IRS Audit Rates
IRS Audit Rates by County
Overview
In this tutorial, we will stack four years of county-level tax filing data and then pack the result with a table of IRS audit rates by county. Along the way, we will discover and resolve a FIPS code mismatch between data sources — a common challenge when joining data from different agencies.
This workflow is based on a ProPublica investigation: “Where in The U.S. Are You Most Likely to Be Audited by the IRS?”.
Data Sources
Bloomquist - Regional Bias in IRS Audit Selection Data.xlsx— estimated number of tax exams (audits) per county for tax years 2012–15, calculated by Kim M. Bloomquist using audit coverage rates from the annual IRS Data Book.County-2012.xlsx,County-2013.xlsx,County-2014.xlsx,County-2015.xlsx— number of tax filings per county for each year, downloaded from the IRS website.
Workflow Steps
Pre-processing
We have already performed these pre-processing steps in the downloadable data package, but you can reproduce them manually before loading data into OpenRoundup.
For each of the four county filings spreadsheets (County-2012.xlsx through County-2015.xlsx):
- Open in a spreadsheet application, e.g. Microsoft Excel or Google Sheets.
- These files have nested headers; flatten them so that all column names appear in a single header row.

- These spreadsheets also are inundated with irrelevant columns. Remove all irrelevant columns. For the sake of simplicity, the supplied data retains only the first five columns in each spreadsheet. Some spreadsheets have 256 columns, so this is a significant reduction in data that we know we won’t be using for our analysis. This step is not strictly necessary, but it makes it easier to work with the data in OpenRoundup and reduces the likelihood of running into performance issues.
