416 Distributed Systems: Assignment 3 [Distributed proof-of-work]
Due: Feb 7th at 11:59pm PST
Winter 2020
In this assignment you will start using networking in Go. For this we will re-use the problem in assignment 2 (proof-of-work), but this time introduce multiple processes that are optionally running on different machines. You will use Go's built-in remote procedure calls (RPC) package to coordinate these nodes to solve a proof-of-work task in a distributed manner. In the following assignment you will update your system to survive certain types of failures.
Overview
This assignment's objective is to introduce you to the RPC communication library in Go and to reasoning through simple distributed coordination. You will learn:
- How to perform simple distributed coordination
- How to use the Go RPC package
Why use processes instead of go routines? A process has its own address space and can be spawned on a different machine. This provides your system with horizontal scale out. Go routines, by contrast, run on the same machine as the host process and are limited to the resources of that machine. If the machine has many cores then the go routines can efficiency share the machine, but if the number of go routines exceeds core capacity and the machine has other competing processes, then it might be time to consider a distributed multi-process solution. This will be your objective in this assignment.
You will retain the features of the previous assignment: definition of the proof of work problem remains the same, as well as the method by which you will split the space of byte sequences between processes. That is, a process in this assignment will act (as far as proof of work exploration is concern) like a go routine in the previous assignment.
Distributing proof-of-work
Your system will be composed of three types of processes or nodes. Some number of client nodes will generate proof-of-work problems for your distributed system to compute. We will give you initial code for the client node. Note that a client node is composed of (1) powlib, which is the library that the client uses to submit pow tasks and receive solutions, and (2) some additional code that uses the powlib. The system will also have a single coordinator node to orchestrate the worker nodes. The coordinator will receive the proof-of-work problem via RPC from a client and coordinate the distributed computation to come up with a solution that the coordinator will send back to the client. Your system will also have several worker nodes, whose job is to communicate with the coordinator via RPC, work on a partition of the proof-of-work problem, and deliver a solution to the coordinator.
After starting up, your system should be able to compute several proof-of-work solutions before stopping. We will outline the RPC protocols that your system should follow. There will be an RPC protocol between clients and the coordinator, and also an RPC protocol between the coordinator and a worker instance. Note that clients do not communicate with workers. Here is a graphical overview of the system:
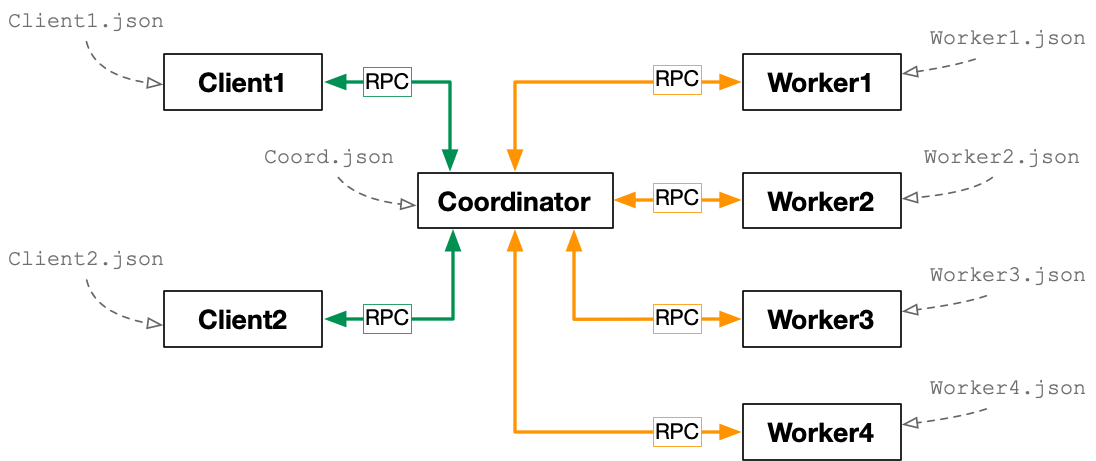
In this assignment you will make several simplifying assumptions. The number of worker nodes for a single instance of the system is constant (new workers do not join and existing workers do not leave). The number of clients, however, may vary over time. You can also assume that none of the nodes fail. For example, the coordinator does not need to worry about client failures or worker failures. And, workers do not need to worry about coordinator failures.
