416 Distributed Systems: Assignment 4 [Caching for distributed PoW]
Due: March 14 at 11:59pm PST
Winter 2021
Results from a (distributed) computation may be cached to eliminate redundant computation in the future. Caching is a standard optimization technique in distributed systems and you will use caching to enrich your PoW implementation. In this assignment you will add a distributed caching mechanism to your distributed PoW system in A3. The workers and the coordinator will cache previously computed secrets. The coordinator will return a cached result to clients if a cached result is available.
Changes since @382, initial assignment release
Last Modified: Thu 11 Mar 2021 15:55:35 PST
- @450, @451
WorkerCancelshould be repeated per relatedFoundRPC, not at-most-once perWorkerMine, as previously suggested. - @442 Corrected the one-worker diagram to have the correct CacheHit and CacheMiss actions at the coordinator; added two clarifying notes to the diagram.
- @411 Corrected
CoordinatorWorkerCancelspec: it should appear once per(WorkerByte, secret)tuple. - @405 Updated the two diagrams with Found/Result concurrency to
include
b1sec1return to powlib from coordinator at end of the coordinator timeline, after all the relevant coordinator/worker actions. This illustrates that All other coordinator and worker actions in this trace must happen beforeCoordinatorSuccess. - @404 Updated all RPC calls to include a tracing token as part of the returned value, and expanded on the distributed tracing section to illustrate how to generate two tokens: at the caller (for token argument to RPC) and at the callee (for token return value from an RPC).
- @403 go.mod update for latest version of tracing lib (v0.0.0-20210307092023-9172fa1dd33e)
- @398 fixed diagram typo
- @395_f1 removed old text related to coordinator creating tracing
Overview
This assignment's objective is to introduce you to distributed (cache) state and protocols for managing this state. You will learn:
- How to use distributed tracing
- How to reason about eventual consistency semantics of distributed state
By using independent processes that communicate over the network, your system may now experience partial failures. For example, one process may crash, or the machine it is running on may be powered off, while other processes in the system will continue to execute as usual. This assignment is a stepping stone towards recovering from such failures. A feature of distributed caching is that caches can be used to speed up recovery and help nodes reconstruct their state after a failure. However, you will not deal with failures in this assignment. We leave it to you as an exercise to consider how you might go about building such a protocol.
You will retain most of the features of A3: node roles, powlib API, distribution of the computation across workers, and many constraints like the order in which nodes are started. A4 does, however, introduce several important changes: coordinator RPC APIs will be changed, worker RPC APIs will be changed, of course A4 introduces caches and caching semantics, the recorded actions will be expanded, and finally we'll add distributed causal tracing. Distributed tracing will, in fact, be the reason for most of the API changes.
Distributed tracing
We begin with a description of distributed tracing because this will be a powerful new tool in your debugging toolbox. You will also use distributed tracing in A5 and A6, so it's a good idea to understand it well.
So far we have been relying on the tracing library to record actions at nodes in our system. These actions were associated with one another through concrete values (e.g., workerBytes) that they sometimes included. Distributed tracing, which is now available in the same tracing library, introduces two new features: (1) the notion of a trace with which recorded actions are associated, and (2) vector clock timestamps to track the happens-before relationship (if any) between actions across nodes. These two features require a different API and a slightly different way of thinking about tracing in your system.
A trace is a set of recorded actions that are associated with
a unique trace ID. Previously, your code could record actions at any
point in time. With traces, actions must be recorded as part of
traces. So, you must now first get access to a trace and then you
can record an action
(Trace.RecordAction(action)). There are two ways in
which your code can get access to a trace instance: (1) create a new
trace with a unique ID, and (2) receive an existing trace from
another node.
In A4 traces will be created by powlib (Tracer.CreateTrace()). The powlib library will generate a new trace for each client API call that it receives. The intent is to associate all the actions that are related to servicing a particular client call (across all the nodes) with a single unique trace.
Once a trace is created at a powlib instance, if another node
wants to associate actions with this trace, then the node must gain
access to the trace instance. For this, a trace must be serialized
into a token, which can be sent to another node, at which
point the receiving node can reconstruct the trace instance from the
token. You will typically serialize a trace multiple times since
every token must be unique and a trace created by powlib will
span several nodes. More concretely, to generate the token from the
current trace your code would call
Trace.GenerateToken(), which will return a token. Your
code can then include this token as an argument in an RPC invocation
(one reason why the RPC APIs must be updated in A4). On receiving an
RPC with a token, the node can reconstruct the trace by
calling Tracer.ReceiveToken(token) on the received
token. Note that this token generation/receipt must be done for
every RPC invocation; think of it as an addition to the RPC protocol
that you now have to follow.
For a detailed description of the distributed tracing API, please see the go doc documentation for the tracing library.
End-to-end example of distributed tracing + ShiViz
A key feature of distributed tracing is that now all actions include not just physical timestamps but also vector clock timestamps. These vector clocks timestamps allow us to reconstruct the happens-before relation between recorded actions. This relation will look like a DAG with vertices associated with different nodes in your system. The tracing library's output supports a visualization tool, called ShiViz, that you can use to visualize the recorded DAG of events.