- Remove any data notes at the end of the table, which are not part of the data. For this particular workflow, it is not strictly necessary to do this, these rows can be removed via pack operation parameters, but we will demonstrate this feature with other rows in the data.
- In each spreadsheet, create a combined FIPS code column by concatenating the state FIPS code with the county FIPS code to create a unique county identifier. This can be done by concatenating the state FIPS code with a zero-padded version of the county FIPS code, e.g.
=CONCAT(A2, TEXT(C2, "000"))in Excel. - Export as a CSV.
For the Bloomquist audit data spreadsheet, simply open it in a spreadsheet application and export it to CSV, as no pre-processing is necessary for that table.
OpenRoundup Steps
One the pre-processing steps have been completed, the data can be imported into OpenRoundup and further processed using stack and pack operations.
- Import all the data into OpenRoundup.
- Rename the
Bloomquist__Regional_Bias_in_IRS_Audit_datato justBloomquistfor easier reference in subsequent steps. - Stack the four county filings tables together.
- Materialize the stack operation and inspect results to confirm that the stack has been performed correctly. The resulting table should have the same columns as the source tables.
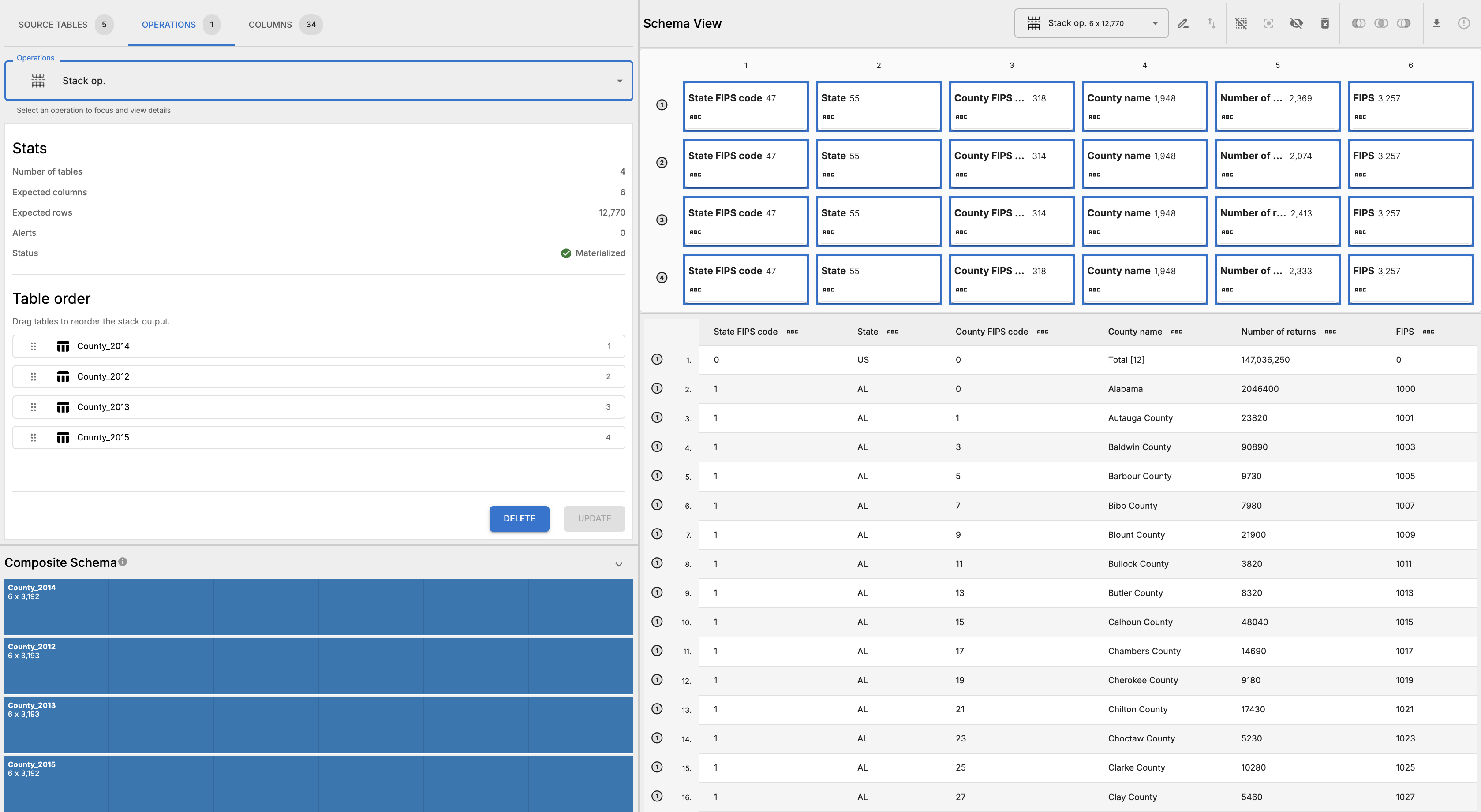 .
. - Rename the stack operation to “county-filings” for easier reference in subsequent steps.
- In the Source Tables tab, select Bloomquist table and click “pack table” in the actions dropdown button for the component.
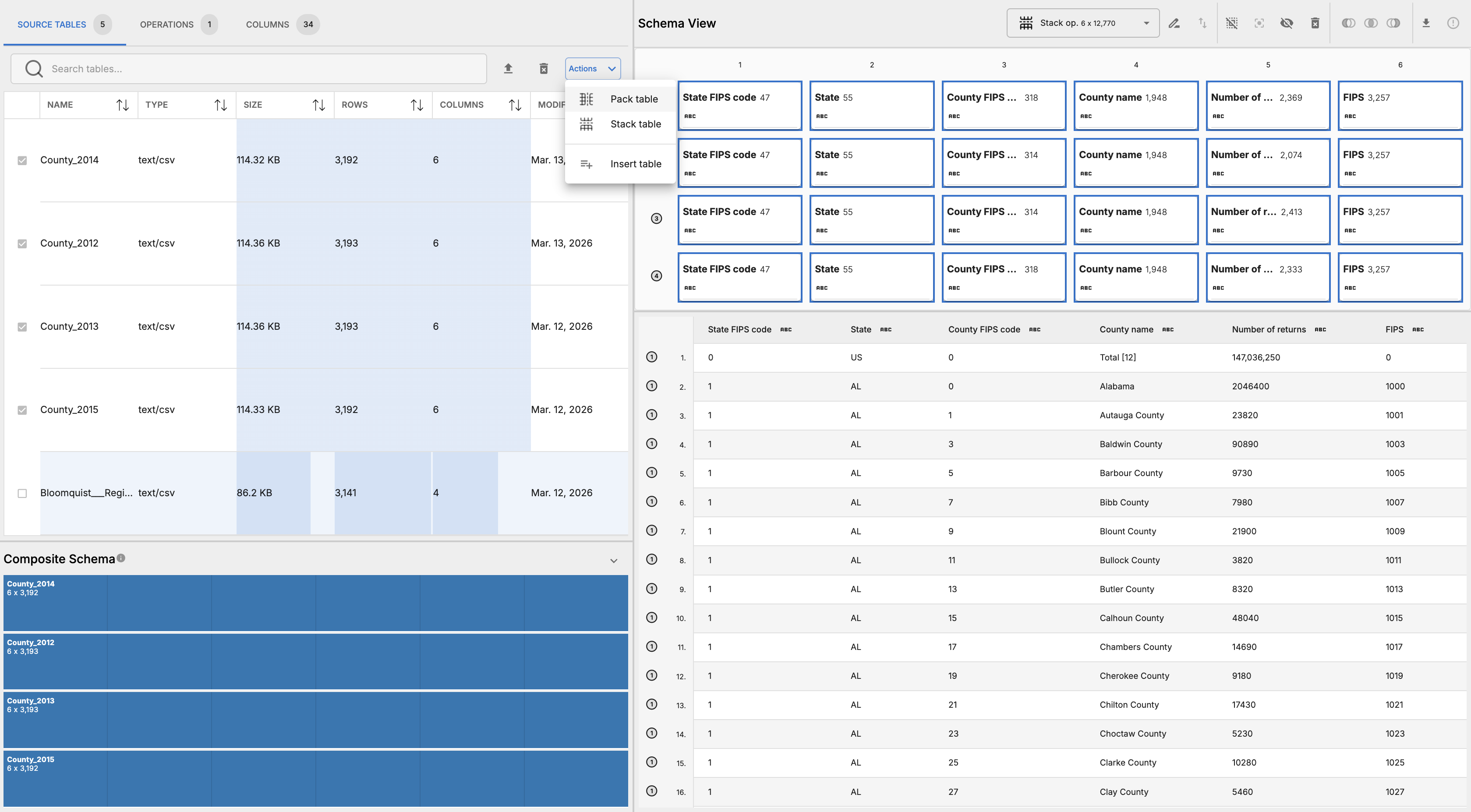 .
