Research Summary
My area is parallel computing, which studies the use of multiple processors to cooperatively solve problems. Parallelism can be used to solve problems faster, to solve larger problems or to solve problems more accurately. We are seeing a dramatic shift towards parallel computing and it will become essential in industry and science to remain competitive. I work on MPI middleware and in particular the problem of hiding communication latency. Exposing parallelism and latency tolerance go hand in hand and these two concepts are fundamental to portability and scalability of message-passing programs. Advances in networking has now made a "compute-anywhere" model attractive and my most recent work on MPI middleware has been on commodity networks using standardized transport protocols.
If you are interested in grad school and working with me in this area please make sure you submit your application for admission to graduate studies (see department website www.cs.ubc.ca). The usual time for admission is in December, applications are reviewed in the spring with offers going out at that time. If you are an undergraduate student interested in these topics come see me. I very open to single projects and group projects having to do with parallelism, cluster computing, and analytics.
Interests
- Message-Passing Systems
- Scalability
- Low latency communication
- Programming with millions of processes
Research Projects
-
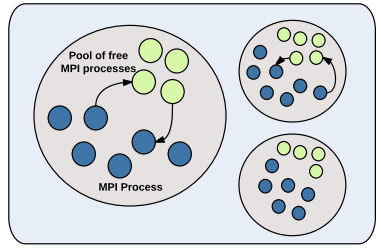
FG-MPI is an ongoing project with Dr. H. Kamal, now at LUMS. .
a version of MPI that extends the MPICH2 middleware with added concurrency; making it possible to execute several MPI processors inside a single OS-process. The FG-MPI project builds upon prior expertise we had with the MPI middleware, namely the design of MPI middleware for the SCTP. SCTP is a new transport protocol with features that make it well-suited for MPI. More information about the FG-MPI project can be found in the following location. (read about our latest work on scaling to 100 Million MPI processes with FG-MPI here )
-
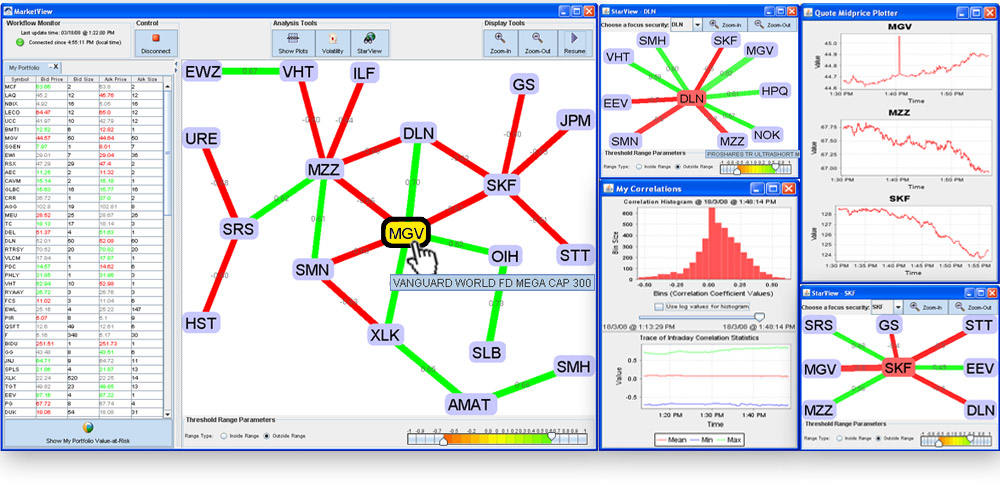
.
There are two main projects that are currently active. The first is the development of a parallel programming infrastructure to support interactive parallel data mining. This work is based on the premise that data mining is more effective when the user can participate in the discovery process and that the user must be part of the data mining loop to enable them to guide the process. However, data mining is both data and compute intensive and parallel computing, in particular cluster computing, is a useful tool to achieve the response times necessary to make this approach feasible. We have focused on three datamining activities: calculation of correlation matrices, datacube querying, and cluster analysis.
