Some Open Research Problems
Some of these are from papers that should be followed up on. Some arose from writing our AI textbook. If you are seriously interested in working on these, let me know, as I might have some ideas. These are in no particular order.
Cyclic causal (and other probabilistic) models
Directed probabilistic models are the natural canonical representation for most domains. There is a problem with cyclic problems. Our IJCAI-13 paper on cyclic causal models proves that Pearl's structural equation models (SEMs) cannot work with discrete variables and cycles. This also applies to probabilistic programs (including probabilistic logic programs) that are modeled as deterministic systems with independent noise. Cyclic models are pervasive in relational models, such as friends of friends are friends (but cyclic methods are still less problematic than undirected models). The paper also proposes Markov chain equilibrium models (which have a long history) and shows some intuitive and not-so-intuitive properties, and lots of open problem. This is probably my most under-appreciated paper (perhaps because it stopped some research for a while until it was forgotten).
Aggregation in Relational Models
Aggregation occurs in relational models and graph neural networks. It occurs when an entity depends on a population of other entities (e.g, predicting a user's gender or age from the movies they have watched). Our SUM 2014 paper investigates asymptotic properties of various aggregators. Our AAAI-2015 paper investigates how adding aggregators to MLN always has side effects. In our StarAI 2017 UAI Workshop paper, we tested every method we could think of, and none worked well. Most aggregators have peculiar properties, and none work well, still! Think about what happens as the number of related individuals ranges from zero to infinity.
Lightweight Models of Missing Data
Most models of missing data require us to reason about what is missing, but we really need lightweight models where missing data is ignored. This is particularly true for relational data where almost all possible data is missing, and the missing data is not missing at random. Our paper in Artemiss 2020 NeurIPS workshop gives some simple ideas. (This work arose after writing our textbook about the logistic regression/naive Bayes equivalence and concluding the generative / discriminative dichotomy doesn't hold up to scrutiny.) I am surprised that LR+/- is not a common method (perhaps it is, please let me know if you have an older reference).
Existential and Identity Uncertainty
Most models of entities and relation assume that we already know what entities exist, and whether two descriptions refer to the same or different individuals. I still think my AAAI-2007 paper is a good idea, and presents the most coherent model of existence and identity I know of. Existence is not a property of an entity; when existence is false, there is no entity to have properties. Only existing entities have properties. Similarly identity (equality) is not a property of two entities. Existence is a properties of descriptions. There might be multiple entities that fit a description. Identity uncertainty has worse-than-exponential computational complexity (Bell number). Existence uncertainty is much trickier to pin down.
Ontologies and Uncertainty
Ontologies define the vocabulary of an information system. Ontologies come before data; what is in the data depends on the ontology. In most cases, what is not represented in the data cannot be recovered. E.g., treating a sequence of data as a set, loses information, as does ignoring the actual time, or the location or the myriad of other possible data that could have been collected. We need to incorporate the diversity of possible meta-information -- including ontologies -- when making predictions about data. E.g., our 2009 paper in IEEE Intelligent systems shows relationships between triples and random variables. Our StarAI-2013 paper sketches some ideas on integrating ontologies and StarAI models (see also Kou et al, IJCAI-2013), and our AAAI-2019 paper gives some preliminary work on embedding-based models. Definitions are useful, and we shouldn't ignore that they exist. The embedding models -- particularly for knowledge hypergraphs (general relations) -- should also be extended to take ontologies into account.
Counterfactual Reasoning
When implementing the AI algorithms for AIPython, counterfactual reasoning was perhaps the most surprising. Observational and interventional data did not constrain the results as much as the underlying causal assumptions (but it isn't clear how to get these). Balke and Pearl [1994] makes most sense (but has too many parameters). See Section 11.2 in the AIPython pdf document, and try the exercises.
Bounded Probabilistic Inference
There has been lots of work on exact probabilistic inference, inference with probabilistic bounds as occurs with stochastic simulation, and with no guarantees as arises in variational inference. However there is much less work on methods that provide upper-and-lower bounds that shrink as inference proceeds. I did some early work on ``Probabilistic conflicts in a search algorithm for estimating posterior probabilities in Bayesian networks'' which could easily be combined with recursive conditioning. To evaluate this, it could be combined with work on bounded rationality, where we want to refine the probability that has the maximum value of computation for decision-making tasks. It should also be possible to do this with conditional probabilities represented as neural networks.
Some other questions I wish I knew the answer to
These are probably not research problems, but seem to be Google-proof and (like most things I try) LLM-proof. How can one justify log-loss (categorical cross-entropy) to skeptical undergraduates learning AI? We give two justifications; I like the gambling one best, but they are not that convincing. Similarly how can we justify squared loss as sensible? I know we can go via the central limit theorem, but that require much more baggage than I want. One the subject of the central limit theorem: I have seen proofs of the multivariate central limit theorem, but I still can't work out why pairwise interactions exist in the limit, but higher (3-way, 4-way etc) interactions don't. Why do they vanish? This seems to be relevant for relational learning which mainly concerns higher-order interactions.
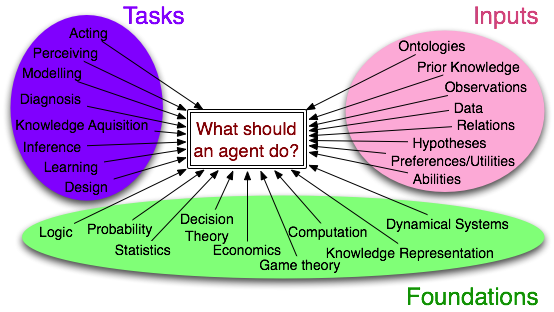
Research Overview
I am interested in the question: what should an intelligent agent do?
There are some detailed stories on:
- Combining logic and probability/decision making or what is called relational probabilistic reasoning or statistical relational AI. Earlier word defined the first probabilistic logic programs, called probabilistic Horn abduction (PHA) and the independent choice logic (ICL) which allow for probabilistic modelling in terms of logic programs with probabilistic choices. ICL includes pure Prolog (including negation-as-failure), Bayesian networks and MDPS as special cases. ICL expands the older probabilistic Horn abduction to choices by multiple agents and a richer logic (including negation as failure), and applications in decision making and planning. Probabilistic Horn abduction was one of the first probabilistic programming languages. There is related work in exploiting the structure implicit in representations for computational gain for probabilistic inference and decision making.
- Probabilistic Reasoning including Variable Elimination, Search-based inference for Bayesian Networks, Exploiting Contextual Independence in Probabilistic Inference, Decision Making Under Uncertainty and lifted inference (see the MIT Press book).
- I used to work on Theorist, a framework for assumption-based logical reasoning. There is information on Early History, Default Reasoning vs Abduction, Specificity and Implementation, Diagnosis and Other Applications.