. - Create a pack operation joining the stacked county filings to the Bloomquist audit data on the combined FIPS code column, using a left join.
- Update the pack operation parameters such that the match columns are “FIPS” in both tables and the match condition is EQUALS.
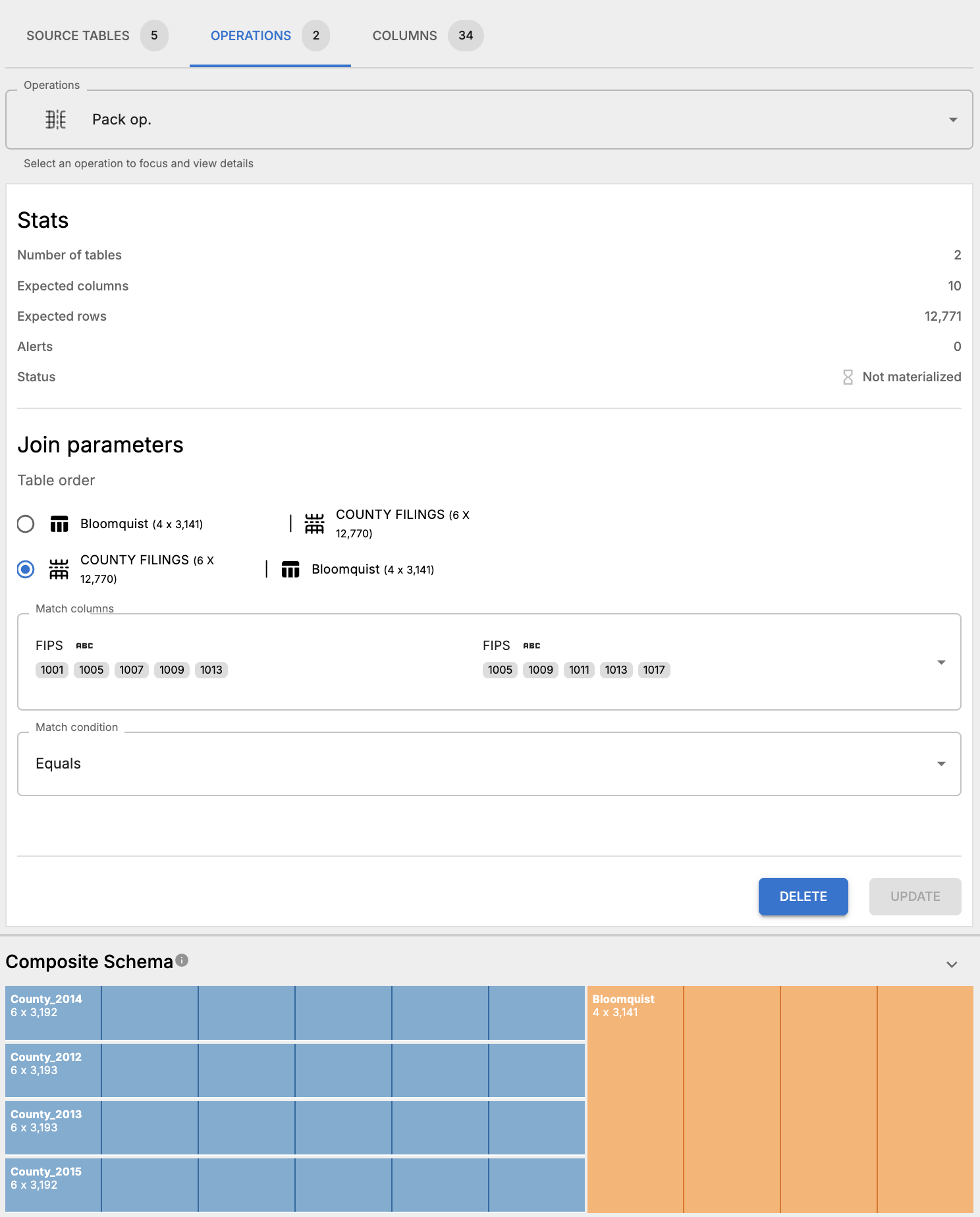
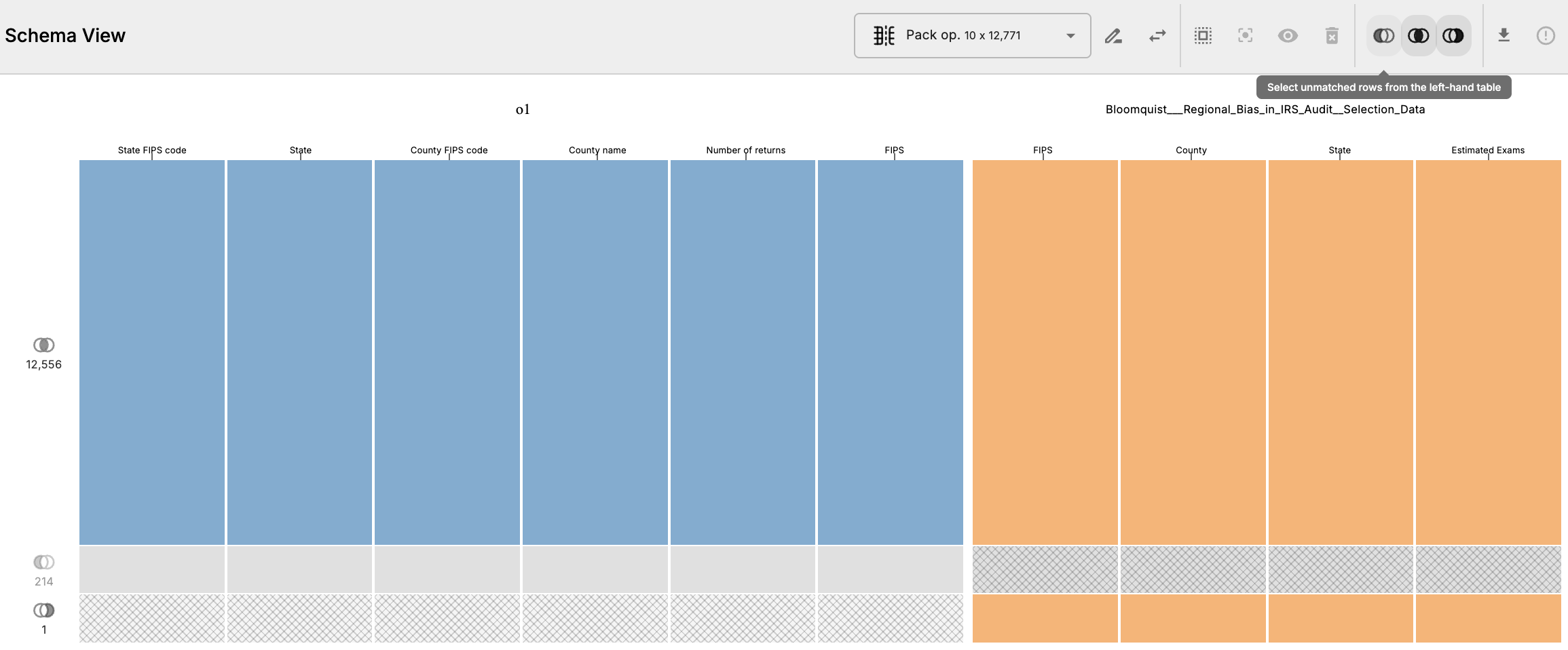
- Materialize the pack operation and inspect results. There’s one row in the Bloomquist table that doesn’t have a match in the county filings table. That row belongs to the District of Columbia, where in the Bloomquist table the FIPS code is
11001. When we look through the county filings table, we see that the FIPS code for the District of Columbia is11000. This is a common issue when working with data from multiple sources — sometimes there are slight discrepancies, but OpenRoundup can surface these issues to the user. In this case, we can fix this by updating the FIPS code in all the county filings tables.
- Likewise, there are more than 200 rows in the county filings table that don’t have a match in the Bloomquist table. Clicking the left-margin label for this partition into the table selects all the columns in the tables at this location, which makes it easy to inspect the unmatched rows. In the table below, we can see that these unmatched FIPS codes are from state totals present in the county filings table
 .
. - Update the match selection and toggle off the left-only match group (left-shaded venn diagram) exclude these unmatched rows
 .
. - Rematerialize the pack operation. The resulting table will now exclude those rows.
- Now we can export the final materialized table as a CSV. This table can be used to calculate the number of audits per capita by county, which was the main analysis for the original story.