Our most recent work in this area has been in using correlation matrix calculation and stochastic search to cluster data for online exploration of large datasets. We are currently investigating the use of these techniques as a online financial analysis tool using stock market data. This is joint work with Camilo Rostoker and Holger Hoos.
Past work has focused on robust correlation matrix calculation. We have implemented a version of parallel QC and a more robust technique based on Maronna's method. We have been able to obtain significant speed-ups in local area networks and compute clusters such as WestGRID. We have managed to effectively use almost 256 processors to calculate correlation matrices of up to 30,000 variables in several minutes. We are currently integrating our algorithm into a interactive tool to allow researchers to explore the correlations of large datasets There are two other important aspects to this project:a) It is an open system to allow the addition of new tools and the ability for these tools to interact.
b) It supports the interactive mining of large datasets. A result of this goal is that the algorithms must at any time be able to respond with the "current best" result from the algorithm even after reading only a portion of the data. The user can adjust the response time of the algorithms to give partial results to make decisions on future explorations.
Currently we have a prototype of the tool running to support the three above mentioned datamining activities.
-
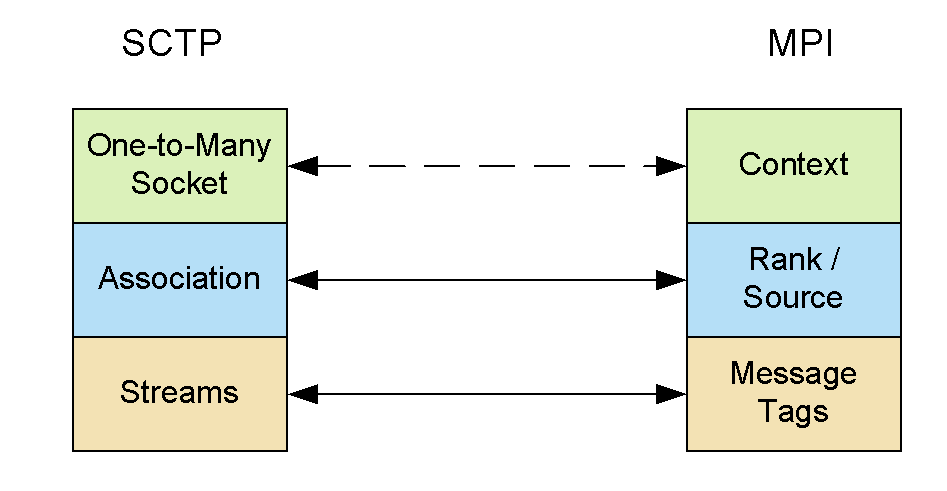
We were the first group to explore the use of SCTP (Stream Control Transport Protocol) for MPI (Message Passing Interface) middleware. SCTP is better suited for MPI because, unlike TCP, it is message-based and comes with many other features for multi-homing, multi-streaming and fault tolerance that does not exist in other transport protocols. This made it possible to push MPI functionality down to the transport layer and take advantage of the fault-tolerant and multi-streaming features of SCTP. This work introduced SCTP as an alternative to the commonly used TCP network interface.
Our work with Cisco and Argonne National Labs was instrumental in obtaining a Cisco University Research Award of $60,000 for research in using SCTP and MPI for cluster computing. This support allowed us to fully integrate our SCTP-based middleware into MPICH as part of its official release. In addition we have worked with Jeff Squyres group, who is the technical lead for the Open MPI project, to integrate SCTP into OpenMPI.
Our work also contributed to the development of SCTP. First, it provided a rich collection of programs (i.e. MPI programs) that could use SCTP. Second, it made aggressive use of SCTP features with large number of machines passing millions and millions messages. As a result, our middleware provided a good test environment for SCTP, which in turn led to improvements in the KAME-SCTP stack for FreeBSD (and Cisco IOS). Changes we suggested have already made their way into SCTP to become standardized by the IETF (Randall Stewart is the IETF lead for SCTP). The extension of KAME to user-space was part of B. Penoff’s PhD in collaboration with Michael Tuexen, Irene Ruengeler (who was a post-doc visitor in 2010) and H. Kamal.