The VSM learning method was first applied to synthetic data to test its ability to select features of interest and assign them appropriate relative weights. The task was to solve a noisy XOR problem, in which the first two real-valued inputs were randomly assigned values of 0 or 1 and the binary output class was determined by the exclusive-OR function of these inputs. Noise was added to these 2 inputs drawn from a normal distribution with a standard deviation of 0.3 (meaning that there was some overlap between the two classes). The next two inputs were assigned the same initial 0 or 1 values as the first two, but had noise with a standard deviation of 0.5. Finally another 4 inputs were added that had random zero-mean values with a standard deviation of 2.0. The presence of extra random inputs and varying noise levels results in poor performance of nearest-neighbours algorithms. Indeed, the performance of the basic nearest-neighbours algorithm on this data with 100 training and 100 test examples was only 54.3% correct (hardly better than the 50% achieved by random guessing). However, VSM learning achieved 94.6% correct, after 14 iterations of the conjugate gradient convergence, by assigning high weights to the first 2 input features, slightly smaller weights to the next 2, and much smaller weights to the random inputs. Note that because of the XOR determination of the output class, there would be no linear correlation between any individual input and the output, so any linear classifier or feature selection method would fail on this problem.
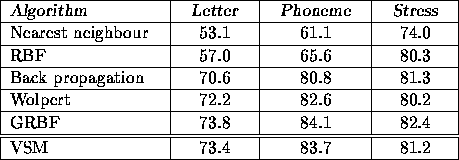
Table 1: This table gives the percent correct generalization on the
NETtalk task for different learning methods. All rows except the last
are from (Wettschereck & Dietterich, 1992).
The next test was performed on the well-known NETtalk task (Sejnowski & Rosenberg, 1987) in which the input is a 7-letter window of an English word and the output is the pronunciation of the central letter. Recently, Wettschereck & Dietterich (1992) have tested many learning methods on this data, using a standardized test method that selects 1000 words of training data at random and a disjoint set of 1000 words of test data. Table 1 presents their results for many well-known learning algorithms, along with the results of running the VSM algorithm on the same data. As the table shows, VSM learning performs significantly better than back propagation or radial basis function (RBF) learning on this data. The one method that is slightly better is a generalized radial basis function (GRBF) method in which the center of each basis function is optimized. However, this required extensive cross-validation testing to select many parameters, such as number of centers and type of parameter adjustments, and the optimization failed to converge from some starting values. In contrast, VSM learning achieves almost the same generalization with only 10 minutes of training time on a SparcStation 2 and with no need for experimentation. The efficiency of the k-d tree access method is such that the distance to only 43 exemplars on average must be checked to determine the 10 nearest neighbours for classification. VSM learning optimizes only 8 parameters (the weights for the 7 inputs and the kernel size), whereas back propagation optimizes 18,629 parameters and GRBF optimizes 40,600 parameters for this problem.
The method by Wolpert listed in Table 1 is similar to VSM, in that it optimizes a distance metric for nearest neighbour interpolation. Wolpert (1990) originally selected the weights by hand, and he applied the method to an edited test set so that his comparison to previous NETtalk data was invalid. Wettschereck & Dietterich (1992) used a mutual information approach to compute the feature weights, and applied it to NETtalk using their standardized test procedure to get the results shown in Table 1. Wolpert's kernel is a distance-weighted kernel that gives infinite weight to an exemplar with zero distance, and these results show that the variable kernel method used in VSM learning has better generalization. Another approach to the NETtalk problem was taken by Stanfill & Waltz (1986), who computed a type of similarity metric from the nearest neighbours of each input. Although they do not perform systematic testing, they report that the results are at about the same level as back-propagation.

Table 2: Percent correct generalization on vowel classification
task for different learning methods. All rows except the last are
from (Robinson, 1989).
VSM learning was also tested on Robinson's (1989) speaker-independent speech recognition data. Each item of training data corresponds to one of 11 vowel sounds, with the input features consisting of 10 real-valued numbers that were extracted from the speech signal using linear predictive analysis and other preprocessing. The training data is produced by 8 speakers saying each of the 11 vowels six times, while the test data is produced by 7 other speakers in the same format. In applying VSM learning, it is important that only neighbours produced by different speakers from the center input are accessed during training, as otherwise the weights will be optimized to recognize each vowel based on data from the same speaker. This is easy to accomplish by adding a field to each exemplar indicating the speaker. The result of VSM learning on this task was better than the other methods tested by Robinson, as shown in Table 2. In fact, the nearest neighbour algorithm performed very well for this task, and the reason for this is shown by the fact that the feature weights changed only a little from their initial value of 1.0 during VSM learning. Presumably, this is because of the careful preprocessing of the speech signal to extract a useful feature set. The further improvement of VSM learning over nearest neighbours is due to the use of the variable kernel.
Another data set on which VSM learning has been tested is Gorman & Sejnowski's (1988) sonar data set. Each exemplar in this data set consists of 60 real-valued inputs extracted from a sonar signal. The task is to classify the object from which the sonar is reflected as either a rock or a metal cylinder. Only their ``aspect-angle dependent'' test case was used, as the precise training and test data cannot be determined for their other series. In this case, VSM learning achieved 95.2% correct classification as compared to the best result of 90.4% obtained by Gorman and Sejnowski using back propagation. Given that only 104 training cases were available, the large number of input dimensions, and the inability to perform randomized trials, it is not clear whether this result is statistically significant.