|
I am a fifth-year PhD student at the University of British Columbia, supervised by Frank Wood. Previously I've interned at Google DeepMind and studied for an MEng in Engineering Science at the University of Oxford. My research focuses on generative modeling, especially with diffusion models. I investigate applications both in the video domain and for problems with more explicit structural information. Email / Google Scholar / CV |

|
|
|










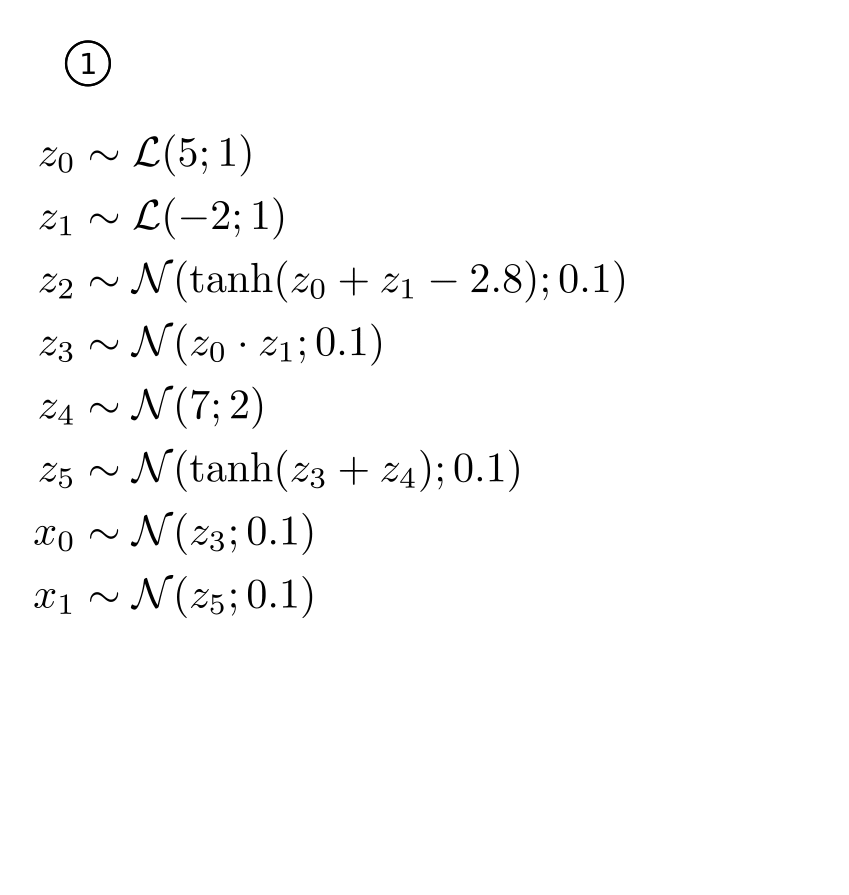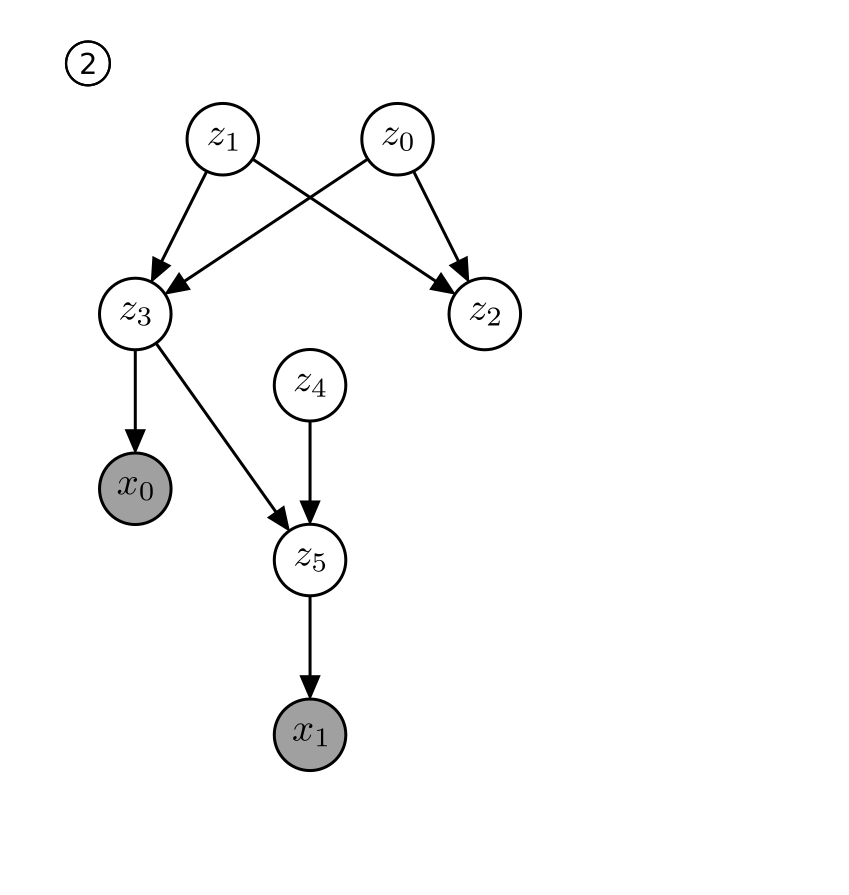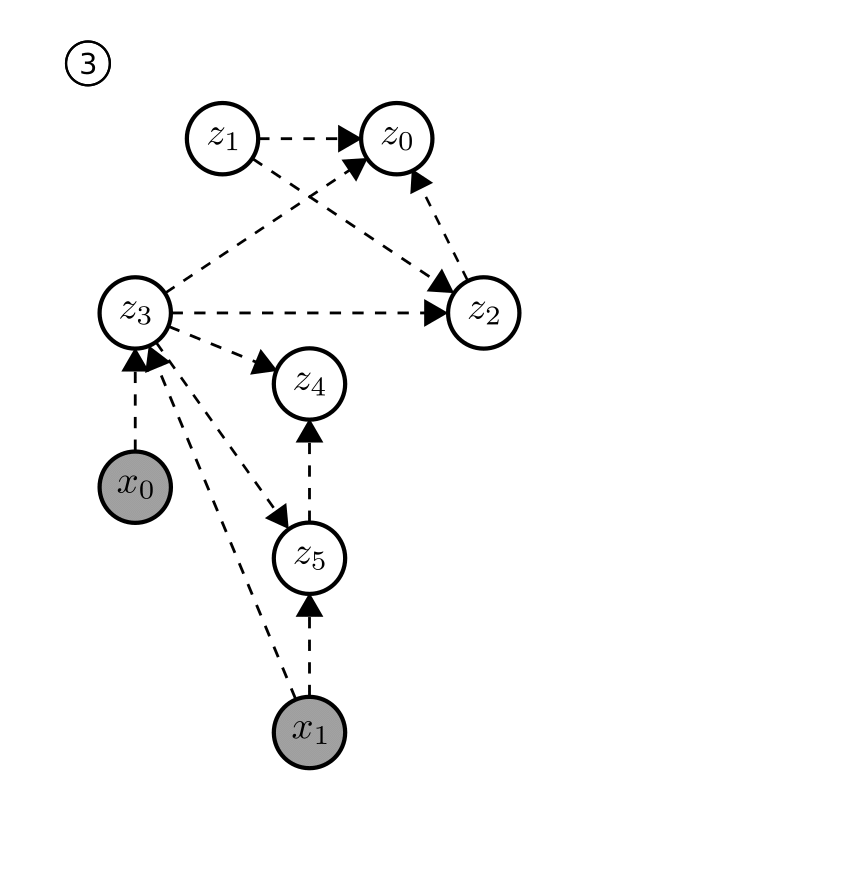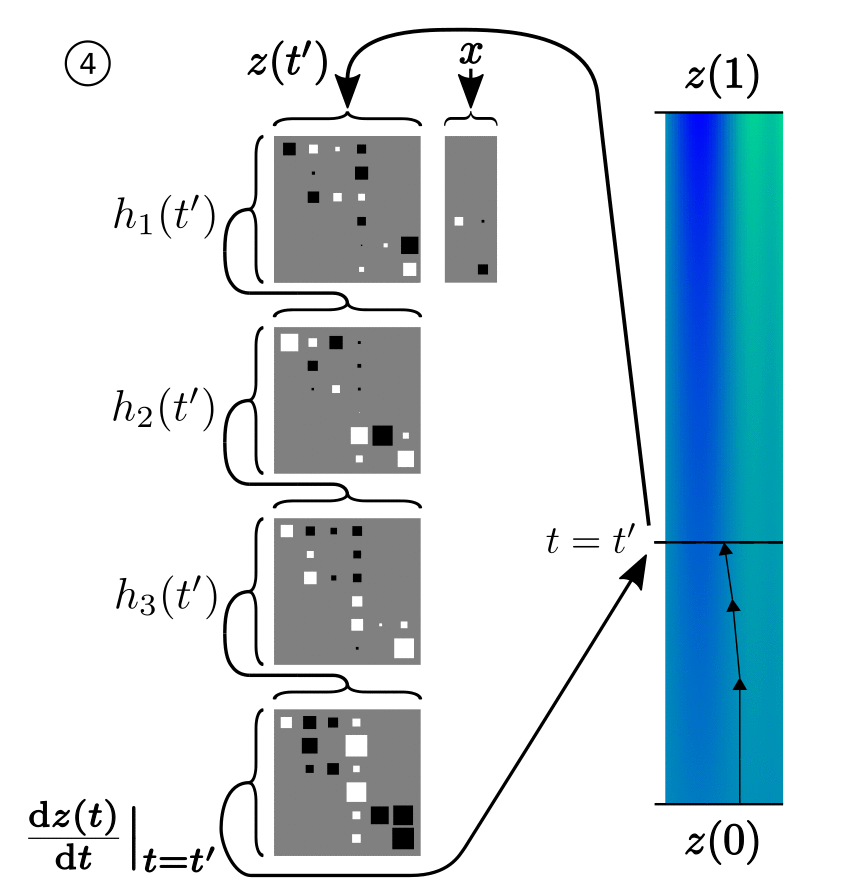


|
Website source forked from Jon Barron. |