Let's consider a simple example. This example consists of a client and
a server. The client invokes an RPC on the server and then the server
returns the response to the client. You can find the
implementation here. This
implementation also illustrates how to use the distributed tracing API
described above. To run this example, you can run go run
main.go from the example/client-server directory.
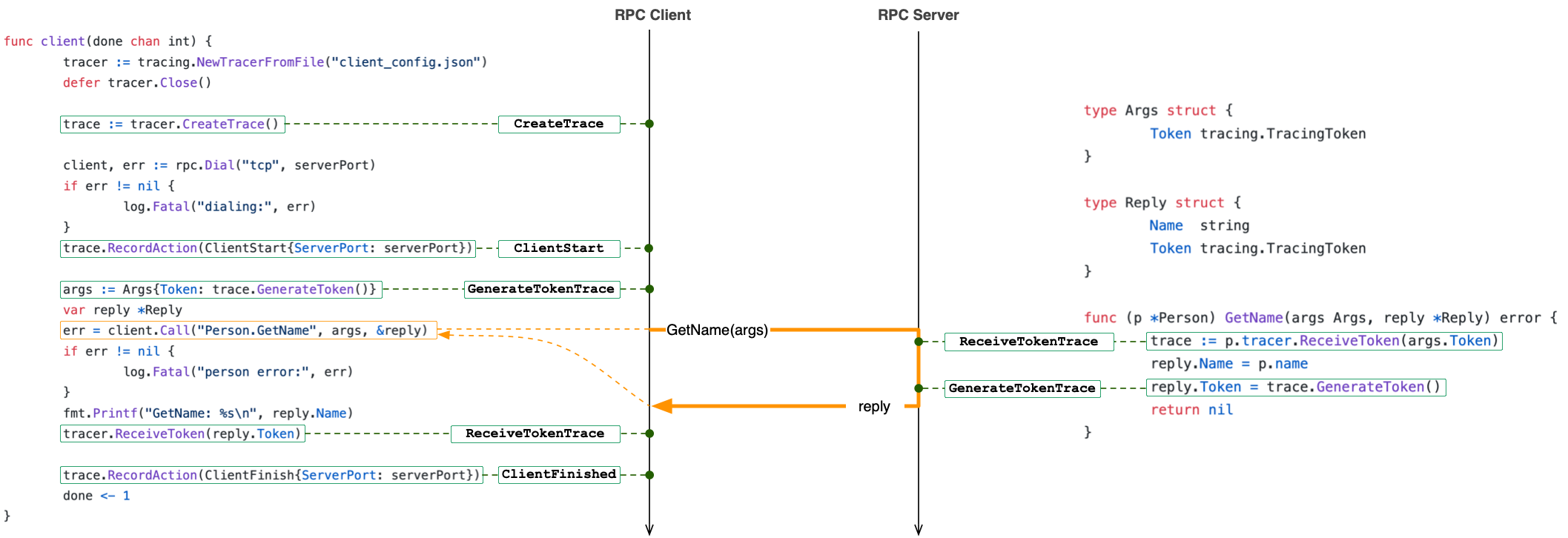
Notice the use of distributed tracing
in main.go
of the above example. The caller generates a token, passes it to
the GetName RPC function as part of the Args
struct. The callee runs GetName RPC and in the line just
before returning generates a return token (ret-token in the RPC
specs below) and returns this token as part of its return value in
the Reply struct. The two tokens, one in the forward
direction and one in return direction, allows us to reconstruct the
happens-before partial ordering of the distributed execution. The
diagram below illustrates this in more detail:
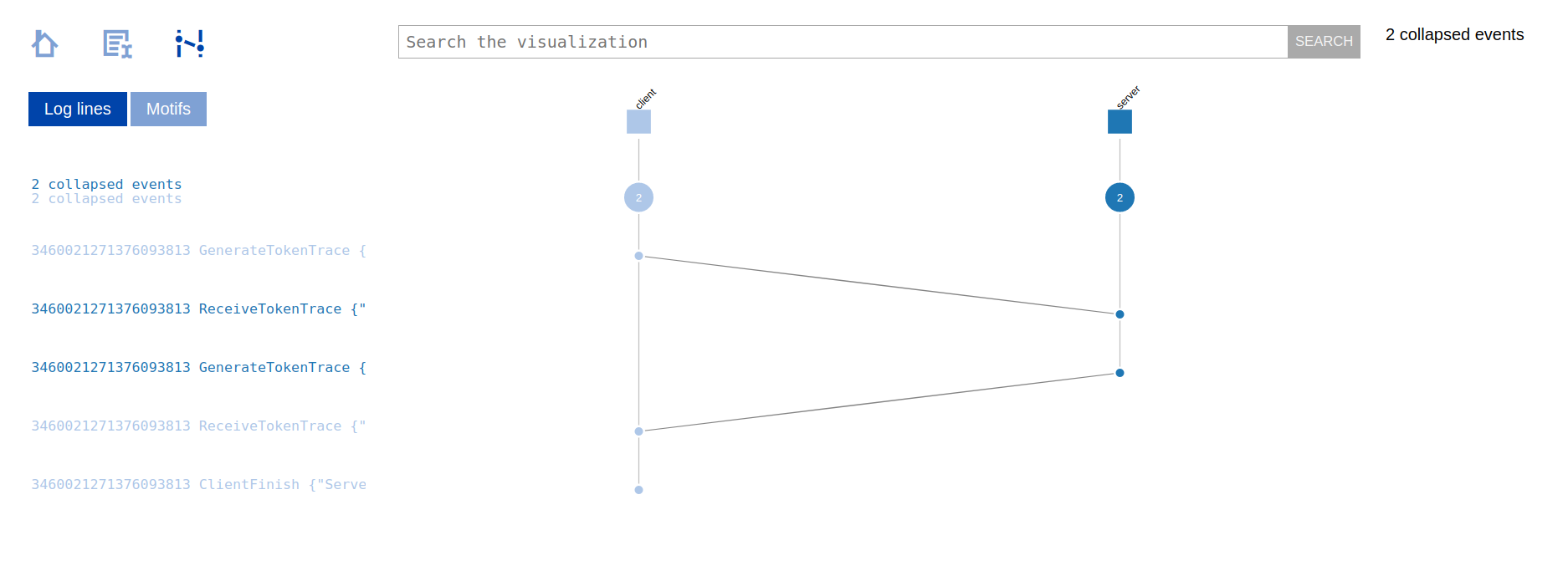
The updated tracing server also generates a ShiViz-compatible log that can be used with ShiViz to visualize the execution of the system. This log file is defined in the tracing server configuration file as ShivizOutputFile, which has the "shiviz_output.log" value by default.
