416 Distributed Systems: Assignment 4
Due: Feb 12th at 9PM
Winter 2016
In this assignment you will create a simple distributed key-value service to replace the centralized key-value service from assignment 3. Your service will use a collection of nodes to provide fault tolerance and extra storage capacity for storing keys/values. Your service will also include a designated front-end node to mediate access to the distributed key-value service.
High-level overview
The centralized key-value service from assignment 3 has two drawbacks:
the hosting node may run out of storage capacity and the hosting node
is a single point of failure. In this assignment you will distribute
the storage of keys/values (across a set of kv nodes), but you will
retain a single node (the front-end) for accessing the key-value
service. Your final system will have the following design:
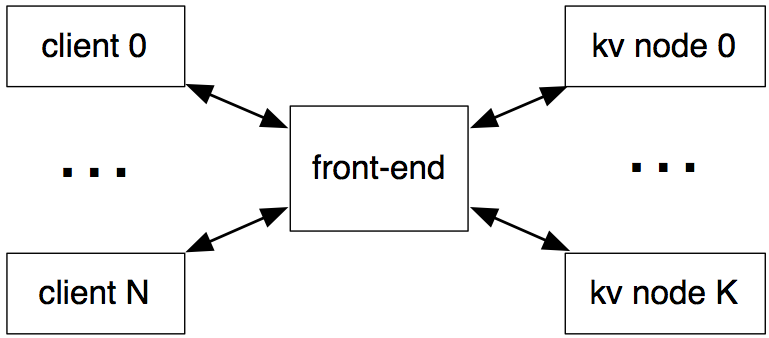
Note that the front-end node mediates all communication between the clients and the kv nodes, and the kv nodes do not communicate among each other. As in the previous assignment your system must work with an arbitrary number of clients (N), and must also work with an arbitrary number of kv nodes (K). Further, your system must provide an identical interface and serializable data consistency semantics to the client nodes (as in the previous assignment), handle joining and failing kv nodes, and (for extra credit) be able to survive front-end node restarts.
Nodes
Front-end node. The front-end is responsible for servicing client queries, however this node must not store any key values itself. It can store meta-data for keys. The storage responsibility for key values resides with the kv nodes.
KV nodes. A kv node is a storage node that associates keys with values. Note that not every kv node will store/replicate every key-value pair. A kv nodes communicates solely with the front-end node. The kv node does not maintain any durable state (e.g., files on disk). That is, when a kv node is restarted it loses all of its state.
Client nodes. As in the previous assignment, client nodes communicates with the front-end node through a put/get/testset RPC interface and do not know about the kv nodes that provide storage for the key values.
Solution requirements
Your distributed key-value service solution must have the following features:
- Key replication. Each key-value pair must be replicated on exactly r kv nodes (which we also call replicas), where r is parameter given to the front-end on the command line. If the total number of kv nodes in the system is x, where x < r, then each key is replicated just x times.
- Serializable key-value consistency semantics. The overall system (combination of front-end and kv nodes) must provide serializable data consistency semantics to the client nodes (as in the previous assignment).
- Key availability semantics. Failure of x of the r replicas for a key k should result in the following behavior:
- x < r : key k should remain available to clients
- x = r : key k should become unavailable to clients, and remain unavailable indefinitely
- Key re-replication on failures. Whenever the number of replicas for a key drops below r (because of replica failures), the service should re-replicate the key-value information to additional (but different) kv-nodes. If there are no other kv nodes, re-replication should proceed when new kv nodes join the system.
- Persistent key-replica assignment. Once a key is replicated by a kv node, it remains replicated on that node until the node fails.
Implementation requirements
- All kv nodes run the same code.
- All kv nodes communicate only indirectly, through the key-value service. This means that a kv node does not know which other kv nodes are participating in the system, how many there are in total, where they are located, etc.
- The front-end node should recognize and implement several special commands in the form of an argument to the get RPC. A partial implementation of these commands is in the starter code for the front-end and client below. Each command must (1) execute atomically with respect to any replication process, and (2) complete before the RPC returns to the client. The special commands are:
- get("CMD get-replicas-of k") where k represents a key name. The return value of this command should be a space-separated string of IDs for the replicas that replicate key k.
- get("CMD kill-replica id") where id represents a replica id. This command should terminate replica with id, causing the replica to execute os.Exit(-1). The command should return "false" if the replica with this id does not exist, and "true" on success.
- get("CMD kill-replicas-of k x") where k represents a key name and x is a positive integer, x <= r. This command should terminate some x of the replicas that replicate id, causing each replica to execute os.Exit(-1). If there are fewer than x replicas for key k, the command should terminate all of them. The command should return a string "n" where n is the total number of terminated replicas.
- Your implementation must be robust to kv node halting failures.
- Your implementation must support dynamically joining kv nodes.
- You cannot change the client API of the key-value service from assignment 3. This API and its semantics must remain identical. That is, your code from the previous assignment must continue to interoperate and work with your new distributed key-value service.
