Research
My research interests span the spectrum of software development. Most of the work undetaken by my students examines questions that can improve how software engineers create, evolve, or understand real software systems. In particular, these projects usually have a human flavour to them as we seek to understand the challenges developers face and how we can make their jobs more efficient / less error prone / more fun. Below is an incomplete collection of the projects I have been a primary investigator on during my research career. They are listed in approximately reverse-chronological order.
Emerging Projects
- Understanding how source code methods evolve
- Evaluating the utility of SLOC with fine-grained data
- Automatic assertion generation
- Understanding causes of development friction
- Robotics training support
- Embedded programming language design
- Improved code review analysis tools
- Understanding project age with respect to Android malware
- Distributed open-source capstone projects for software engineering education
Published Projects
CodeShovel: Recovering method histories
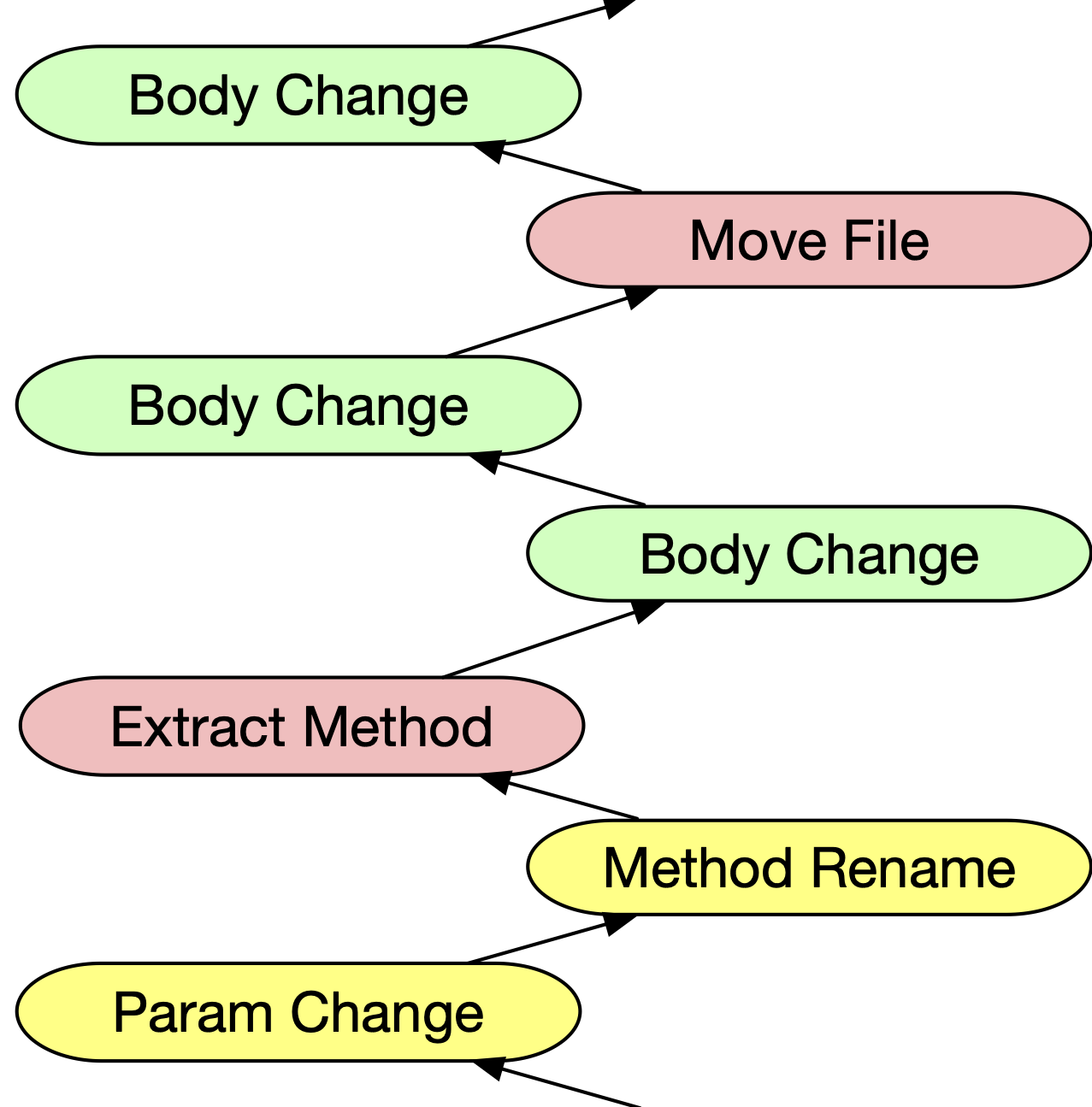
Developers often want to understand how their methods evolved when examining past code changes, but this is not supported by existing tooling. In a couple of seconds CodeShovel can recover the history of a method. Additionally, CodeShovel provides some context for the change: Was a paramater modified? Was the body changed? Was the file renamed or moved to a different directory? This context can make it easy to quickly find the key changes a developer might be looking for. Through an empirical study of both industrial and open source code, CodeShovel was able to correctly find 97% of all method changes. The tool can be downloaded and installed in less than 5 minutes and a public web service is available for testing. While CodeShovel was originally written for Java, new language support is also possible (e.g., TypeScript, JavaScript, Ruby, Python).