We can upload the generated ShiViz log, i.e., shiviz_output.log, to
the ShiViz online
tool. For this, click on the blue "Try out shiviz" button and
select a file to upload, choosing your local shiviz_output.log
file. You should then see the following diagram that you can interact
with:
Caching proof-of-work results
The coordinator and all workers in A4 will have a local cache. This cache can be modelled as a dictionary that maps keys to values. Initially the cache is empty. As the system runs, the cache grows. A real cache needs a size limit, but in this assignment we will assume that a cache can grow indefinitely.
Below is a diagram that illustrates how your A4 system will operate
with one worker and several client requests. The cylinders in the
diagram are caches at the coordinator and the worker. A cylinder has
a version, like V0 at the start. These version numbers are used in
the diagrams below for explanatory purposes. You do not need to use
these in your A4 implementation, and we recommend that you avoid
explicitly versioning cache contents. The caches in the diagrams may
also have some contents, either empty {} or some number
of key:value pairs like {n1,t : bsec1} which maps the
key
(n1,t) to the secret bsec1. More
precisely, the key (n1,t) represents a nonce n1
and t trailing zeroes while bsec1 represents the
corresponding secret. Note that the cache does not explicitly keep
track of worker bytes: any worker bytes b that were
used by a worker to compute the secret sec1 must be stored as
a prefix of the value bsec1 in the cache.
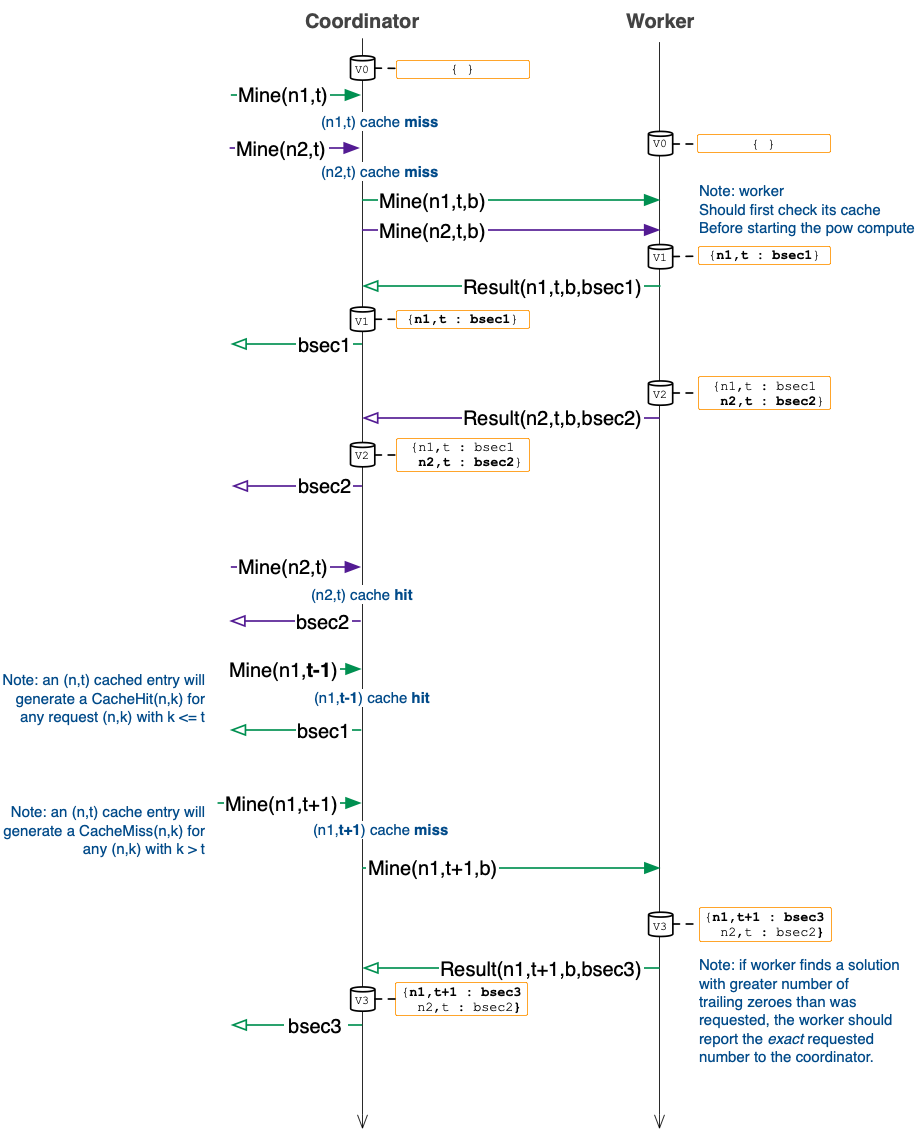
A couple of key aspects to note about the above execution/diagram:
-
In A3 we explicitly disallowed powlib instances from issuing an
RPC
Mine(n,t)multiple times. This is no longer true. Instead, we weaken the constraint to the following: powlib instances cannot issue two instances ofMine(n,t)concurrently. In other words,Mine(n,t)can only ever be issued if anotherMine(n,t)is not currently issued and blocking on a result at the coordinator. - The cache is updated at the worker when the worker computes a proof of work. Likewise, the cache is updated at the coordinator when the coordinator receives a proof of work result from a worker. Note that with more workers the semantics of cache updates get more complex (more on this below).