You must use the scheme from the A2 for partitioning work among the worker nodes. You can use your solution for A2, or you can use the solution that we released. Assuming that the number of worker processes is a power of two, we can work through an example. Consider the case where we have 2 bits for the number of workers, giving us 2^2 = 4 workers. Each worker can then be given a different part of the key space:
- Worker 0 can be given all suffixes starting with binary 00
- Worker 1 can be given all suffixes starting with binary 01
- Worker 2 can be given all suffixes starting with binary 10
- Worker 3 can be given all suffixes starting with binary 11
For even more simplicity, you can assume that we will not use worker counts larger than 2^8 = 256. That is, your system will have a maximum of 256 worker nodes. For more details about the pow algorithm, consult the A2 spec.
powlib API
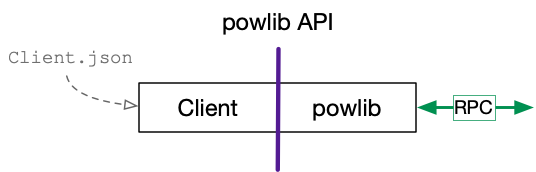
Your powlib has the POW struct. This struct must provide the
following API, for which stub methods are given in powlib/powlib.go.
Also Note that all the calls below assume a single-threaded library client (each call invoked by the client must run to completion and return before another invocation by a client can be made). In the descriptions below if err (of built-in error type) is nil then the call succeeded, otherwise err must include a descriptive message of the error. There are no constraints on what the error message is, the exact text does not matter.
- notify-channel, err ← Initialize(CoordIP:CoordPort, ChCapacity)
- Initializes the instance of POW to use for connecting to the coordinator, and the coordinators IP:port. The returned notify-channel channel must have capacity ChCapacity and must be used by powlib to deliver all solution notifications. If there is an issue with connecting, this should return an appropriate err value, otherwise err should be set to nil.
- err ← Mine(tracer *tracing.Tracer, nonce []uint8, numTrailingZeroes uint)
- This is a non-blocking request from the client to the system solve a proof of work puzzle. The arguments have identical meaning as in A2. In case there is an underlying issue (for example, the coordinator cannot be reached), this should return an appropriate err value, otherwise err should be set to nil. Note that this call is non-blocking, and the solution to the proof of work puzzle must be delivered asynchronously to the client via the notify-channel channel returned in the Initialize call.
- err ← Close()
- Stops the POW instance from communicating with the coordinator and from delivering any solutions via the notify-channel. If there is an issue with stopping, this should return an appropriate err value, otherwise err should be set to nil.
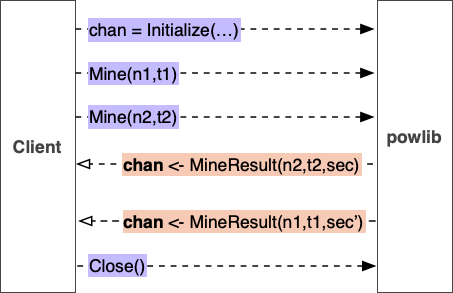
You can assume that the client will first invoke Initialize before making zero or more calls to Mine, and will eventually call Close before the client process exits. It is possible that after invoking Close, instead of exiting, the client again invokes Initialize to begin another session. The diagram below visualizes the powlib api usage.
RPC specifications sketch
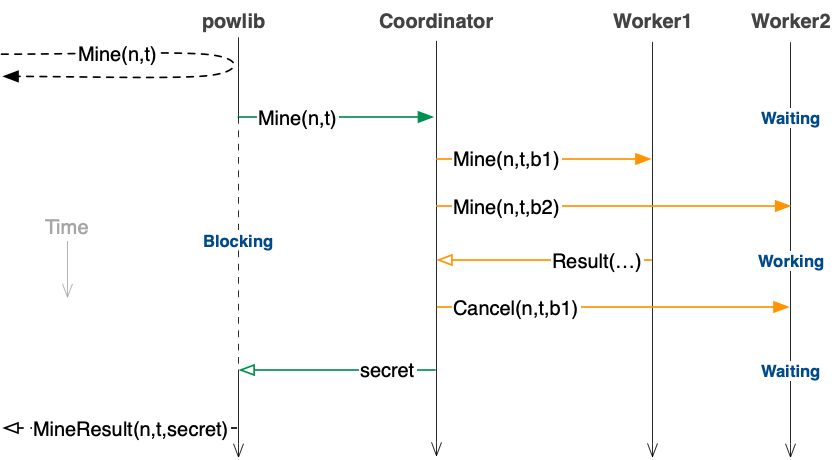
RPCs powlib → Coordinator:
- secret []uint8 ← Mine(nonce []uint8, numTrailingZeroes uint)
- This is a blocking RPC from powlib instructing the coordinator to solve a specific pow instance.