Details: [ICSE 2021], [Source Code & Tools], [Live Web Service].
AutoTest: Improving automatic grading
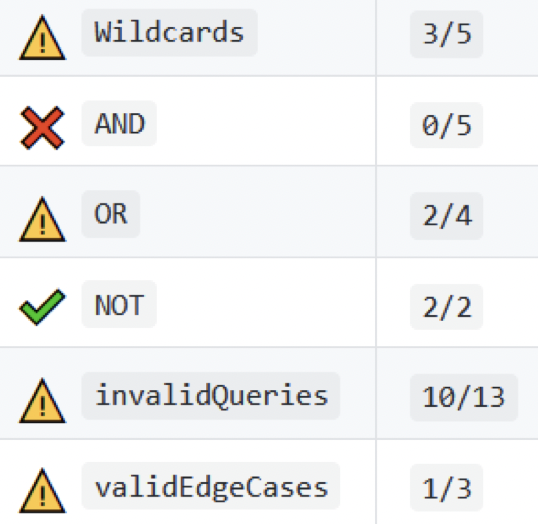
Automatic grading (via autograders) is becoming more and more widespread in academic courses. Autograders allow more timely formative feedback for students and allow teaching staff to focus their efforts on direct student contact, rather than post-hoc marking. We have investigated and evaluated number of approaches to improve autograders in order to make feedback more useful for students while reducing over-reliance on autograder feedback.
Clustered feedback provides less information to students while directing their attention to the course learning objectives. Regression penalties encourage students to more effectively test their own solutions before submitting them to the grader while fitting with a more real-world narrative of software development. These approaches have both been demonstrated to improve student experiences with autograders without impacting overall course scores.
Details: [SIGCSE 2021], [SPLASH-E 2020].
End-user robotics programming tools

As robots get cheaper and are more widely deployed, the cost of programming them becomes more problematic. Specific support is needed for end-user robotics programmers because robot users are usually not trained software engineers, and the users themselves best understand their needs for these kinds of robotics platforms. We have worked on several extensions to block based programming for end-user robotics programming. In particular, we have investigated techniques to enable end-users to control multi-armed robots, which has particular challenges due to the parallelism of these problems. Through large-scale studies of 250+ end-users we have shown that with proper support they are able to quickly and effectively program multi-armed robots for the kinds of real tasks these robots are used for in practice.
Details: [TSE 2020], [ROSE 2018].
