Benchmark
The source code can be downloaded here:
- Benchmark (GitHub)
- External baselines (GitHub)
- Scalable cluster on Google Cloud Compute
- To be updated soon.
For more details, please refer to our paper.
Structure
This page briefly summarizes what the benchmark can do, and what it measures. For set-up and runtime instructions, please refer to the documentation on GitHub. For instructions about participating in the challenge (which does not require running the benchmark, other than for hyperparameter tuning in the validation set, if so desired), please refer to the submission page.
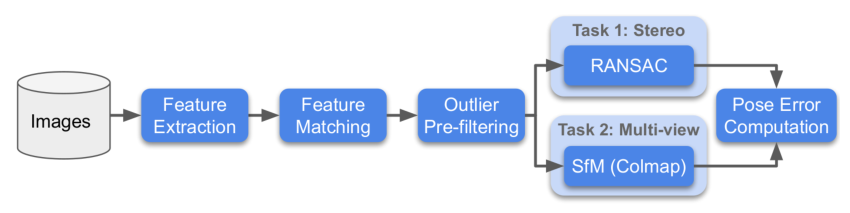
Our pipeline contains the following blocks:
- Feature extraction
- Feature matching
- Outlier pre-filtering (disabled for the challenge)
- Performance evaluation on downstream tasks
- Stereo task
- Multi-view task
In the first stage, we extract features (keypoints and descriptors) for every image in a scene. In the second stage, we use them to generate a list of putative matches for every pair of images. The outlier filtering step embeds deep networks for correspondence estimation; currently we make available Context Networks inside the benchmark. These matches are then given to a stereo task (e.g. RANSAC) and a multi-view task (Bundle Adjustment), which run separately.
These components often interact in unforeseen ways. They need to be tuned one at a time, and are hard to evaluate with intermediate metrics, which requires implementing the entire pipeline and embedding baseline methods in it. We believe this is the first benchmark to provide an integrated solution to this problem. It can be used to evaluate any of the following:
- Local features. We provide wrappers around OpenCV feature extractors, which can be called directly by the benchmark. We also provide wrappers around several state-of-the-art feature extractors in the baselines repository, which can be easily imported into the benchmark. This includes both patch descriptors such as HardNet and end-to-end feature extractors such as SuperPoint or D2-Net.
- Matchers. Simple strategies like enforcing bidirectional consistency or filtering by the ratio test or with a distance threshold are typically required for optimal performance. We implement several of these and make them available.
- Stereo. In addition to OpenCV RANSAC, we provide wrappers for state-of-the-art RANSAC variants, such as GC-RANSAC, DEGENSAC, and MAGSAC, which provide performance gains over 10% relative.
- Integrated solutions. There is a strong drive in the research community towards true end-to-end solutions, that is, incorporating both feature extraction and matching. We thus let participants send the final list of matches, which is given directly to the different tasks.
Task 1: Wide-baseline stereo
In this task we simply match two images across wide baselines. Image pairs are selected according to (loose) co-visibility constraints so that at least part of the scene is guaranteed to overlap. To do so we compute a simple co-visibility estimation based on the size of the bounding box containing all the reconstructed points co-visible for every possible pair of images, which we then threshold to generate lists of valid pairs of increasing difficulty. We typically consider about 4-5k image pairs per scene.
Our main evaluation metric is the quality of the estimated poses. We measure them in relative terms, as stereo poses can be recovered up to a scale factor. To measure the accuracy for a given pair of images, we compute the angular difference between the estimated and ground truth translation vectors, and between the estimated and ground truth rotation vectors, and take the largest of the two. We threshold this error to reach a binary decision, e.g. is this estimate accurate at X degrees, and accumulate it over multiple image pairs to compute the "average accuracy". We do this for multiple error thresholds, from 1 to 10 degrees, with a 1-degree resolution. Finally, we compute the area under this curve: this provides a single scalar value that we call "mean Average Accuracy" or mAA, analogously to the mean Average Precision or mAP commonly used in object detection.
Additionally, we compute traditional metrics such as keypoint repeatability or descriptor matching score. As many modern local feature extractors do not have a clear notion of their support region, we compute them from keypoint locations only, using the ground truth depth maps to determine valid/invalid correspondences across images. Note that while generally accurate, we cannot rely on them for sub-pixel accuracy, and they are constrained to non-occluded areas.





Task 2: Multi-view reconstruction from image subsets
Recent, learned methods have shown promising results in stereo, but it is not clear whether this translates after large-scale reconstruction with Bundle Adjustment. We thus propose to evaluate SfM directly, as previously done for instance by the Comparative Evaluation Benchmark. Unfortunately, it is not feasible to obtain truly accurate depth measurements for large-scale image collections from heterogenous sensors, and under most circumstances the best we can do is collect statistics such as the number landmarks, their track length, or the reprojection error.
By contrast, we propose to build SfM reconstructions with Colmap from small (5, 10, 25) subsets of images, which we call bags, and use the poses obtained from the full collections as ground truth. Specifically, we subsample each scene to 100 images and, from them, generate sets of 5 images (100 of them), 10 images (50 of them), and 25 images (25 of them), sampled at random from the 100-image subset (enforcing a minimum degree of co-visibility between the images).
This task is evaluated with the same metric we proposed for stereo, averaged over every pair of images in a subset (e.g. 10 pairs for one bag of size 5, 45 for one bag of size 10, and 300 for one bag of size 25). We believe that this provides a better proxy metric to evaluate feature extractors and matching algorithms than what has been used in previous efforts. Note that this penalizes reconstructions that fail to register images. If Colmap generates multiple 3D models which cannot be co-registered, we consider the largest one (the one with the most images).