- nil ← Mine(nonce []uint8, numTrailingZeroes, workerByte uint8)
- This is a non-blocking async RPC from the coordinator instructing the worker to solve a specific pow instance.
- nil ← Cancel(nonce []uint8, numTrailingZeroes, workerByte uint8)
- This is a non-blocking async RPC from the coordinator instructing the worker to stop solving a specific pow instance.
- nil ← Result(nonce []uint8, numTrailingZeroes, workerByte uint8, secret []uint8)
- This is an RPC from the worker that sends the solution to some previous pow instance assignment back to the coordinator.
Notice that in this assignment a pow computational instance at
a worker is identified by the triplet [nonce, numTrailingZeroes,
workerByte]. Also, notice that the coordinator must compute
the workerByte that the worker should use. This
computation must be performed dynamically -- if there are four workers
in the system, then the coordinator must split the work into four
parts, if there are eight workers, then the work must be split eight
ways. We will only run your system with k workers where k is some
power of 2.
Concurrency semantics: The RPC figure above illustrates the flow of recommended RPC invocations. There are several important omissions in this figure that are related to concurrency that you should keep in mind:
- Your coordinator must be able to handle requests from multiple concurrent clients. (The figure illustrates a setup with a single client.) However, note that the coordinator can (and probably should for simplicity) serialize these concurrent requests.
- A single instance of powlib must be able to issue multiple mining requests to the coordinator to service multiple powlib Mine API invocations by the client. (The figure shows just a single request from the powlib.)
- Your worker implementation must be able to work on more than one proof of work assignment at the same time (e.g., issued from a single powlib, or issued by different powlib instances). The figure shows two workers, each of which are working on a single proof of work assignment.
- The coordinator may receive multiple secrets from different workers simultaneously. It should report the first secret that it received back to powlib. As soon as the coordinator receives the first secret from a worker, it must notify all the other workers to stop their work on the related pow computational instance.
- You should not use any caching in your solution. Furthermore, you must assume that every mining RPC invocation that the coordinator receives from the powlib is distinct and unique.
- The coordinator should not perform any work assignment to workers until all the workers (specified in the input json file) are online and connected to the coordinator. Until that time the coordinator should block powlib mining requests and wait for all the workers to join the system.
- The coordinator must not report a secret back to powlib until all workers have stopped working on the mining request (i.e., until all the Cancel RPCs have completed).
Distributed tracing semantics
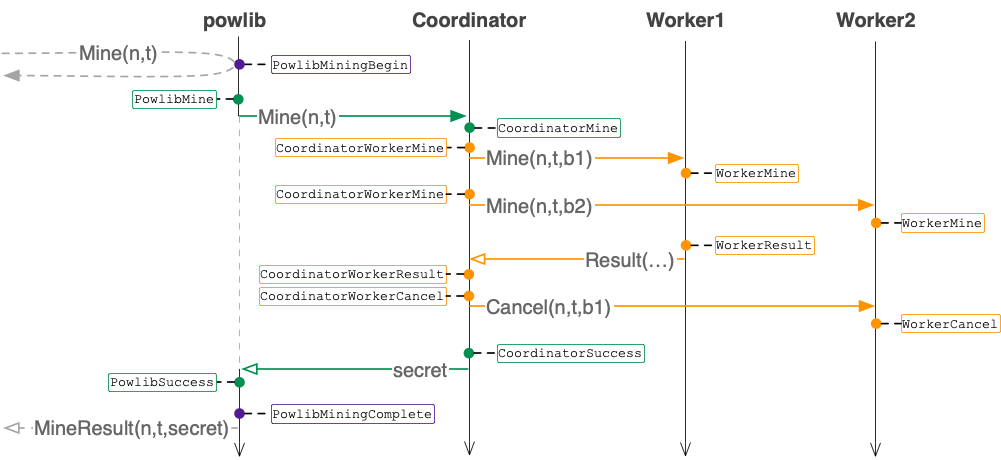
In this assignment you will continue to use the tracing library,
reporting actions using calls
to tracer.RecordAction. Because the processes are
distributed, you will need to record specific actions at specific
processes. There will be specific set of actions that must be
recorded by the powlib, by the coordinator, and by the workers.
