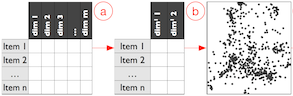
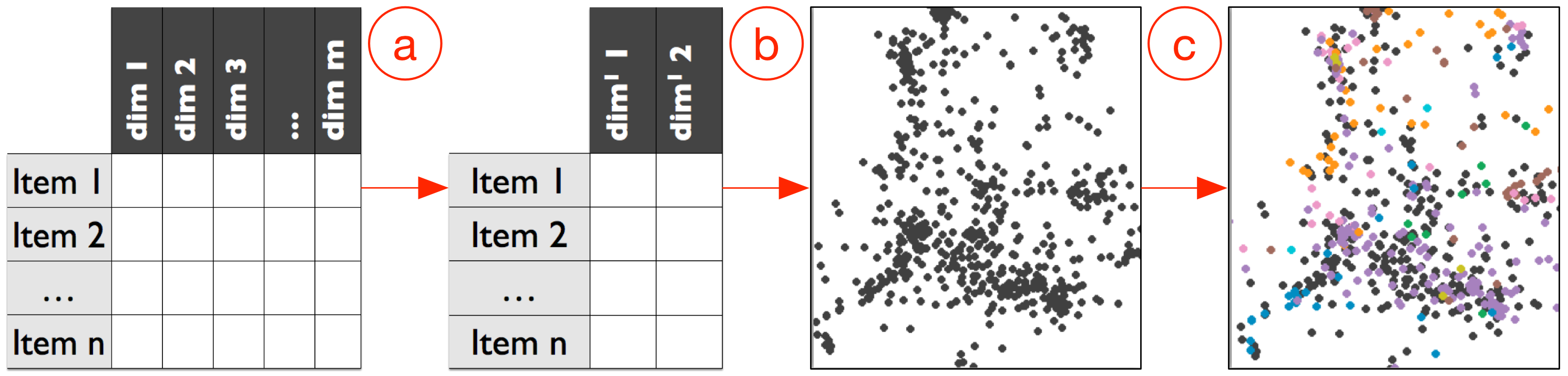
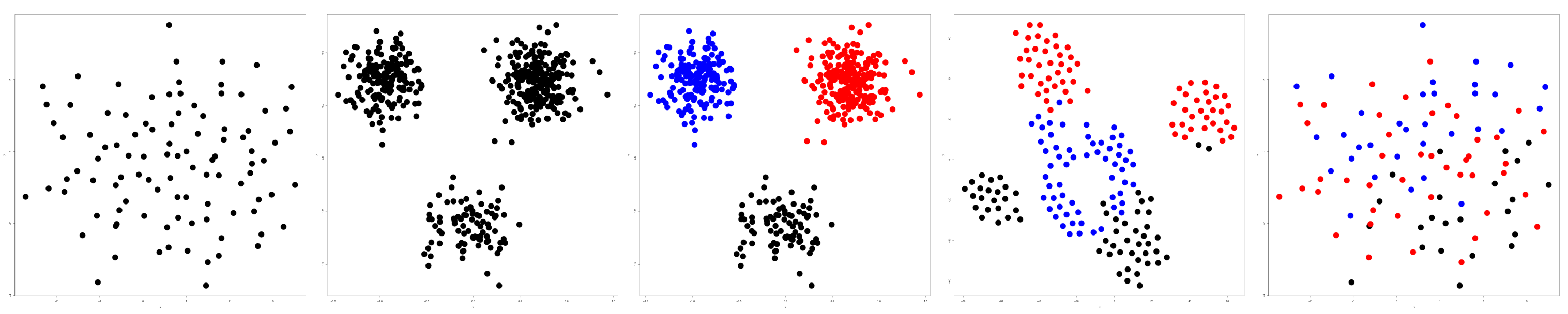
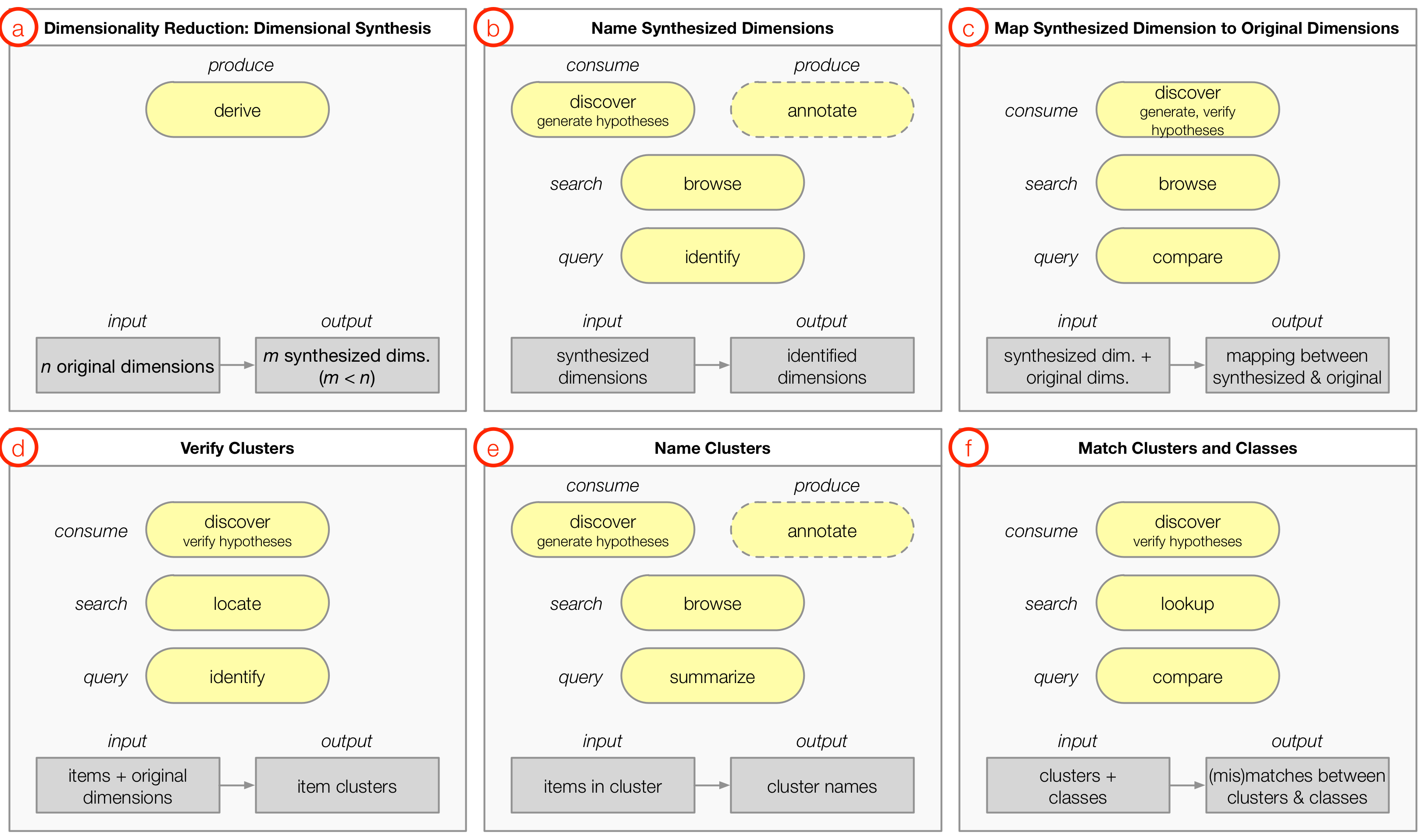
Visualizing Dimensionally-Reduced Data: Interviews with Analysts and a Characterization of Task Sequences
Abstract |
Paper |
Talk |
Figures |
Supplemental Material
Abstract
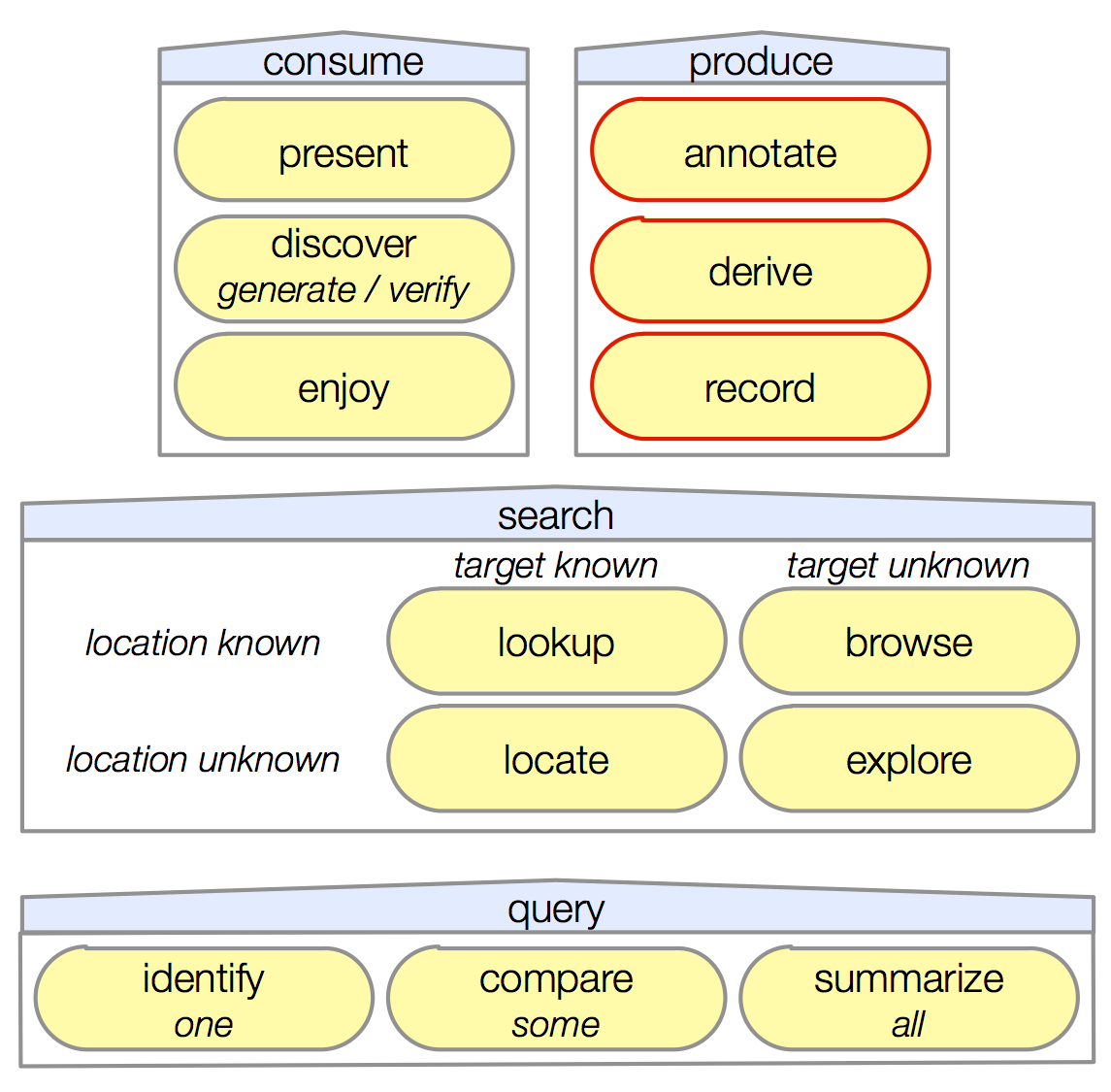
We characterize five task sequences related to visualizing dimensionally-reduced data, drawing from data collected from interviews with ten data analysts spanning six application domains, and from our understanding of the technique literature. Our characterization of visualization task sequences for dimensionally-reduced data fills a gap created by the abundance of proposed techniques and tools that combine high-dimensional data analysis, dimensionality reduction, and visualization, and is intended to be used in the design and evaluation of future techniques and tools. We discuss implications for the evaluation of existing work practices, for the design of controlled experiments, and for the analysis of post-deployment field observations.
Paper
Visualizing Dimensionally-Reduced Data: Interviews with Analysts and a Characterization of Task Sequences
Talk
This paper was presented on Monday, Nov. 10, in the
"Rethinking Evaluation Level: Abstracted Task vs In Situ Evaluation" session of
BELIV 2014.
→
Slides (3 MB PDF)
→
Slides (13 MB Keynote)
→
Video (8 MB MP4)
High-Resolution Figures
Click on a Figure to open in a new tab.
Supplemental Material
Further reading:
Matthew Brehmer
Last modified: Nov 26, 2014.