- Notice how the cache is first updated at the worker and then later at the coordinator. Also notice that eventually the cache at the coordinator becomes identical to that of the worker. This is not a coincidence: the caches in A4 will have eventually consistency semantics (technically the cache is a CRDT).
-
There is a notion of a cache hit and a cache
miss. If there is a cache hit, then no proof of work
computation is done. Note that if the cache
contains
{n1,t : bsec1}then there will be a cache hit for key(n1,t-1)(e.g., client request #4 in the diagram). - A cached entry for key
(n1,t)must be removed from the cache when an entry for key(n1,t+1)is added. This is a natural outcome of the above bullet (i.e.,(n1,t+1)subsumes(n1,j)for anyj < t+1). - For clarity, the diagram omits actions and distributed tracing details. For example, all the RPCs listed below include a tracing token as an input, and also return a tracing token as part of the returned value.
As we add more workers, we have to consider the state of more caches. The diagram below illustrates what happens with two workers in the case that worker1 computes the proof of work before worker2.
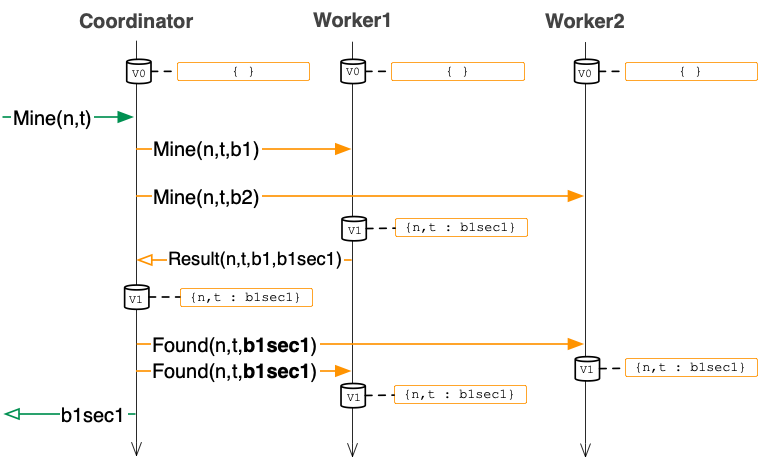
The above execution illustrates the following:
-
There is no longer a
CancelRPC. Instead, there is a new RPC calledFound. This call has similar behavior toCancelin A3: the worker should cancel its local proof of work computation for(n,t,b)when it receives aFound(n,t,b1sec)RPC. But, theFoundis also a way for the coordinator to update the cache at the worker, so unlike aCancelRPC, aFoundcarries with it the secret (b1sec1 above). -
Notice that
Found(n,t,b1sec1)sent to worker1 is redundant since worker1 already has its cache updated to include this information (and the coordinator knows this fact). For this reason the first diagram above omits theseFoundmessages. It is a small optimization that you can introduce in your A4 solution, if you wish. -
As in the first diagram, notice that the caches across the three
nodes eventually have identical contents:
{n,t : b1sec1}.