Each action you need to report, alongside its meaning, is listed here:
-
Actions to be recorded by the powlib:
-
PowlibMiningBegin{Nonce, NumTrailingZeros}signifies the start of mining. For each pair of{Nonce, NumTrailingZeros}, this should appear exactly once, before any other actions. -
PowlibMine{Nonce, NumTrailingZeros}; powlib should record this action just before sending the mining request to the coordinator. This should appear exactly once per{Nonce, NumTrailingZeros}pair, before either of the correspondingPowlibSuccessandPowlibMiningComplete. -
PowlibSuccess{Nonce, NumTrailingZeros, Secret}; powlib should record this action just after receiving the mining result from the coordinator. This should appear exactly once per{Nonce, NumTrailingZeros}pair, beforePowlibMiningComplete. -
PowlibMiningComplete{Nonce, NumTrailingZeros, Secret}signifies the end of mining. For each pair of{Nonce, NumTrailingZeros}, this should appear exactly once after all other actions and should contain one of the discovered secrets. Powlib should record this action just before sending the result tonotify-channel.
-
Actions to be recorded by the coordinator:
-
CoordinatorMine{Nonce, NumTrailingZeros}indicates that the coordinator has just received a mining request from a client. This should appear exactly once per{Nonce, NumTrailingZeros}pair, before any of the related actions. -
CoordinatorWorkerMine{Nonce, NumTrailingZeros, WorkerByte}; the coordinator should record this action just before sending a mining request to a worker. This should appear exactly once per{Nonce, NumTrailingZeros, WorkerByte}triple. -
CoordinatorWorkerResult{Nonce, NumTrailingZeros, WorkerByte, Secret}; the coordinator should record this action just after receiving a mining result from a worker. This should appear at most once per{Nonce, NumTrailingZeros, WorkerByte}triple; if it is absent, a correspondingCoordinatorWorkerCancelshould be present. -
CoordinatorWorkerCancel{Nonce, NumTrailingZeros, WorkerByte}; the coordinator should record this action just before cancelling a worker's mining job. This should appear at most once per{Nonce, NumTrailingZeros, WorkerByte}triple; if it is absent, a correspondingCoordinatorWorkerResultshould be present. -
CoordinatorSuccess{Nonce, NumTrailingZeros, Secret}; the coordinator should record this action just before sending the mining result to the client. This should appear exactly once per{Nonce, NumTrailingZeros}pair, after all other relevant coordinator actions, and after all relevant worker actions.
-
Actions to be recorded by the workers:
-
WorkerMine{Nonce, NumTrailingZeros, WorkerByte}indicates that a given worker withWorkerBytehas started searching for the secret. Every worker must report this exactly once for each pair of{Nonce, NumTrailingZeros}as part of its execution, before any other actions that worker might record. This should appear exactly once per{Nonce, NumTrailingZeros, WorkerByte}triple, and should precede any other relevant actions. -
WorkerResult{Nonce, NumTrailingZeros, WorkerByte, Secret}indicates that the worker withWorkerBytehas found a secret. This should appear at most once per{Nonce, NumTrailingZeros, WorkerByte}triple; if it is absent, a correspondingWorkerCancelshould be present. -
WorkerCancel{Nonce, NumTrailingZeros, WorkerByte}indicates that the worker withWorkerBytereceived a cancellation. This worker should terminate the related mining job. This should appear at most once per{Nonce, NumTrailingZeros, WorkerByte}triple; if it is absent, a correspondingWorkerResultshould be present.
Note that WorkerByte refers to the bit prefix a worker has been assigned to explore.
If we are considering two-bit prefixes, and a worker's WorkerByte is 3, then that worker
should be exploring only secrets that begin with binary 11.
Note that there are more (allowed) race conditions in this
assignment than in A2. It is possible for more than one worker to
report a WorkerResult action. In this case,
the CoordinatorSuccess action should report the
first secret that was found (corresponding to the first
recorded CoordinatorWorkerResult action).