EICE: Integrating online information into code editors
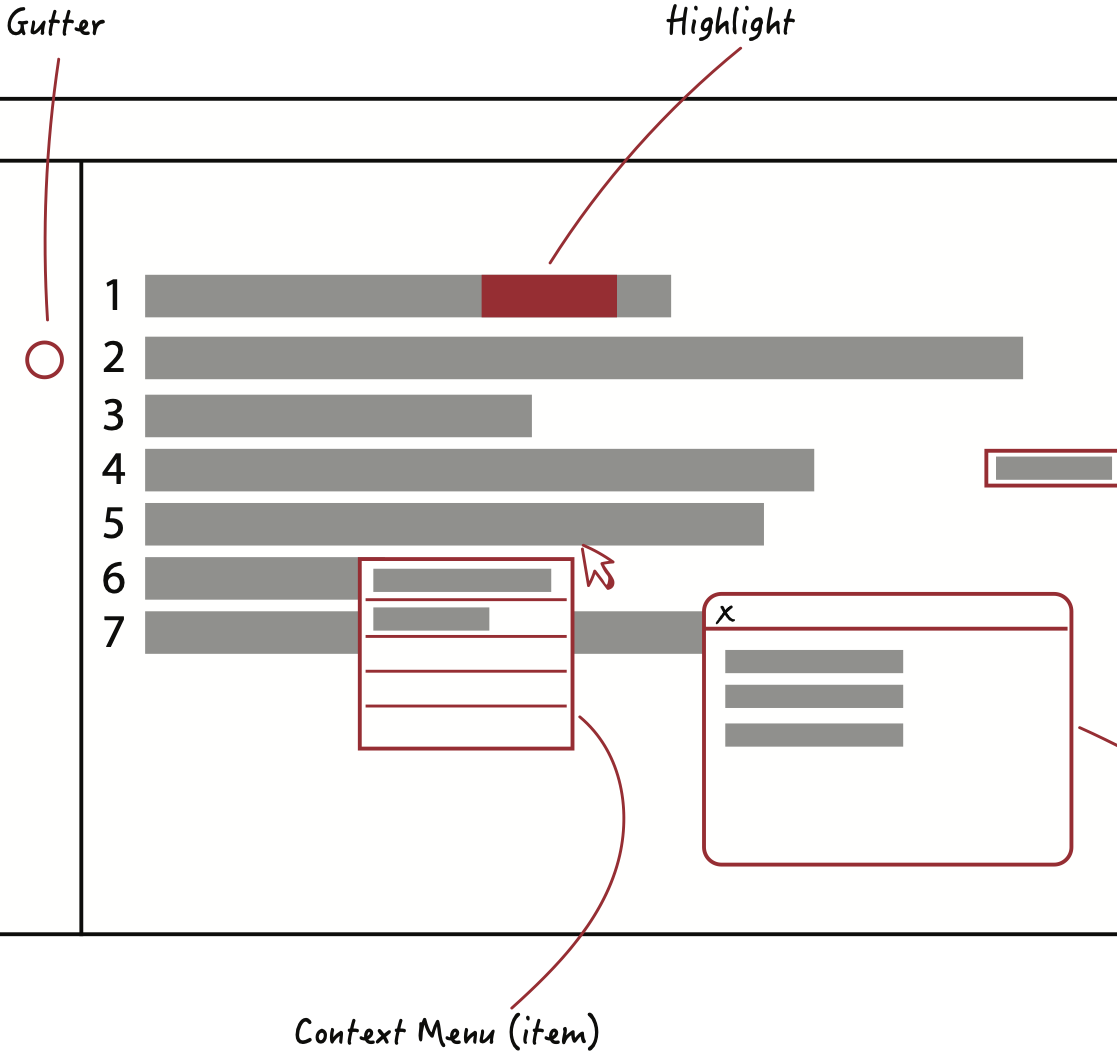
While developers mostly interact with their source code through dedicated editing environments (either editors or IDEs), the information pertinent to their code is spread across many different sources. These can include the version control, continuous integration, coverage, etc. In this project we developed EICE to explore developer preferences for integrating information from these external sources into code editors in a way that would maximize utility without being overly obtrusive. Developers preferred gutters icons for short visual queues and end-of-line badges for more verbose indicators over isolated views or direct code decorations. The goal of this work was to provide design guidance for future tool developers for tools that look to increase the information density of source code editors.
Details: [VISSOFT 2020].
Devy: Conversational developer agents

Software engineers must wrangle a diverse set of tools to complete their tasks. Each of these tools has their own interfaces, and typically exist independent of each other. In this work we created Devy, a conversational developer assistant, built as a skill for the Amazon Alexa platform. By monitoring developer context as they worked, Devy was able to infer high-level developer intent. Devy used this understanding of developer intent to model within- and cross-application workflows. Developers could invoke these workflows with simple voice commands. Developers appreciated the unified natural language interface as it enabled them to offload low-level workflows while staying more focused on their high-level development objectives.