- Your solution can only use standard library Go packages.
Download the starter kv-front-end.go and an example cmd-client.go. These include a bit of parsing code to handle the CMD commands described above. You will be notified of any changes to this posted code via Piazza.
Assumptions you can make
- No other failures not mentioned above and typical network assumptions (e.g., varying delay, some packet loss).
- Each kv node has a unique identifier (specified on the command line).
- A restarted kv node will have identical command line arguments.
- You have complete control over the design of the communication protocol between the front-end and the kv nodes. You get to decide on the transport layer (e.g., TCP/UDP), comm. abstractions (e.g., RPC) and other features of this protocol.
Assumptions you cannot make
- Nodes in the system have synchronized clocks (e.g., running on the same physical host).
Extra credit: handling front-end restarts
Note that the front-end is a single point of failure in the above system. For extra credit you can extend your solution to handle front-end failure and restarts. Here are the requirements and assumptions for this extension:
- Observable to clients. The system should become unavailable to clients during front-end failures. That is, in contrast to the previous assignment, clients cannot assume that the front-end node does not fail and can deal with an indefinite failure of the front-end (by retrying to connect).
- Complete recovery on restart. When a front-end is restarted with the same IP:port, the system should continue without any loss of state. Front-end failures may last an indefinite length of time. During this time at least one kv node will remain alive.
- No kv node churn during front-end failures.. When the front-end has failed, the kv nodes at the time of failure persist and do not fail until the front-end node has been restarted. New kv nodes do not join the system when the front-end has failed (as they can only do so through the front-end).
- Failures may last an indefinite length of time. No time bound on how long a front-end may be off-line.
- No durable state at the front-end. The front-end node does not maintain any durable state (e.g., files) that it can use to store state during failure.
- Restarted front-end will have identical command line arguments. You can also assume that the front-end will restart on the same physical machine.
Note that the most challenging aspect of this extension is preserving key unavailability semantics. Keys that become unavailable to clients remain unavailable as long as there are kv nodes in the system (i.e., the semantics are preserved even though the front-end node may fail).
Solution spec
Write two go programs kv-front-end.go and kv-node.go that respectively implements the front-end node and kv node in the system, as described above. These should have the following usage:
go run kv-front-end.go [client ip:port] [kv-node ip:port] [r]- [client ip:port] : address that clients use to connect to the front-end node
- [kv-node ip:port] : address that kv nodes use to connect to the front-end node
- [r] : replication factor for keys (see above)
go run kv-node.go [local ip] [front-end ip:port] [id]
- [local ip] : local IP to use when connecting to front-end
- [front-end ip:port] : address of the front-end node
- [id] : a unique string identifier for this kv node (no spaces)
What to hand in:
- A writeup (at most one page long) that describes your design and how it satisfies the above requirements. The writeup should be in .pdf format and should appear at top-level as design.pdf file in your repository.
- If you elect to do the extra credit extension you should submit a second page as part of your design.pdf writeup. The second page should describes your restartable front-end design and how this design satisfies the requirements set out in the extra credit section above. If we do not see a second page in your design.pdf, then we will assume that you did not go for the extra credit.
- Your implementation of the front-end and kv nodes in the system as kv-front-end.go and kv-node.go.
Advice
- Be methodical, spec out the core features you need to build and implement them separately. First, figure out how to get kv nodes to join the system and have front-end node track the kv nodes. Then, make key replication work on a static set of kv nodes (i.e., assume they join initially and then remain in the system for all time). At this time it might be a good idea to implement the special testing commands, which will help you test your system for failures (we will be using this command interface in our marking). Finally, work on kv nodes that join and fail while the system is running. Pay special attention to how/where you store key unavailability information.
- Write down a separate specification for the protocol between the front-end and the kv nodes. That is, do not let the code be the sole documentation for the protocol: write it down so that you can use it for your writeup and to help you think about corner cases in this protocol (e.g., what happens if at this point the kv node fails?).
- Develop a suite of scripts to test your implementation in both the failure-free case and in the case where a variety of failures occur. These can use the special commands from the client side and can easily test your system for e.g., robustness to failing kv nodes.
- The writeup is a key deliverable. Dedicate time to do a good job on cogently describing your design.
Rough grading scheme
Approximate percentages (summing to 125%) for different aspects of the solution:
- 40%: Correct serializable key-value consistency semantics at all times, including during multiple concurrent operations.
- 30%: Re-replication on failure of kv nodes; key availability despite r-1 kv node failures.
- 20%: Correct unavailability semantics.
- 10%: The writeup cogently describes the design and how it meets the requirements set out above.
- 25%: Extra credit (on top of the 100% above)
- 10%: Key values and replica assignment correctly reinstated after front-end restarts.
- 10%: Unavailability semantics are preserved after front-end restarts.
- 5%: The second page of the writeup cogently describes how your solution design supports a restartable front-end.
Make sure to follow the course collaboration policy and refer to the assignments instructions that detail how to submit your solution.