiv:1602.06701}, year = {2016} } -
Perov, Y. N., Le, T. A., & Wood, F. (2015). Data-driven Sequential Monte Carlo in Probabilistic Programming. ArXiv Preprint ArXiv:1512.04387.
@article{perov2015data, title = {Data-driven Sequential Monte Carlo in Probabilistic Programming}, author = {Perov, Yura N and Le, Tuan Anh and Wood, Frank}, journal = {arXiv preprint arXiv:1512.04387}, year = {2015} } -
Rainforth, T., Naesseth, C. A., Lindsten, F., Paige, B., van de Meent, J.-W., Doucet, A., & Wood, F. (2016). Interacting Particle Markov Chain Monte Carlo. ArXiv Preprint ArXiv:1602.05128. PDF
@article{rainforth2016interacting, title = {Interacting Particle Markov Chain Monte Carlo}, author = {Rainforth, Tom and Naesseth, Christian A and Lindsten, Fredrik and Paige, Brooks and van de Meent, Jan-Willem and Doucet, Arnaud and Wood, Frank}, journal = {arXiv preprint arXiv:1602.05128}, year = {2016} } -
van de Meent, J.-W., Tolpin, D., Paige, B., & Wood, F. (2015). Black-Box Policy Search with Probabilistic Programs. ArXiv (Accepted at AISTATS 2016), 1507.04635. PDF
@article{vandemeent_arxiv_1507_04635, journal = {ArXiv (accepted at AISTATS 2016)}, archiveprefix = {arXiv}, arxivid = {1507.04635}, author = {van de Meent, Jan-Willem and Tolpin, David and Paige, Brooks and Wood, Frank}, eprint = {1507.04635}, pages = {1507.04635}, title = {{Black-Box Policy Search with Probabilistic Programs}}, year = {2015} } -
Rainforth, T., & Wood, F. (2015). Canonical Correlation Forests. ArXiv Preprint ArXiv:1507.05444. https://bitbucket.org/twgr/ccf PDF
@article{Rainforth-2015-CCF-arXiv, title = {Canonical Correlation Forests}, url = {https://bitbucket.org/twgr/ccf}, author = {Rainforth, Tom and Wood, Frank}, journal = {arXiv preprint arXiv:1507.05444}, year = {2015} } -
Paige, B., Wood, F., Doucet, A., & Teh, Y. W. (2014). Asynchronous Anytime Sequential Monte Carlo. ArXiv Preprint ArXiv:1407.2864. PDF
@article{Paige-2014-arXiv, title = {Asynchronous Anytime Sequential {M}onte {C}arlo}, author = {Paige, Brooks and Wood, Frank and Doucet, Arnaud and Teh, Yee Whye}, journal = {arXiv preprint arXiv:1407.2864}, year = {2014} } -
Perov, Y., & Wood, F. (2014). Learning Probabilistic Programs. ArXiv Preprint ArXiv:1407.2646. PDF
@article{Perov-2014-arXiv, title = {Learning Probabilistic Programs}, author = {Perov, Yura and Wood, Frank}, journal = {arXiv preprint arXiv:1407.2646}, year = {2014} } -
Paige, B., & Wood, F. (2014). A Compilation Target for Probabilistic Programming Languages. ArXiv Preprint ArXiv:1403.0504. PDF
@article{paige2014compilation, title = {A Compilation Target for Probabilistic Programming Languages}, author = {Paige, Brooks and Wood, Frank}, journal = {arXiv preprint arXiv:1403.0504}, year = {2014} }
Book Chapters
-
 Wood, F., & Perotte, A. (2014). Handbook of Mixed Membership Models and Their Applications (E. E. E. Airoldi D. Blei & S. Fienberg, Eds.). Chapman and Hall/CRC.
