Computer Science 533C
Information Visualization
Project Proposal
Rod McFarland, ![]()
First Draft, 13 Feb 2003
Domain and Task
The Teaching and Learning Enhancement Fund at UBC, through the Office of Learning Technology, has set up a group for implementing a Learning Objects Repository (LOR). I have a research assistantship to work on this project under Dr. Son Vuong. The overall scheme for the LOR project is to have potentially several faculty-specific LO databases which can be accessed individually or in groups by clients. The short-term goal of the LOR group is to improve the existing web interface in terms of its aesthetic appeal and ease of use and to provide administrative functionality either through a separate web interface or a server-based application.
My collection of documents relating to the UBC LOR project can be found here. Other, more official sites are learningobjects.ubc.ca and its newer incarnation (as yet untitled).
Unfortunately at the time of this proposal the implementation plans for the project have not been refined enough to firmly state what the nature of my project for Information Visualization will be. There are two options -- my job description requires that I implement the GUIs for both the server and client. The choice of which interface to enhance with infovis techniques has not been made (but will be soon):
| Client GUI (Browsing and
Searching)
A Learning Object has a very vague definition: according to some, it can be literally anything. For the purposes of the UBC LOR Group, it is anything that can be referenced by a URI. The Repository is not a collection of actual objects (pictures, lecture plans, videos, animations...) but a database of URIs and associated metadata. The metadata standard followed at UBC is that developed by CanCore (www.cancore.org), derived from the IMS project's metadata standard A standalone client application is envisioned that will provide a rich and powerful means of browsing and searching the LOR. Concepts could be applied to other situations such as conventional library catalogues. |
Server GUI (Administrative) Administrative tasks would include maintenance of the LOR database, network status, load metering, modification of and summarizing user account information, server log analysis, and probably many other functions to be discussed in a meeting scheduled for Monday, February 17. |
My expertise in the area of LOs is in some ways minimal, since I only recently heard of the concept. However the idea is not completely alien, since I am a teacher. I have not got a lot of experience in accessing databases and so will be relying on other members of the LOR implementation team to provide an interface which I can use to develop the GUI and infovis components.
Scenario of Use
|
Server GUI (Administrative) At time of writing, requirements for the administrative GUI have not been discussed to any great length. Some features that have been mentioned in meetings so far are:
Since the LO format is defined, if work were to proceed immediately it would be best to work on the global LOR view. User statistics could potentially provide a useful data set for infovis, but the fields have not been specified at this time. The form of networking is also not completely specified, so the type of information available is not known at this time. Watch this space for further developments once the network and administrative requirements are better known. |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Client GUI (Browsing and Searching)