Details: [ICSE 2018].
Evaluating the value of regression testing

Testing is expensive. Tests need to be created, debugged, executed, and evolved along with their codebases. While test failures are supposed to find defects, they often do not. In this work we examined 110,000 regression test builds to determine the proportion of test failures that found defects. We found that in practice 13% of failures result from flaky tests and 26% are a result of defects in the test themselves. Beyond the work required to fix these spurious failures, these failures just make work for developers and decrease their trust in the value of the test suite itself.
Details: [FSE 2017].
Understanding and improving code review
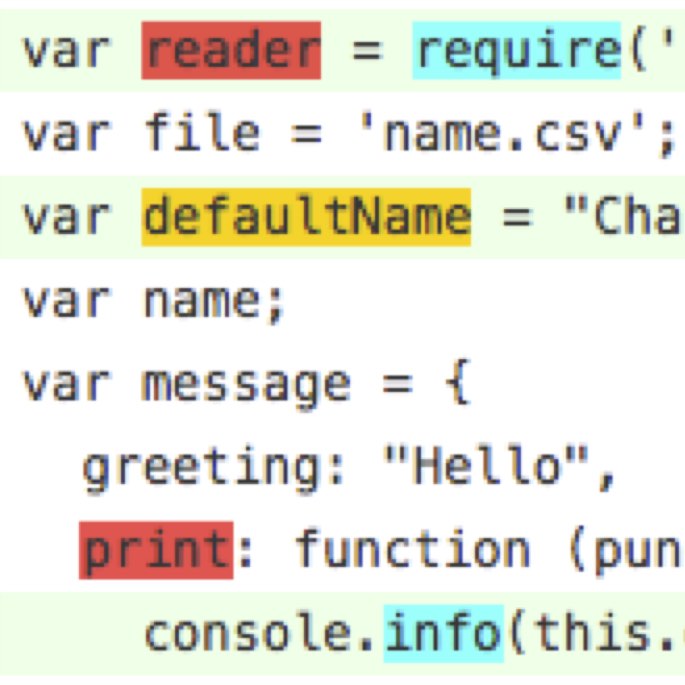
Code review is one of primary approaches for engineers to detect regressions before their changes are released to production. We have modelled code review as a state machine to see how changes transition through code reviews in several prominent open source projects. Through this analysis we found that while we tend to think about code review in technical terms, non-technical factors (such as developer organization and developer experience) tend to have significant impacts on code review timeliness and outcome.
Looking forward, we are developing new ways to augment traditional diff-based code reviews with additional semantic information to make it easier for developers to fully understand a change. Through this work, we have found that these analyses can provide much more context for developers to reason about the impact of a change on the rest of the code, rather than focusing on the change in isolation.
Details: [FSE 2014], [WCRE 2012], [WCRE 2013 (Distinguished Paper Award)], [ICSE 2014 NIER].
Are mutant failures similar to real failures?
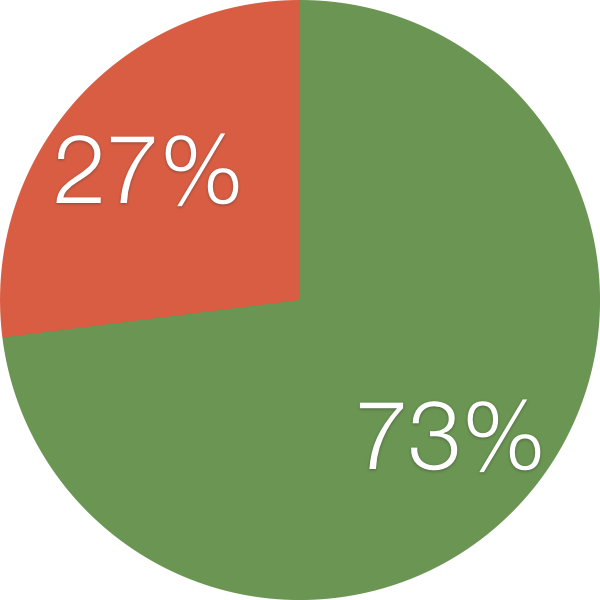
Mutation testing was proposed in the 1970s as a mechanism for evaluating the relative quality of a test (or suite of tests) by evaluating the sensitivity of a test to detect intentionally-injected faults. Unfortunately, whether these intentionally-injected faults (mutants) have any relationship to real defects is unknown. In this work, we evaluated whether mutant kill score increased or decreased when 357 real faults were evaluated with 230,000 different mutants. We found that for 73% of real faults the kill score did increase, suggesting there is a meaningful relationship between software mutants and real faults. The main implication of this work is that mutation testing is indeed a valid approach for oracle evaluation in continued test suite research.
