CPSC 533C
PROJECT PROPOSAL
SAGE
Visualization Tool
TEAM:
Timothy Chan
Email: timchan@cs.ubc.ca
Zsuzsanna Hollander
Email: zsuzsa@cs.ubc.ca
BACKGROUND AND MOTIVATION
In the past decade, gene expression analysis has become highly popular with the advent of high-throughput gene expression technologies, such as SAGE and microarrays. This has led to an exponential growth of gene expression data. Analyzing such data can be quite cumbersome as the dimensionality of this data is high. For instance, typically, each pair of experiments (ie. diseased versus normal tissue) require more than 30,000 gene expression comparisons. Consequently, using visualization tools could be highly beneficial by providing a means of showing the data in an understandable manner.
In a typical gene expression analysis of a disease, one often compares the expression of each gene between a diseased tissue and a normal tissue. The most differentially expressed genes (up or down regulation) are candidates for genetic markers or drug targets for a particular disease. However, there are cases where a researcher may want to look for a gene that is differentially expressed but has a low average “count” since those genes may actually be the genes that may have led to the onset of a particular disease. These slightly altered genetic expressions could mean earlier detection and could be better drug targets as targeting a gene at the beginning of a cascade of events could mean an increased chance to stop the onset of a disease and thus, significantly improve patient survival. Furthermore, many diseases, such as cancer, are far easier to treat if detected early. Unfortunately, in order to isolate these genes, a researcher must arbitrarily choose some statistical filters (ie. P-value, means, standard deviations, permutation scores, etc) and then print out the list. This is not an easy task since in a typical SAGE library there are over 30,000 genes to be analyzed. In addition, when combining different libraries, we can get more than 100,000 rows of data. Currently, there are no “free” publicly available visualization tools to analyze SAGE data. The tools that do exist are very expensive and thus unaffordable to many research institutions. In addition, these tools do not allow researchers to add their own modules and customizations, so one must request the required features and wait for the next release of the tool. Lastly, we have not seen a SAGE visualization tool that can effectively help a researcher isolate genes by adjusting statistical measures in graphical manner.
DATA
Our visualization system will support SAGE (Serial Analysis of Gene Expression) data and possibly microarray data. The SAGE technique was developed in 1995 by Velculescu et al [1]. Unlike microarray techniques, which are based on relative expression levels, SAGE measures mRNA expression by counting representative short sequenced tags. A tag is just a sequence of 10 to 18 letters (depending on the restriction enzyme used) where the alphabet only consists of the 4 letters: A, C, T, and G. ACTG are the bases that make up DNA. SAGE data looks like the following:
|
TAG |
Count |
|
AAAAAAAAAT |
20 |
|
AGTAAAACAA |
3 |
|
ACCCCCCCAA |
46 |
|
GAAAAAAAAT |
2 |
|
CAAAAAAAAT |
1 |
PROPOSED SOLUTION
In this project, we intend to build a modular visualization system for Dr. Raymond Ng’s SAGE projects. We will be consulting mostly with one of his research interns, Raj Chari, to meet his needs.
Our visualization tool will allow a user to generate four plots onto a single window. These four plots include 2 scatter plots, a histogram, and a parallel coordinate plot. We will implement sliders so that certain statistical parameters such as standard deviations, means, ratios, adjusted ratios and permutation scores can be adjusted while the plots are automatically updated. These sliders will help a researcher isolate candidate genes based on these statistical measures.
The input of our system will be a text file consisting of many columns including TAG, Counts, means, standard deviation, permutation score, ratios, and adjusted ratios (maybe more depending on the needs of the researchers). The system will support up to 50 columns and 150,000 rows of data. However, in a typical setting, it will need to support only 15 to 25 columns of data and about 20,000 rows.
PERSONAL EXPERIENCE
Timothy is a first year masters student in computer science and has worked with SAGE data for over a year and half. Through an RAship, he is still involved in SAGE and microarray projects. Zsuzsa is working on microarray data analysis for over a year now under the supervision of Dr Raymond Ng. However, we both are new to visualization and have no prior background in graphics or HCI.
METHODS
To implement our system we will be using Java. We also plan on using a few pre-built modules if they can be integrated effectively into our system. More specifically, we will attempt to integrate existent scatter plot [2], histogram, and parallel coordinate [3] Java modules. If we have problems with the integration, we will implement them ourselves.
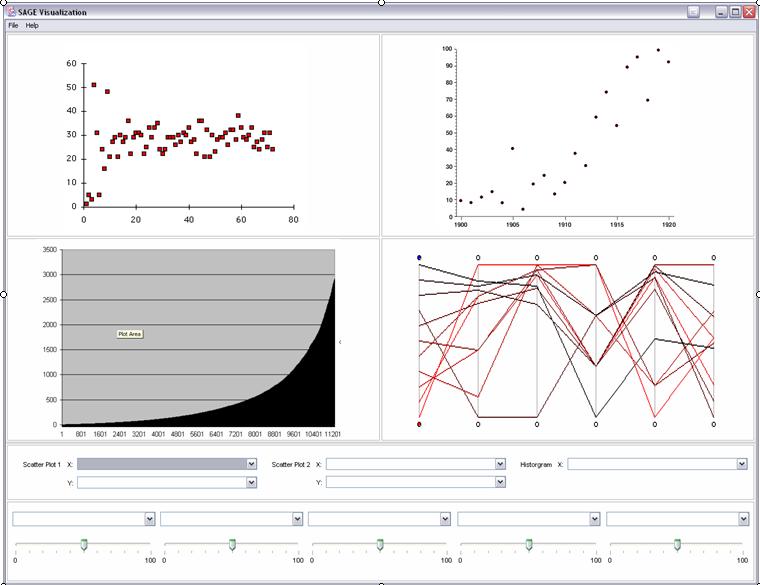
SAMPLE SCENARIO:
- Open SAGE Visualization Tool (see Fig 1).
- Go to “File” menu and select option “Load File”.
- Browse through directories and choose a tab delimited table of data.
- Choose the plot to be generated by selecting the X and Y axes (ie. standard deviation, mean, etc) for the specific type of plot (scatter plot or histogram).
- Repeat step 4 to generate other plots.
- Select a statistical measure from the dropdown lists and adjust its range via the slider box.
- To adjust the other statistical measures repeat step 6, if needed.
- Mouse over points of plots to reveal TAGS.
- Go to “File” menu and choose the “Export” option to get a file of TAGS on a particular plot.
|
Project Start: |
Thu 05/02/04 |
Milestones/Tasks
|
REFERENCES
- Velculescu et al. Serial analysis of gene expression. Science, Vol. 270, Oct 20 1995, pp 484-487.
- Jean-Daniel Fekete. The Toolkit. http://www.lri.fr/~fekete/InfovisToolkit/
- Amit Goel. Parallel Coordinates Visualization Applet. http://www.amitgoel.com/pcoord/