Wood, F., & Perotte, A. (2014). Handbook of Mixed Membership Models and Their Applications (E. E. E. Airoldi D. Blei & S. Fienberg, Eds.). Chapman and Hall/CRC.@inbook{Wood-HMMTH-2014, author = {Wood, F. and Perotte, A.}, year = {2014}, chapter = {Mixed Membership Classification for Documents with Hierarchically Structured Labels}, editor = {E. Airoldi, D. Blei, E. Erosheva and Fienberg, S.}, title = {Handbook of Mixed Membership Models and Their Applications}, publisher = {Chapman and Hall/CRC} }
Invited Papers
-
Wood, F. (2011). Discussion of "The Discrete Infinite Logistic Normal Distribution for Mixed-Membership Modeling". Artificial Intelligence and Statistics. PDF
@inproceedings{Wood-AISTATS-2011-response, author = {Wood, F.}, booktitle = {Artificial Intelligence and Statistics}, title = {Discussion of "The Discrete Infinite Logistic Normal Distribution for Mixed-Membership Modeling"}, year = {2011}, pages = {} }
Workshop Publications
-
Lavington, J. W., Teng, M., Schmidt, M., & Wood, F. (2021). A Closer Look at Gradient Estimators with Reinforcement Learning as Inference. Deep RL Workshop NeurIPS 2021.
@inproceedings{lavington2021a, title = {A Closer Look at Gradient Estimators with Reinforcement Learning as Inference}, author = {Lavington, Jonathan Wilder and Teng, Michael and Schmidt, Mark and Wood, Frank}, booktitle = {Deep RL Workshop NeurIPS 2021}, year = {2021} } -
Ścibior, A., Lioutas, V., Reda, D., Bateni, P., & Wood, F. (2021). Imagining The Road Ahead: Multi-Agent Trajectory Prediction via Differentiable Simulation . CVPR Workshop Workshop on Autonomous Driving: Perception, Prediction and Planning.
@inproceedings{scibior2021imaginingcvprworkshop, title = {{I}magining {T}he {R}oad {A}head: Multi-Agent Trajectory Prediction via Differentiable Simulation }, author = {{\'S}cibior, Adam and Lioutas, Vasileios and Reda, Daniele and Bateni, Peyman and Wood, Frank}, booktitle = {CVPR Workshop Workshop on Autonomous Driving: Perception, Prediction and Planning}, year = {2021}, eprint = {2104.11212}, archiveprefix = {arXiv} } -
Stefan Webb, R. Z., Adam Golinski, & Wood, F. (2017). Principled Inference Networks in Deep Generative Models. NIPS Workshop on Bayesian Deep Learning.
@inproceedings{webbnips2017workshop, title = {Principled Inference Networks in Deep Generative Models}, author = {Stefan Webb, Adam Golinski, Robert Zinkov and Wood, Frank}, booktitle = {NIPS Workshop on Bayesian Deep Learning}, year = {2017} } -
Siddharth, N., Paige, B., Desmaison, A., van de Meent, J.-W., Wood, F., Goodman, N. D., Kohli, P., & Torr, P. H. S. (2016). Inducing Interpretable Representations with Variational Autoencoders. NIPS Workshop on Interpretable ML for Complex Systems. PDF
@inproceedings{siddharth2016interpretable, author = {Siddharth, N. and Paige, Brooks and Desmaison, Alban and van de Meent, Jan-Willem and Wood, Frank and Goodman, Noah D. and Kohli, Pushmeet and Torr, Philip H.S.}, booktitle = {NIPS Workshop on Interpretable ML for Complex Systems}, title = {Inducing Interpretable Representations with Variational Autoencoders}, year = {2016} } -
 Le, T. A., Baydin, A. G., & Wood, F. (2016). Nested Compiled Inference for Hierarchical Reinforcement Learning. NIPS Workshop on Bayesian Deep Learning. PDF
Le, T. A., Baydin, A. G., & Wood, F. (2016). Nested Compiled Inference for Hierarchical Reinforcement Learning. NIPS Workshop on Bayesian Deep Learning. PDF@inproceedings{le2016nested, author = {Le, Tuan Anh and Baydin, Atılım Güneş and Wood, Frank}, booktitle = {NIPS Workshop on Bayesian Deep Learning}, title = {Nested Compiled Inference for Hierarchical Reinforcement Learning}, year = {2016} } -
Rainforth, T., Cornish, R., Yang, H., & Wood, F. (2016). On the Pitfalls of Nested Monte Carlo. NIPS Workshop on Advances in Approximate Bayesian Inference. PDF