Code coverage and test suite effectiveness
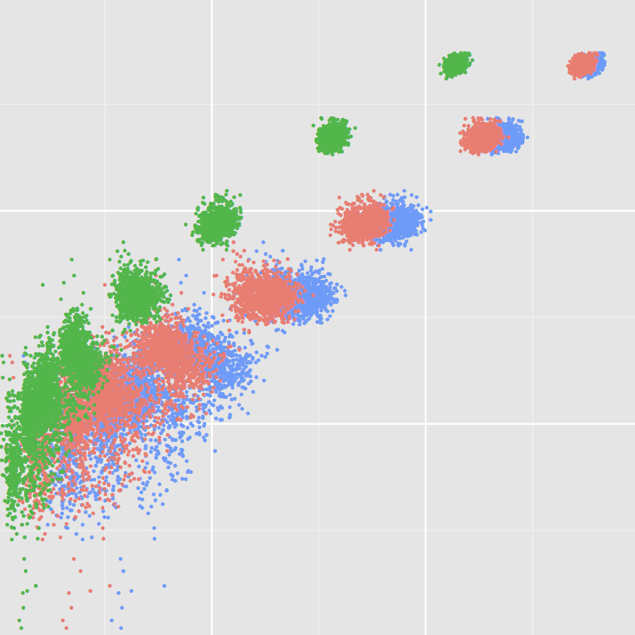
Coverage is one of the simplest metrics for evaluating the completeness of a test suite. While coverage is widely used in industry, it is not clear whether large test suites are able to detect faults because they have high coverage or just because they have large numbers of tests. To evaluate this we generated 31,000 test suites of various size and compared their effectiveness and coverage while controlling for the size of the test suites. Ultimately, we found that the correlation between suite coverage and suite effectiveness was high, but when the size of the test suite was controlled the correlation was low. This suggests that while coverage is a great measure to identify untested parts of a program, it is not a strong metric for evaluating the quality of the tests for the covered code, suggesting that setting coverage thresholds is likely not a meaningful goal in practice.
Baker: Live API documentation
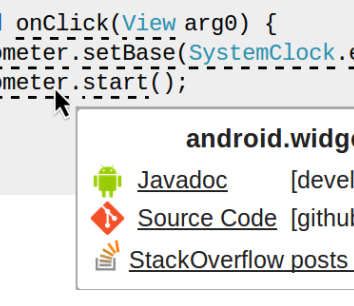
APIs are an extremely powerful abstraction mechanism used by every non-trivial software system. Unfortunately, understanding how to correctly use an API can be difficult. While a variety of online help exists for public APIs, finding the information can be difficult because help is usually expressed in plain text which causes many API names (types, fields, and methods) to collide with one another between libraries, frameworks, and systems. In this work, we built Baker, a deductive parser that was able to correctly identify the fully qualified name for an API reference from partial sources on StackOverflow 97% of the time. Our prototype worked for both Java and JavaScript and could be used to reliably link online text snippets to official API documentation (and vice versa).
Details: [ICSE 2014], [MSR 2013], [Project site].
Detecting unexpected behavioural changes
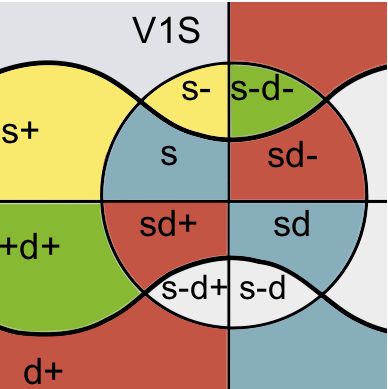
While developers often have a strong understanding of the static nature of their changes, the dynamic effects of these changes on the runtime behaviour of the program can be harder to comprehend. This approach automatically classifies the impact of a developer's change so they can better understand the dynamic consequences their modification tasks. The overall goal of this project is to enable developers to reason about the dynamic behaviour of their systems in a way that helps prevent unintended behavioural changes from being made.
