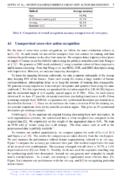
Publications
A. Gupta, A. Shafaei, J. J. Little and R. J. Woodham. Unlabelled 3D Motion Examples Improve Cross-View Action Recognition. In BMVC, 2014.
[PDF]
[Poster]
[Abstract]
[BibTeX]
@inproceedings{Guptaetal14,
author = {Gupta, A. and Shafaei, A. and Little, J. J. and Woodham, R. J.},
title = {Unlabelled 3D Motion Examples Improve Cross-View Action Recognition},
booktitle = {Proceedings of the British Machine Vision Conference},
year = {2014},
publisher = {BMVA Press},
url = {http://cs.ubc.ca/research/motion-view-translation/}
}







Abstract
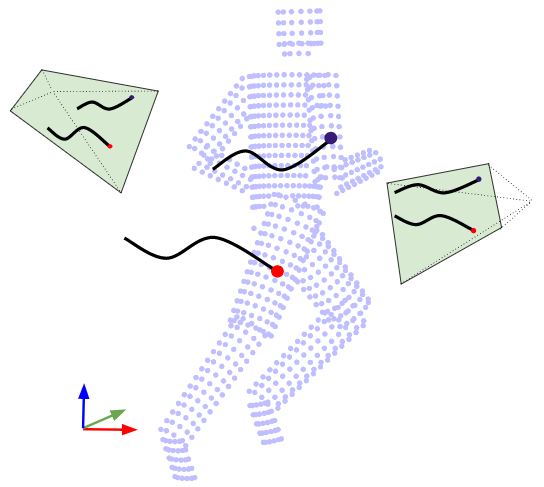
We demonstrate a novel strategy for unsupervised cross-view action recognition using multi-view feature synthesis. We do not rely on cross-view video annotations to transfer knowledge across views but use local features generated using motion capture data to learn the feature transformation. Motion capture data allows us to build a feature level correspondence between two synthesized views. We learn a feature mapping scheme for each view change by making a naive assumption that all features transform independently.
This assumption along with the exact feature correspondences dramatically simplifies learning. With this learned mapping we are able to "hallucinate" action descriptors corresponding to different viewpoints. This simple approach effectively models the transformation of BoW based action descriptors under viewpoint change and outperforms the state of the art on the INRIA IXMAS dataset.
Results
We achieve the state-of-the-art performance of multi-view action recognition on the IXMAS dataset.
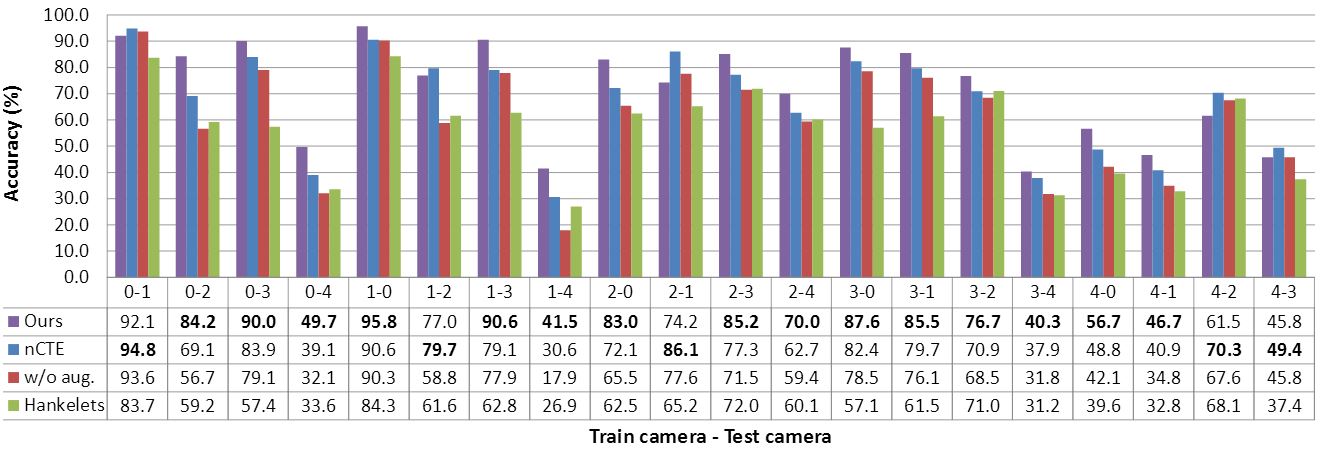
Accuracy comparison per train-test view pair. We compare with nCTE [1], our method without augmentation, and Hankelets [3].
Code and Data
- Fork the source code at github.com/ashafaei/bow-translation.
- Download the dataset from here.
You can also download the dataset with the provided script in the source code.
References
- Ankur Gupta, Julieta Martinez, James J. Little, and Robert J. Woodham. 3D Pose from Motion for Cross-view Action Recognition via Non-linear Circulant Temporal Encoding. In CVPR, 2014.
- Heng Wang, Alexander Klaser, Cordelia Schmid, and Cheng-Lin Liu. Action recognition by dense trajectories. In CVPR, 2011.
- Binlong Li, Octavia I. Camps, and Mario Sznaier. Cross-view Activity Recognition using Hankelets. In CVPR, 2012.