In the above two worker execution scenario, worker1 beats out worker2 in finding the secret faster. But, what if worker1 and worker2 both found the secret at about the same time? The diagram below illustrates this case:
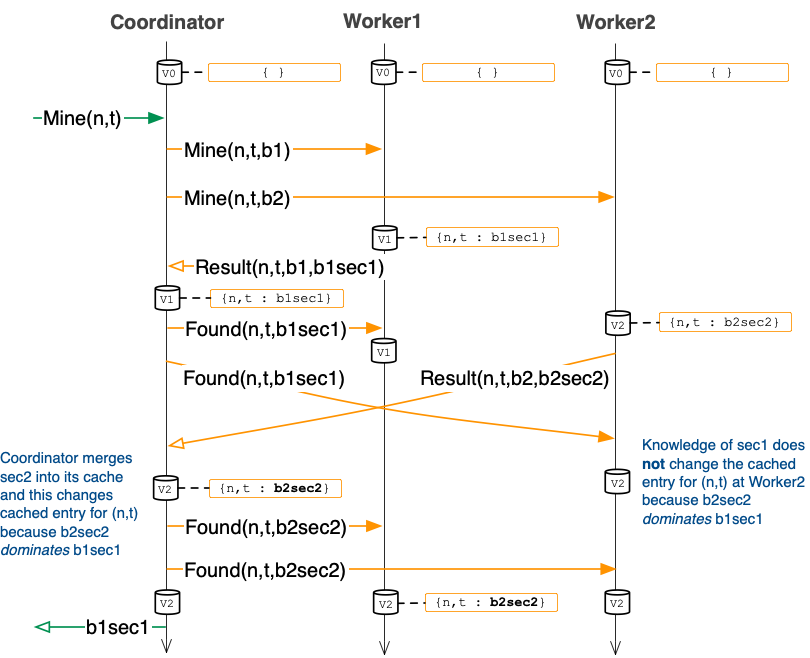
This execution illustrates the following:
-
There are two independent secrets computed
for
(n,t). A cache, however, can only have one entry for a key. We therefore define a tie breaking rule to resolve which of the two secrets will be associated with a key. We say that sec1 dominates sec2 if sec1 is larger than sec2 at the byte level.For examples,
[]uint8{ 192, 168, 1, 1 }dominates[]uint8{ 1, 168, 1, 2 },
because 192 is larger than 1 (compares from left to right)[]uint8{ 192, 168, 1, 1 }dominates[]uint8{ 1, 168, 1, 1, 1 },
because 192 is larger than 1 again (even if the lattersecretis longer)[]uint8{ 192, 168, 1, 1 }dominates[]uint8{ 192, 168, 1 },
because the first three bytes are the same and the lattersecretis shorter (this case will never appear in this assignment, exercise to reader: why not?)
You may find
bytes.Comparehelpful in implementing the above logic.In the above execution, because b2sec2 dominates b1sec1, worker2 does not change its cached entry, while both the coordinator and worker1 do update their cached entries for
(n,t)to be b2sec2. - The client receives b1sec1 as the computed proof of work secret. However, notice that this is different from b2sec2, which is the secret that is eventually cached by all three nodes. This means that future clients will observe b2sec2 (i.e., through a cache hit) rather than b1sec1.
powlib API
The powlib API is identical to A3. The key difference is that the powlib Mine API call must create a new distributed trace instance using Tracer.CreateTrace(). This is the only place where new distributed traces should be created.
RPC specifications sketch
Below we outline two RPC protocols that we recommend that you implement in your system. These are similar to A3, and differ in the distributed tracing tokens that are added to every RPC definition (as an argument, and also as a return value), and a Found RPC instead of the Cancel RPC. We bold the parts below where we have introduced changes. These protocols are strongly suggested. You may deviate as you wish (though, please talk to us first). You must, however, use Go RPCs for all inter-process communication in your system.RPCs powlib → Coordinator:
- secret []uint8, ret-token TracingToken ← Mine(nonce []uint8, numTrailingZeroes uint, token TracingToken)
- This is a blocking RPC from powlib instructing the coordinator to solve a specific pow instance. The token corresponds to a trace generated by powlib for a client Mine call invocation. The ret-token is the returned token that was generated by the callee just before the RPC returned.
- ret-token TracingToken ← Mine(nonce []uint8, numTrailingZeroes, workerByte uint8, token TracingToken)
- This is a non-blocking async RPC from the coordinator instructing the worker to solve a specific pow instance. The token corresponds to a trace generated by powlib for a client Mine call invocation. The ret-token is the returned token that was generated by the callee just before the RPC returned.
- ret-token TracingToken ← Found(nonce []uint8, numTrailingZeroes, secret []uint8, token TracingToken)
- This is a non-blocking async RPC from the coordinator instructing the worker to stop solving a specific pow instance. This call replaces Cancel in A3. Note that unlike Cancel, this call does not include workerBytes. Instead, secret must include a workerBytes prefix corresponding to the worker that originally computed this secret. The token corresponds to a trace generated by powlib for a client Mine call invocation that spawned the pow computation. The ret-token is the returned token that was generated by the callee just before the RPC returned.
- ret-token TracingToken ← Result(nonce []uint8, numTrailingZeroes, workerByte uint8, secret []uint8, token TracingToken)
- This is an RPC from the worker that sends the solution to some previous pow instance assignment back to the coordinator. The token corresponds to a trace generated by powlib for a client Mine call invocation that spawned this pow computation. The ret-token is the returned token that was generated by the callee just before the RPC returned.