Details: [ICSE 2011].
We created a short video overview of our approach for a research demonstration at ICSE 2011:
CrystalVC: Proactive conflict detection
Crystal's goal is to increase developer awareness of conflicts. When two or more developers collaborate, it is possible for their independent changes to conflict — either syntactically as a version control conflict or behaviourally if the changes merge cleanly but have unintended interactions. The Crystal tool informs each developer of the answer to the question, “Might my changes conflict with others' changes?”
Crystal monitors multiple developers' repositories. It informs each developer when it is safe to push her changes, when she has fallen behind and could pull changes from others or a central repository, and when changes other developers have made will cause a syntactic or behavioural conflict.
If conflicts occur, Crystal informs developers early, so they may resolve these conflicts quickly. Long-established conflicts can be much harder to resolve. If changes are made without conflicts, Crystal gives developers confidence to merge their changes without fearing unanticipated side effects.
Details: [FSE 2011 (ACM Distinguished Paper Award)], [FSE 2011 Demo].
Older Projects
YooHoo: Customized change awareness
It is often assumed that developers' view of their system and its environment is always consistent with everyone else's; in practice, this assumption can be false, as the developer has little practical control over changes to the environments in which their code will be deployed. To proactively respond to such situations, developers must constantly monitor a flood of information involving changes to the deployment environments; unfortunately, the vast majority of this information is irrelevant to the individual developer, and its sheer volume makes it likely that infrequent change events of relevance to them will be lost in the noise. As a result, errors may arise at deployment time that the developer will not be aware of for an extended delay.
This project examines a recommendation approach for filtering the flood of change events on deployment dependencies to those that are most likely to cause problems for the individual developer. The approach is evaluated for its ability to drastically filter irrelevant details, while being unlikely to filter important ones. The relevance of the results is assessed on the basis of deployment problems that would have historically occurred within a set of industrial systems.
Details: [ICSE 2010].
Gilligan: Pragmatic software reuse

Software reuse typically involves reusing components specifically designed for reuse; these components must provide the exact functionality that a developer requires and must fit within their system without structural or behavioural mismatch. When these two conditions are not met, developers have the opportunity to investigate pragmatic software reuse approaches; in these situations the software being reused may not have been designed specifically for reuse, but may enable the developer to greatly reduce the time and cost of developing similar software from scratch. In these cases developers must extract some portion of the source code, modify it to suit their needs, and integrate it into their own system.
To address shortcomings in performing these tasks manually, I created the Gilligan pragmatic-reuse environment. Developers using my planning tool were able to locate twice as many relevant program elements compared to traditional approaches; they needed to resolve 98% fewer compilation errors ; they were 32% more likely to successfully complete a pragmatic reuse task; and they took significantly less time to perform their pragmatic reuse tasks.
Details: [TOSEM 2012], [ICSE 2007], [ICSE 2006 Doctoral Symposium], [VISSOFT 2007].
Supporting end-to-end code search
Source code examples are valuable to developers needing to use an unfamiliar application programming interface (API). Numerous approaches exist to help developers locate source code examples; while some of these help the developer to select the most promising examples, none help the developer to reuse the example itself. Without explicit tool support for the complete end-to-end task, the developer can waste time and energy on examples that ultimately fail to be appropriate; as a result, the overhead required to reuse an example can restrict a developer's willingness to investigate multiple examples to find the "best" one for their situation. This paper outlines four case studies involving the end-to-end use of source code examples: we investigate the overhead and pitfalls involved in combining a few state-of-the-art techniques to support the end-to-end use of source code examples.
Details: [VISSOFT 2009].