@article{rainforth2016nestedmc, title = {On the {P}itfalls of {N}ested {M}onte {C}arlo}, author = {Rainforth, Tom and Cornish, Rob and Yang, Hongseok and Wood, Frank}, year = {2016}, journal = {NIPS Workshop on Advances in Approximate Bayesian Inference} } -
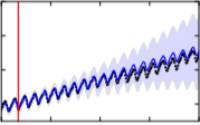 Janz, D., Paige, B., Rainforth, T., van de Meent, J.-W., & Wood, F. (2016). Probabilistic Structure Discovery in Time Series Data. NIPS Workshop on Artificial Intelligence for Data Science. PDF
Janz, D., Paige, B., Rainforth, T., van de Meent, J.-W., & Wood, F. (2016). Probabilistic Structure Discovery in Time Series Data. NIPS Workshop on Artificial Intelligence for Data Science. PDF@article{janz2016probstruct, title = {Probabilistic {S}tructure {D}iscovery in {T}ime {S}eries {D}ata}, author = {Janz, David and Paige, Brooks and Rainforth, Tom and van de Meent, Jan-Willem and Wood, Frank}, year = {2016}, journal = {NIPS Workshop on Artificial Intelligence for Data Science} } -
Warrington, A., & Wood, F. (2016). Algorithmic Optimisation of Neuron Generator Parameters. Frontiers in Neuroinformatics, 46. https://doi.org/10.3389/conf.fninf.2016.20.00046
@article{10.3389/conf.fninf.2016.20.00046, author = {Warrington, Andrew and Wood, Frank}, title = {Algorithmic Optimisation of Neuron Generator Parameters}, journal = {Frontiers in Neuroinformatics}, volume = {}, year = {2016}, number = {46}, url = {http://www.frontiersin.org/neuroinformatics/10.3389/conf.fninf.2016.20.00046/full}, doi = {10.3389/conf.fninf.2016.20.00046}, issn = {1662-5196} } -
van de Meent, J.-W., Paige, T. B., Tolpin, D., & Wood, F. (2016). An Interface for Black Box Learning in Probabilistic Programs. POPL Workshop on Probabilistic Programming Semantics. PDF
@inproceedings{vandemeent-PPS-2016, author = {van de Meent, Jan-Willem and Paige, T.~Brooks and Tolpin, David and Wood, Frank}, booktitle = {POPL Workshop on Probabilistic Programming Semantics}, title = {An Interface for Black Box Learning in Probabilistic Programs}, year = {2016} } -
Staton, S., amd Chris Heunen, H. Y., Kammar, O., & Wood, F. (2016). Semantics of Higher-order Probabilistic Programs. POPL Workshop on Probabilistic Programming Semantics. PDF
@inproceedings{staton-PPS-2016, author = {Staton, Sam and amd Chris Heunen, Hongseok Yang and Kammar, Ohad and Wood, Frank}, booktitle = {POPL Workshop on Probabilistic Programming Semantics}, title = {Semantics of Higher-order Probabilistic Programs}, year = {2016} } -
Paige, T. B., & and Wood, F. (2015). Inference Networks for Graphical Models. NIPS Workshop on Advances in Approximate Bayesian Inference. PDF
@inproceedings{PaigeWood-INFNET-NIPS-2015, author = {Paige, T.~Brooks and and Wood, Frank}, booktitle = {NIPS Workshop on Advances in Approximate Bayesian Inference}, title = {Inference Networks for Graphical Models}, year = {2015} } -
Rainforth, T., & Wood, F. (2015). Bayesian Optimization for Probabilistic Programs. NIPS Workshop on Black Box Learning and Inference. PDF
@inproceedings{Rainforth-NIPS-PPWORKSHOP15, author = {Rainforth, Tom and Wood, Frank}, booktitle = {NIPS Workshop on Black Box Learning and Inference}, title = {Bayesian Optimization for Probabilistic Programs}, year = {2015} } -
 Perov, Y., Le, T.-A., & Wood, F. (2015). Data-driven Sequential Monte Carlo in Probabilistic Programming. NIPS Workshop on Black Box Learning and Inference. PDF
Perov, Y., Le, T.-A., & Wood, F. (2015). Data-driven Sequential Monte Carlo in Probabilistic Programming. NIPS Workshop on Black Box Learning and Inference. PDF@inproceedings{Perov_DD_SMC_in_PP, author = {Perov, Yura and Le, Tuan-Anh and Wood, Frank}, booktitle = {NIPS Workshop on Black Box Learning and Inference}, title = {Data-driven Sequential {M}onte {C}arlo in Probabilistic Programming}, year = {2015} } -
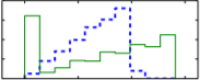 Perov, Y. N., & Wood, F. (2014). Learning probabilistic programs. NIPS Probabilistic Programming Workshop.