Concurrency semantics. The concurrency semantics are identical to A3, except the following:
- You must use caching in your solution. Furthermore, as
noted earlier, powlib instances cannot issue two instances
of
Mine(n,t)andMine(n,t')concurrently. That is, there will be no concurrency betweenMineinstances that have the same nonce. But,Mine(n,t)can be issued if anotherMine(n,t)is not currently issued and blocking on a result. (This is different from A3, which disallowed caching and required that mining RPC invocation received by the coordinator from the powlib were distinct and unique for the entirety of the system execution).
Distributed tracing semantics
All actions that you record in this assignment will be part of
distributed tracing. This means you need to use the new trace-based
API for recording
actions: Trace.RecordAction(action). Note that the A3
solution that we will release to you will need to be updated to use
this style of distributed tracing (this is part of the assignment).
The set of non-cache related actions you must record are the same as
in A3. A key new aspect, however, is that these actions must be
recorded as part of the respective trace that they are
referencing. For example, the PowlibMine action must
now be recorded as part of corresponding trace that was created for
the respective client Mine request. You should take
special care to make sure that actions you record at the coordinator
and the workers are associated with the correct
traces. Another thing to keep in mind is that all ordering
constraints within a trace are now evaluated according to the
happens before relation (i.e., using vector clocks), not physical
clock timestamps.
-
Actions to be recorded by the powlib:
-
PowlibMiningBegin{Nonce, NumTrailingZeros}signifies the start of mining. Every distributed trace must contain this action exactly once, before any other action. -
PowlibMine{Nonce, NumTrailingZeros}; powlib should record this action just before sending the mining request to the coordinator. Every distributed trace must contain this action exactly once, before either of the correspondingPowlibSuccessandPowlibMiningComplete. -
PowlibSuccess{Nonce, NumTrailingZeros, Secret}; powlib should record this action just after receiving the mining result from the coordinator. This should appear exactly once in a distributed trace, beforePowlibMiningComplete. -
PowlibMiningComplete{Nonce, NumTrailingZeros, Secret}signifies the end of mining. This should appear exactly once in a distributed trace. Powlib should record this action after receiving the result from the coordinator and it should record the received secret as part of this action. Powlib should record this action before sending the result tonotify-channel.
-
Actions to be recorded by the coordinator:
-
CoordinatorMine{Nonce, NumTrailingZeros}indicates that the coordinator has just received a mining request from a client. This should appear exactly once in a distributed trace, before any of the related coordinator or worker actions. -
CoordinatorWorkerMine{Nonce, NumTrailingZeros, WorkerByte}; the coordinator should record this action just before sending a mining request to a worker. This should appear once perWorkerBytein a distributed trace. -
CoordinatorWorkerResult{Nonce, NumTrailingZeros, WorkerByte, Secret}; the coordinator should record this action just after receiving a mining result from a worker. This should appear at most once perWorkerBytein a distributed trace. If it is absent, a correspondingCoordinatorWorkerCancelshould be present in the same distributed trace. -
CoordinatorWorkerCancel{Nonce, NumTrailingZeros, WorkerByte}; the coordinator should record this action just before sending aFoundRPC to the worker (which should cancel the worker's corresponding job). This should appear at most once per(WorkerByte, secret)tuple, wheresecretcorresponds to a discovered pow secret that was found and reported earlier (via happens-before) with aWorkerResultaction in the same distributed trace. If aCoordinatorWorkerCancelis absent, a correspondingCoordinatorWorkerResultshould be present in the same distributed trace. -
CoordinatorSuccess{Nonce, NumTrailingZeros, Secret}; the coordinator should record this action just before sending the mining result to the client. This should appear exactly once in a distributed trace. All other coordinator and worker actions in this trace must happen before this action. (Notice that this is a strong ordering condition that prevents any concurrent actions at the workers in the same trace).
-
Actions to be recorded by the workers:
-
WorkerMine{Nonce, NumTrailingZeros, WorkerByte}indicates that a given worker with a uniqueWorkerBytehas started searching for the secret. Every worker must report this exactly once in a in a distributed trace, before any other actions that worker might record in the same trace. This should appear exactly once per worker in a distributed trace, and should precede any other relevant actions. -
WorkerResult{Nonce, NumTrailingZeros, WorkerByte, Secret}indicates that the worker withWorkerBytehas found a secret, and will send this secret to the coordinator. Let t be a distributed trace in which the worker received aWorkerMinewithWorkerByte. Then, t must record at most one instance ofWorkerResultwith thatWorkerByte. If noWorkerResultis present for thatWorkerByte, then at least one instance ofWorkerCancelmust be recorded with thatWorkerByte, corresponding to the same number (at least one) of theFoundRPC being received due to one or more workers finding a result first. IfWorkerResultis present, then 0 or moreWorkerCancelmay occur, again corresponding to the (0 or more)FoundRPCs that may be received in that case. -
WorkerCancel{Nonce, NumTrailingZeros, WorkerByte}indicates that the worker withWorkerBytereceived aFoundRPC. This worker should terminate the related mining job. (Note that the aboveWorkerResultdescription constrains whenWorkerCancelactions may be recorded).