Also note that CoordinatorWorkerCancel actions should be logged
strictly after a secret has been discovered (after at least one
CoordinatorWorkerResult action).
numTrailingZeroes=7:
[client0] PowlibMiningBegin Nonce=[1 2 3 4], NumTrailingZeros=7 [client0] PowlibMine Nonce=[1 2 3 4], NumTrailingZeros=7 [coordinator] CoordinatorMine Nonce=[1 2 3 4], NumTrailingZeros=7 [coordinator] CoordinatorWorkerMine Nonce=[1 2 3 4], NumTrailingZeros=7, WorkerByte=0 [worker0] WorkerMine Nonce=[1 2 3 4], NumTrailingZeros=7, WorkerByte=0 [coordinator] CoordinatorWorkerMine Nonce=[1 2 3 4], NumTrailingZeros=7, WorkerByte=1 [worker1] WorkerMine Nonce=[1 2 3 4], NumTrailingZeros=7, WorkerByte=1 [coordinator] CoordinatorWorkerMine Nonce=[1 2 3 4], NumTrailingZeros=7, WorkerByte=2 [worker2] WorkerMine Nonce=[1 2 3 4], NumTrailingZeros=7, WorkerByte=2 [coordinator] CoordinatorWorkerMine Nonce=[1 2 3 4], NumTrailingZeros=7, WorkerByte=3 [worker3] WorkerMine Nonce=[1 2 3 4], NumTrailingZeros=7, WorkerByte=3 [worker3] WorkerResult Nonce=[1 2 3 4], NumTrailingZeros=7, WorkerByte=3, Secret=[194 170 210 13] [coordinator] CoordinatorWorkerResult Nonce=[1 2 3 4], NumTrailingZeros=7, WorkerByte=3, Secret=[194 170 210 13] [coordinator] CoordinatorWorkerCancel Nonce=[1 2 3 4], NumTrailingZeros=7, WorkerByte=0 [worker0] WorkerCancel Nonce=[1 2 3 4], NumTrailingZeros=7, WorkerByte=0 [coordinator] CoordinatorWorkerCancel Nonce=[1 2 3 4], NumTrailingZeros=7, WorkerByte=1 [worker1] WorkerCancel Nonce=[1 2 3 4], NumTrailingZeros=7, WorkerByte=1 [coordinator] CoordinatorWorkerCancel Nonce=[1 2 3 4], NumTrailingZeros=7, WorkerByte=2 [worker2] WorkerCancel Nonce=[1 2 3 4], NumTrailingZeros=7, WorkerByte=2 [coordinator] CoordinatorSuccess Nonce=[1 2 3 4], NumTrailingZeros=7, Secret=[194 170 210 13] [client0] PowlibSuccess Nonce=[1 2 3 4], NumTrailingZeros=7, Secret=[194 170 210 13] [client0] PowlibMiningComplete Nonce=[1 2 3 4], NumTrailingZeros=7, Secret=[194 170 210 13]
Note that date/time info, alongside some benign logging noise, have been omitted relative to what you might see when actually running your solution. These are the important parts you should pay attention to.
Assumptions you can make
- No malicious or otherwise invalid inputs will be given to powlib APIs. Values will be given within specified ranges, according to stated invariants.
- We will always start your system in the following order: coordinator, followed by workers, followed by clients. Clients may leave the system, but only after invoking the Close API call on powlib. Workers and the coordinator must never leave the system: i.e., they run as services and never terminate.
- We will only run your system with k workers where k is some power of 2.
- There are no network or process failures.
Assumptions you cannot make
- Anything beyond the basic semantics of goroutines and channels; sufficient testing will likely expose any such assumptions as violating some of the tracing conditions.
- Do not make any network timing assumptions: the network may take arbitrarily long to deliver messages. However, you can assume that all RPC invocations will eventually succeed (since network and process failures are out of scope).
Implementation notes
The provided starter code contains five applications. Your task is to implement the coordinator app, the worker app, and the powlib that will compile with a client application. The cmd/ directory contains each application in a separate directory. The five applications are the following:
-
client/: The client application
as mentioned above. There is a main.go
file in this directory, which reads the client configuration from
config/client_config.json.
It also accepts the id parameter as a command-line argument,
which supersedes the value provided in the configuration
file. For example, you can call:
./client --id client0. - coordinator/: The coordinator application as mentioned above. There is a main.go file in this directory, which reads the coordinator configuration from config/coordinator_config.json.
-
worker/: The worker
application as mentioned above. There is a
main.go file
in this directory, which reads the worker configuration from
config/worker_config.json.