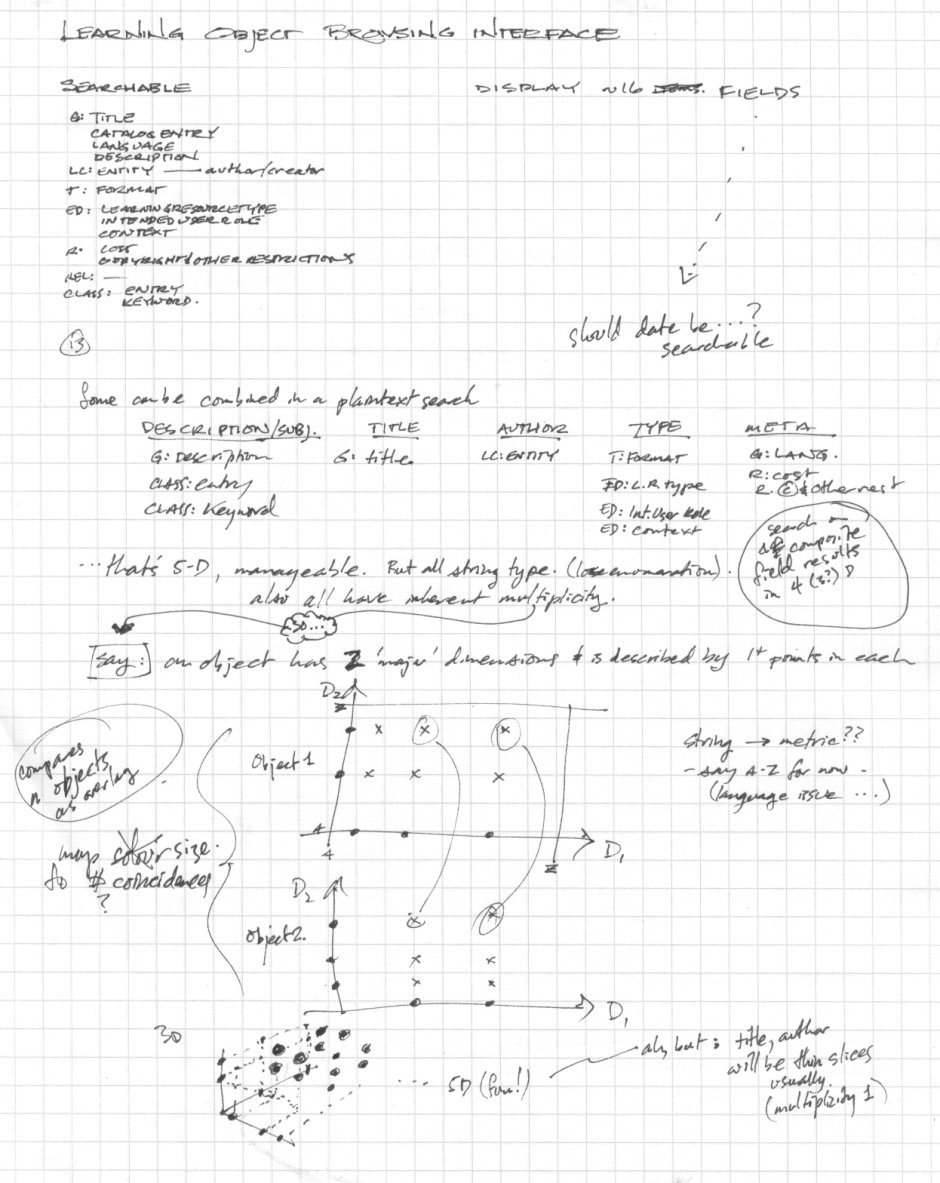
The metadata present in a CanCore XML description is mostly of either string (S), "langstring" (LS) (potentially several instances of a string, each with an accociated language identifier) or enumerated string (V) type, with a few instances of integers (I) and a standard date/time type (D). It is very analogous to library catalogue information. From an initial review of the schema, I have identified fields which should be searchable and fields which should be display only. I have omitted fields that are not of interest to a client. Of course, a client may want to filter based on any of these fields. Also note that the CanCore specification states that all fields are optional, though I bent the rules and insisted on at least a title and URI.
Notes:
There are, by last count, 29 fields of interest in this description, of which 13 or 14 should be searchable. Since none of the data is of a continuous or interval type (other than date), and since the objects described by this metadata are of various kinds and not generally suited for clustering by textual analysis, an approach similar to that of FilmFinder is seen as appropriate for browsing the LOR. Unfortunately, very little of the data to be displayed is ordered, and if it is, the order is of "relevance" as determined by the indexer. Also, most fields have a multiplicity greater than one. Here is a page of idea-generation from the evening of February 12 (click to see full-size in new window):
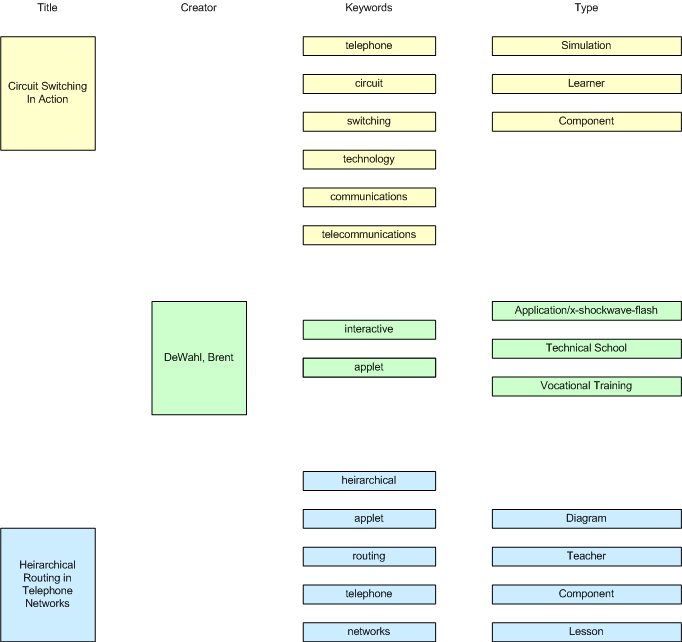
Two problems seem to present themselves: first, it is not apparent how to determine the similarity of two objects in the LOR, and from there to create a metric to determine their separation in (say) spatial coordinates on an infovis display. Second, since one object may be described by multiple points on most of the descriptive dimensions, it may be that only one or at most a few separate objects' information can be displayed in detail and compared using a starfield or scatterplot display (see random scribbling above). If an object's metadata is viewed as a tree (something I am leaning toward) then maybe a side-by-side or overlay comparison would work -- here is a first-attempt idea:
Here I am using the title of the work as the root node, and each column is actually a first-level tree node. Within the columns, items associated exclusively with the "top" object are yellow, those associated exclusively with the "bottom" object are blue, and those common to both are green. This approach will probably not scale well, however if many comparisons of this sort were arrayed in a multiple view (potentially at a reduced scale with greeked or no text), and if one object were held constant, then a fairly large set of objects could be examined for similarity (greenness) to a particular chosen object. |
Proposed Implementation Approach
The platform I intend to use is Java/Swing. The portion of the project I am involved in will also include RMI and JDBC. Since we will be using Java, the choice of platform is not highly relevant, but the project will be developed by several people using Intel and AMD-based Windows XP, Windows 2000, and Linux (RedHat 8.0) platforms, plus a to-be-acquired machine in the ICICS building (OS undecided at the moment). I intend to make use of any pre-existing software and toolkits that I can lay my hands on, but Swing will be the most relevant.