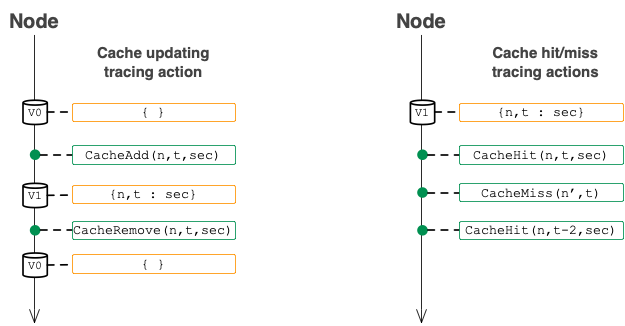
-
Caching actions recorded by the coordinator and workers (see figure above):
-
CacheAdd{Nonce, NumTrailingZeros, Secret}indicates that a cache entry{Nonce,NumTrailingZeros : Secret}was added to the node's cache and that this entry was not already in the cache.- CacheAdd-causing PowlibMine is present: This action
can only appear if there exists a corresponding
recorded
PowlibMine{Nonce, NumTrailingZeros}action, such that thisPowlibMineaction happened before thisCacheAddaction in the same trace (in terms of vector clocks associated with actions). - CacheAdd only after a computed pow: This action can
only appear if there exists a corresponding
recorded
WorkerResult{Nonce, NumTrailingZeros, WorkerByte, Secret}action, such that thisWorkerResultaction happened before thisCacheAddaction. - After CacheAdd, future accesses generate hits: All
cache queries for key
(Nonce, NumTrailingZeros)in the same trace or in traces that might be created after the trace that contains thisCacheAddaction, but before a correspondingCacheRemoveaction has been recorded, should record aCacheHitaction and returnSecretas the value for the key.
- CacheAdd-causing PowlibMine is present: This action
can only appear if there exists a corresponding
recorded
-
CacheRemove{Nonce, NumTrailingZeros, Secret}indicates that a cache entry{Nonce,NumTrailingZeros : Secret}was in the cache and that it has been removed.- Cannot CacheRemove what has not been added: This action
can only appear if there exists a previously recorded and
corresponding
CacheAddaction, either in this distributed trace or in a trace that has been created before this trace. - CacheRemove only after a computed, dominating, pow:
This action can only appear if there exists a
recorded
WorkerResult{Nonce, T, Secret}action withT > NumTrailingZeros, such that thisWorkerResultaction happens before thisCacheRemoveaction. - After CacheRemove, future accesses generate misses: All cache queries for
key
(Nonce, NumTrailingZeros)in the same trace, or in traces that are created after the trace that contains thisCacheRemoveaction, after thisCacheRemoveaction has been recorded, but do not contain a dominatingCacheAdd, should record a correspondingCacheMissaction.
- Cannot CacheRemove what has not been added: This action
can only appear if there exists a previously recorded and
corresponding
-
CacheHit{Nonce, NumTrailingZeros, Secret}indicates that there was a cache hit for the keyNonce,NumTrailingZeros.- CacheHit-causing PowlibMine is present: This action
can only appear if there exists a
recorded
PowlibMine{Nonce, NumTrailingZeros}action, such that thisPowlibMineaction happened before thisCacheHitaction in the same trace. - No spurious hits: This action can only appear if the
cache is queried for a key
(Nonce, NumTrailingZeros)and the cache currently contains the entry{Nonce, NumTrailingZeros' : Secret}, such thatNumTrailingZeros' >= NumTrailingZeros. - Only hit on keys that have been added: This action
can only appear if there exists a trace t, that is either this
trace or a trace that was created before this trace, and t
contains a
CacheAdd{Nonce, NumTrailingZeros', Secret}action, such thatNumTrailingZeros' >= NumTrailingZeros. If thisCacheAddaction is in the same trace, then it must have happened before the recordedCacheHit.
- CacheHit-causing PowlibMine is present: This action
can only appear if there exists a
recorded
-
CacheMiss{Nonce, NumTrailingZeros}indicates that there was a cache miss for the keyNonce,NumTrailingZeros.- CacheMiss-causing PowlibMine is present: This action
can only appear if there exists a corresponding
recorded
PowlibMine{Nonce, NumTrailingZeros}action, such that thisPowlibMineaction happened before thisCacheMissaction in the same trace. - No spurious misses: This action should only be
recorded if the cache is queried for key
(Nonce, NumTrailingZeros)and the cache does not currently contain this key or any key(Nonce, NumTrailingZeros'), such thatNumTrailingZeros' >= NumTrailingZeros. - Only miss on keys that have not yet been added:
This action should only be recorded if no
CacheAdd{Nonce, NumTrailingZeros', Secret}action has been previously recorded withNumTrailingZeros' >= NumTrailingZeros, either in the same trace, or in a trace that was created before the trace that contains thisCacheMissaction.
- CacheMiss-causing PowlibMine is present: This action
can only appear if there exists a corresponding
recorded
An interesting feature of caching actions is that their temporal ordering requirements (below) sometimes implicate a single trace (within trace constraints) and sometime implicate multiple traces (between trace constraints).
Found
message quenching optimization mentioned above). Your solution,
however, may introduce more caching actions than the ones that appear
below (as long as they conform to the above constraints).