Perov, Y. N., & Wood, F. (2014). Learning probabilistic programs. NIPS Probabilistic Programming Workshop.@inproceedings{Perov-2014-NIPSPROBPROG, author = {Perov, Y. N. and Wood, F.}, booktitle = {NIPS Probabilistic Programming Workshop}, title = {Learning probabilistic programs}, year = {2014} } -
 van de Meent, J. W., Yang, H., Mansinghka, V., & Wood, F. (2014). Particle Gibbs with Ancestor Resampling for Probabilistic Programs. NIPS Probabilistic Programming Workshop. PDF
van de Meent, J. W., Yang, H., Mansinghka, V., & Wood, F. (2014). Particle Gibbs with Ancestor Resampling for Probabilistic Programs. NIPS Probabilistic Programming Workshop. PDF@inproceedings{vandeMeent-2014-NIPSPROBPROG, author = {van~de~Meent, J. W. and Yang, H. and Mansinghka, V. and Wood, F.}, booktitle = {NIPS Probabilistic Programming Workshop}, title = {Particle {G}ibbs with Ancestor Resampling for Probabilistic Programs}, year = {2014} } -
Tolpin, D., van de Meent, J. W., Paige, B., & Wood, F. (2014). Adaptive Scheduling in MCMC and Probabilistic Programming. NIPS Probabilistic Programming Workshop.
@inproceedings{Tolpin-2014-NIPSPROBPROG, author = {Tolpin, D. and van~de~Meent, J. W. and Paige, B. and Wood, F.}, booktitle = {NIPS Probabilistic Programming Workshop}, title = {Adaptive Scheduling in {MCMC} and Probabilistic Programming}, year = {2014} } -
Paige, T. B., Zhang, X., Forde, J., & Wood, F. (2012). Perspective Inference for Eye-to-Eye Videoconferencing: Empirical Evaluation Tools and Data. Proc. 7th Annual Machine Learning Workshop, New York Academy of Sciences.
@inproceedings{Paige-NYMLW-2012, title = {Perspective Inference for Eye-to-Eye Videoconferencing: Empirical Evaluation Tools and Data}, author = {Paige, T. B. and Zhang, X. and Forde, J. and Wood, F.}, booktitle = {Proc. 7th Annual Machine Learning Workshop, New York Academy of Sciences}, year = {2012} } -
Wood, F. (2011). Modeling Streaming Data In the Absence of Sufficiency. NIPS Nonparametric Bayes Workshop. PDF
@inproceedings{Wood-NIPSNPBAYES-2011, author = {Wood, F.}, booktitle = {NIPS Nonparametric {B}ayes Workshop}, title = {Modeling Streaming Data In the Absence of Sufficiency}, year = {2011} } -
Wood, F., & Teh, Y. W. (2008). A Hierarchical, Hierarchical Pitman Yor Process Language Model. ICML/UAI Nonparametric Bayes Workshop. PDF
@inproceedings{Wood-ICMLNPBAYES-2008, author = {Wood, F. and Teh, Y.W.}, booktitle = {ICML/UAI Nonparametric {B}ayes Workshop}, title = {A Hierarchical, Hierarchical {P}itman {Y}or Process Language Model}, year = {2008} } -
Grollman, D. H., Jenkins, O. C., & Wood, F. (2005). Discovering Natural Kinds of Robot Sensory Experiences in Unstructured Environments. Advances in Neural Information Processing Systems Workshop on Machine Learning Based Robotics in Unstructured Environments.
@inproceedings{Grollman-NIPS-2005, author = {Grollman, D. H. and Jenkins, O. C. and Wood, F.}, booktitle = {Advances in Neural Information Processing Systems Workshop on Machine Learning Based Robotics in Unstructured Environments}, title = {Discovering Natural Kinds of Robot Sensory Experiences in Unstructured Environments}, year = {2005} }