Deep Intellisense: Surfacing context-sensitive information in IDEs
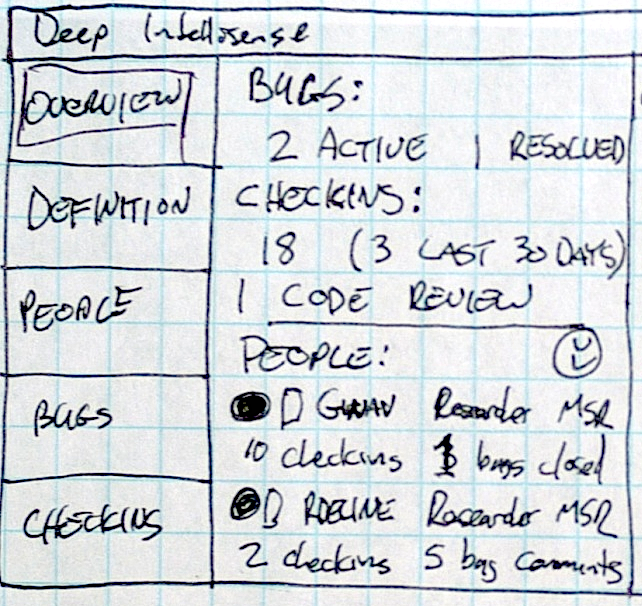
Software engineers working in large teams on large, long-lived code-bases have trouble understanding why the source code looks the way does. Often, they answer their questions by looking at past revisions of the source code, bug reports, code checkins, mailing list messages, and other documentation. This process of inquiry can be quite inefficient, especially when the answers they seek are located in isolated repositories accessed by multiple independent investigation tools. Prior mining approaches have focused on linking various data repositories together; in this paper we investigate techniques for displaying information extracted from the repositories in a way that helps developers to build a cohesive mental model of the rationale behind the code. After interviewing several developers and testers about how they investigate source code, we created a Visual Studio plugin called Deep Intellisense that summarizes and displays historical information about source code. We designed Deep Intellisense to address many of the hurdles engineers face with their current techniques, and help them spend less time gathering information and more time getting their work done.
Some aspects of this research prototype have been integrated into Microsoft VisualStudio as CodeLense.
Details: [MSR 2008].
PopCon: Identifying important APIs
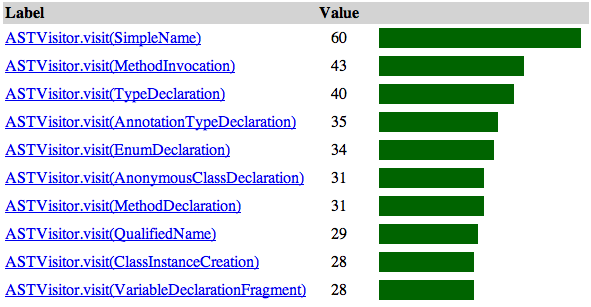
Eclipse has evolved from a fledgling Java IDE into a mature software ecosystem. One of the greatest benefits Eclipse provides developers is flexibility; however, this is not without cost. New Eclipse developers often find the framework to be large and confusing. Determining which parts of the framework they should be using can be a difficult task as Eclipse documentation tends to be either very high-level, focusing on the design of the framework, or low-level, focusing on specific APIs. We have developed a tool called PopCon that provides a bridge between high-level design documentation and low-level API documentation by statically analyzing a framework and several of its clients and providing a ranked list of the relative popularity of its APIs. We have applied PopCon to the Eclipse framework for this challenge to help newbie Eclipse developers identify some of the most relevant APIs for their tasks.
Details: [eTX 2007].
Strathcona: Context-sensitive example recommendation
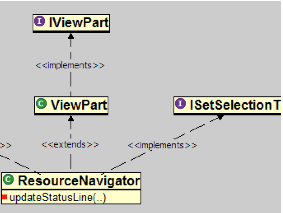
When coding to an application programming interface (API), developers often encounter difficulties, unsure of which class to subclass, which objects to instantiate, and which methods to call. Example source code that demonstrates the use of the API can help developers make progress on their task. This paper describes an approach to provide such examples in which the structure of the source code that the developer is writing is matched heuristically to a repository of source code that uses the API. The structural context needed to query the repository is extracted automatically from the code, freeing the developer from learning a query language or from writing their code in a particular style. The repository is generated automatically from existing applications, avoiding the need for handcrafted examples. We demonstrate that the approach is effective, efficient, and more reliable than traditional alternatives through four empirical studies.
Details: [ICSE 2005 (ACM Distinguished Paper Award)], [TSE 2006].