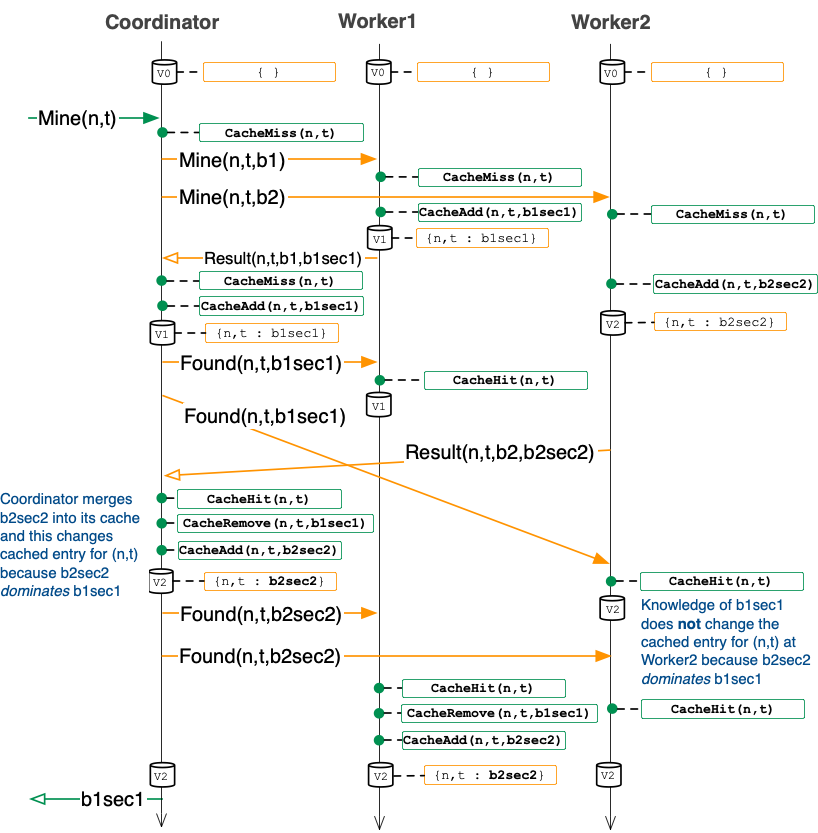
Assumptions you can and cannot make
Identical to A3.
Implementation notes
Take a look at A3 implementation notes, as many of those carry over.
In this assignment, you need to use the latest version of the tracing
library. To do this, run the following command from your project base
directory:
go get -u -v
github.com/DistributedClocks/tracing
You should then see the following line in your go.mod file:
github.com/DistributedClocks/tracing v0.0.0-20210307092023-9172fa1dd33e
The A3 solution that you can build on in A4 will be released as part of the starter code in your A4 repositories.
The starter code contains the file cache.go, which
defines the cache-related action types that you should record in your
implementation.
Note that the easiest way to achieve correct caching semantics is to use a lock for the cache data structure. Once this lock is acquired, the cache action can be recorded. This approach provides atomicity between performing a cache operation (add/remove/access) and the logging of the corresponding cache action.
Testing
We will release some smoke tests for you to test your tracing log files. As before, we recommend that you test your system across a variety of deployments. One of the best ways to test your system is to use the tracing output and assert that events are occurring in the expected order.
Implementation requirements
Identical to A3.
Handin instructions
As with previous assignments, you will use your personal repository
for this assignment under the
CPSC416-2020W-T2
org. Your repository will look
like cpsc416_a4_USERNAME.
We will make the starter code available as part of your handin repository. Keep the provided file layout at the top-level in your solution. You may include additional files, but we do not expect this will be necessary. Do not reference any additional libraries in your solution.
Rough grading scheme
Your code must not change the powlib API, tracing structs and applications' configurations and command-line arguments. Your code must work on ugrad servers. If any of these are violated, your mark for this assignment is 0. This is true regardless of how many characters had to be changed to make your solution compile, and regardless of how well your solution works with a different API or on a different machine.
The high-level A3 mark breakdown looks like this:
- 10% : All A3 (distributed tracing) action semantics are satisfied
- 10% : Node caches provide eventual consistency semantics:
after powlib
Minerequests stop, the caches across coordinator and all workers must eventually contain identical entries. - 20% : CacheAdd semantics are satisfied
- 6% : CacheAdd-causing PowlibMine is present
- 7% : CacheAdd only after a computed pow
- 7% : After CacheAdd, future accesses generate hits
- 20% : CacheRemove semantics are satisfied
- 6% : Cannot CacheRemove what has not been added
- 7% : CacheRemove only after a computed, dominating, pow
- 7% : After CacheRemove, future accesses generate misses
- 20% : CacheHit semantics are satisfied
- 6% : CacheHit-causing PowlibMine is present
- 7% : No spurious hits
- 7% : Only hit on keys that have been added
- 20% : CacheMiss semantics are satisfied
- 6% : CacheMiss-causing PowlibMine is present
- 7% : No spurious misses
- 7% : Only miss on keys that have not yet been added
Make sure to follow the course collaboration policy and refer to the submission instructions that detail how to submit your solution.