It also accepts the id and listen parameters
as a command-line argument. These supersede the values in the
configuration file. For example, you can call:
./worker --id worker0 --listen :8011. - tracing-server/: The application for running the tracing server. It reads its configuration from config/tracing_server_config.json.
- config-gen/: A simple utility for generating random port numbers for this assignment's config files. You can use this to test your code on the shared CS servers to (try and) avoid port collisions.
While you should be making changes to cmd/coordinator/main.go and cmd/worker/main.go, no changes should be necessary to the client application in cmd/client/main.go; all client implementation-related changes should occur in powlib/powlib.go, and your code should function correctly with the provided client application unchanged.
The powlib/ directory contains the
powlib package. It defines a POW struct with stub methods you should implement.
This exact API is required, and will be relied upon for grading.
You may, however, add any fields you need to the POW struct, as well
as any private helper methods.
The config/ directory contains the configuration files for the client, worker, coordinator, and tracing server.
The worker.go and coordinator.go contain the configuration and tracing action structs, while client.go implements a client based on the powlib API. cmd/client/main.go uses the API provided in this file to build the client application. You can use the same pattern for implementing the coordinator and the worker.
We provide you with a Makefile to easily build and compile all the above applications.
The go.mod file contains dependency
tracking metadata, including a dependency on
https://github.com/DistributedClocks/tracing,
the tracing library.
The go.sum file contains
auto-generated metadata (checksums for module dependencies).
You should not need to touch or understand this file.
Testing
We recommend that you test your system across a variety of deployments. One of the best ways to test your system is to use the tracing output and assert that events are occurring in the expected order.
Implementation requirements
- The client code must be runnable on CS ugrad machines and be compatible with Go version 1.15.6.
- Your code must be compatible with the given API, and run successfully against the provided test cases.
- Your solution can only use standard library Go packages.
- Your solution code must be Gofmt'd using gofmt.
Handin instructions
As with previous assignments, use your personal repository for this
assignment under the
CPSC416-2020W-T2
org. Your repository will look like cpsc416_a3_USERNAME
We make the starter code available as part of your handin repository. Keep the provided file layout at the top-level in your solution. You may include additional files, but we do not expect this will be necessary. Do not reference any additional libraries in your solution.
Rough grading scheme
Your code must not change the powlib API, tracing structs and applications' configurations and command-line arguments. Your code must work on ugrad servers. If any of these are violated, your mark for this assignment is 0. This is true regardless of how many characters had to be changed to make your solution compile, and regardless of how well your solution works with a different API or on a different machine.
The high-level A3 mark breakdown looks like this:
- 5% : PowlibMiningBegin and PowlibMiningComplete are reported correctly
- 5% : PowlibMine and CoordinatorMine are reported correctly
- 5% : CoordinatorSuccess and PowlibSuccess actions are reported correctly
- 5% : CoordinatorWorkerMine and WorkerMine actions are reported correctly
- 5% : WorkerResult and CoordinatorWorkerResult actions are reported correctly
- 5% : CoordinatorWorkerCancel and WorkerCancel actions are reported correctly
- 5% : Secret reported by coordinator, powlib, and client is associated with the right worker via the WorkerByte prefix
- 5% : The secret returned to the client is correct
- 5% : Powlib works correctly with multiple Mine invocations by the client
- 10% : The coordinator works correctly with multiple requests from the same powlib instance
- 10% : The coordinator works correctly with with multiple requests from different powlib instances
- 10% : The coordinator works correctly with different number of workers
- 25% : The distributed system runs correctly in a distributed/networked environment
Advice
- You are developing three distinct codebases: the powlib, the coordinator, and worker. You could start by building simple versions of these based on the code from A2 that assume a single client with a single mining request. Alternatively, you could develop each component more completely before moving on to the next component (powlib, then coordinator, then worker). Whatever you do, make sure to plan and think through your design first.
- The powlib, coordinator, and worker codebases will all have substantial concurrency. Spend the time to learn more about go routines and the different ways in which you can coordinate them.
- Only introduce RPC into your codebases once you understand how it works and how to use it. RPC will seem like a breeze compared to the concurrency complexity. Still, learn RPC with a small synchronous RPC example. Then, make that example asynchronous with a go routine per RPC invocation.
- Compile and run your code on and across the available ugrad servers. Remember that there are multiple CS servers at your disposal.
Make sure to follow the course collaboration policy.