An arbitrary number of contexts are associated with each image. This was done in an attempt to reflect more closely psychological theories of memory encoding, and forms the basis by which subsets of images are selected and displayed in the focus window.
The motivation for this project was to exploit visualization techniques in the design of a tool that could be incorporated into a high level application of use to people with aphasia. However, FaceFinder might also be useful for people with memory difficulties, or as an alternative to a traditional keyword based search when a name cannot be recalled.
Aphasia
Aphasia is an acquired language deficit that is estimated to effect over 100,000 people in Canada [10]. The most common cause of aphasia is a stroke, with other causes including brain injuries and tumors. Aphasia manifests itself in many ways; deficits can occur in one or all language modalities: writing, reading, speaking and comprehension [1]. Language binds us as a species and through language we communicate and express who we are; understandably, individuals and their families can be devastated by the onset of aphasia. Without language, interaction with others becomes more complicated, but is far from impossible. Developing applications to ease the difficulties in maintaining connections to the community is one of the goals of the Aphasia Project, a new project underway at UBC. The task of searching for a face among many images is motivated by the Aphasia Project, and therefore the primary task of this project will be to provide an alternative solution to those requiring that search be conducted using text-based labels.
Data
This project does nothing, unfortunately, to alleviate the need for the initial investment in organizing the data. As each image is entered into the database, personal information, such as a name, address, and phone number, must also be entered. The contexts the user associates with the person is selected from existing contexts, or new contexts can be created and then selected. These tasks are not text-free; however, if the information required by the user is a name and address, entering this data is unavoidable. The contexts that are added are also text based. If the user has a severe deficit, the creation, and any addition to, the database would require the user have assistance.
For this project the data used consisted of 598 images of faces, mainly of actors and musicians. A variety of movie and music web sites were used, and the information found there was helpful in choosing contexts [12]. Ideally, the data should reflect the data that would be used by a user of this tool. Although the images are of faces, the contexts are more clearly defined and limited than they would be when organizing acquaintances, and therefore do not test the adequacy of using context as an organizational tool. The open question is whether too many or too few contexts would be added in total to make context a useful method to select the subset. Since the visualization techniques depend on expanding the area of focus, and the images selected for focus are selected based on context, this choice of data is a serious drawback. However, as this is an information visualization project, it was more important to get an adequate number of images to ensure the scalability of the techniques used, and to test the application against a sizable database.
The area of social network analysis is also relevant to FaceFinder. Using the number of shared contexts as the basis for grouping is related to the concept of distance between two social contacts, a concept found in social network analysis.
The following is a few examples of projects from these two domains.
Multi-Media
The availability of multi-media digital technologies along with technologies to store and retrieve digital content requires that an efficient way to search through the content be developed. Many researchers are working on this problem.
Photomesa
Photomesa [7], developed at the University of Maryland, is a zoomable image browser. This project was the initial impetus for the design of the FaceFinder, with its emphasis on browsing images rather than organizing and annotating them. All images in a given directory structure are displayed, arranged by sub-directories, and no prior image organization is required; although if done, the number of features available will increase, allowing users to group images by the metadata created. Photomesa's biggest strength is the ability it gives the user to search through many images without prior image organization. The pre-processing of images into thumbnails is done the first time a directory is opened, making the initial start up of Photomesa slow; the thumbnails created are stored, and therefore start up is much quicker with subsequent uses.
JDAI
The JDAI [5] (Java Digital Album Infrastructure), also based at the University of Maryland, is a photo organizer for personal photo collections, allowing moving and copying of photos, annotating photos, deleting photos, and creating keywords for photos. A randomized screen show of all photos is on the list of future features.
DIVA
The DIVA [2](Digital Image and Visual Album) project researches techniques for content-based indexing, intuitive access, and retrieval of digital images. The methods used attempt to reconcile the content-based data available through image-processing techniques, with the semantic-based organization imposed on images by the people searching for the images.
Enhanced Thumbnails
Enhanced Thumbnails [3] is a project from Palo Alto Research Center (PARC) that uses enhanced thumbnails to assist in the efficient search of documents. These enhancements are based on perceptual principles, and aim to guide the user's attention to relevant features of the documents.
Visualizing Social Networks
NetVis
NetVis [6] is a tool to analyze and visualize social networks, the patterns of relations or connections among individuals. The data used consists of the names, age, and sex of individuals, how they communicate, and their social distance.
Zooming
Two types of zooming techniques can be used in both the context and focus displays, with a third style accessible in the focus display. An image in either screen can be selected to be enlarged above the existing display, and the entire set can be zoomed in and out as a whole, using a pan and zoom technique. In the focus display, an image can be selected and zoomed in on by steps, with each step being the result of scaling the image by two. Zooming can be easily reversed by clicking anywhere other than an image, bringing all images in the display back into view.
Panning
The entire set of images can be moved as a group in all directions. This allows quicker scanning, replacing a scrolling mechanism if the zoomed out set does not fit into the screen.
Colour
Yellow was chosen as the indicator of a shared context, with the luminance channel changing based on the number of contexts shared:
The arrow indicates the lowest luminance, and this was associated the greatest number of shared contexts, four or more. Three more steps were chosen, with one shared context being indicated by a light yellow, the yellow with the highest luminance. The luminance channel was chosen to carry information because the boundaries of the thumbnails are quite fine when many thumbnails are displayed, and therefore the strength of the luminance channel in conveying high spatial frequencies was required [9]. As well, conveying information on the luminance channel allows those who are colour blind to still use the tool, with hue and saturation being redundant channels to increase efficiency in perception.
Movement
When boundaries change colour, a slight movement is perceived in the periphery, drawing the user's attention to images that share a context but are not be in close proximity to the selected image. This is a useful side effect, as the coloured boundary did not always pop out quickly because the images were themselves colourful, and therefore colour was not a unique target among distracters. Movement is a subtler cue than resorting to stronger colours: stronger colours resulted in it being more difficult to focus on the images.
Cognitive Support
Context plays a critical role in psychological theories of memory [11]. In using context as the basis for reducing the number of images displayed it is hoped that the significant role context plays in the encoding of memory will facilitate the searching problem. The problem with this approach is that it is dependent on the user selecting not only the type of contexts to include, but also the number of contexts.
FaceFinder includes an interface to allow the creation of, and addition to, the image database. Images are selected from a directory, and personal information is added, including the contexts the user associates with the person. New contexts can be added to the application in this interface. When a new person is added to the database, two images are pre-processed, one is a small thumbnail with a maximum dimension of 50 pixels, and the other a medium thumbnail with a maximum dimension of 125 pixels.
The information visualization component of the application consists of a split pane, with all thumbnails appearing in the top, and a subset, those selected to focus on, appearing in the bottom. As the cursor moves over an image in the top display, the boundaries of other images that share a context with the image change from white to yellow. The luminance of the yellow decreases in four increments: as the number of shared contexts goes up, the luminance goes down, resulting in the darkest yellow used bounding images that share the most contexts. If a user clicks the alt key and presses the left mouse button while over an image, all images that share the highest level of context appear in the bottom screen. Clicking the left mouse button alone results in the image with the focus being displayed larger and on top of the thumbnail display.
The default pan and zooming of Piccolo was not disabled. A quick way to reset the view to display all thumbnails was added, and additional zooming techniques were implemented, as described in the section Solution: Information Techniques.
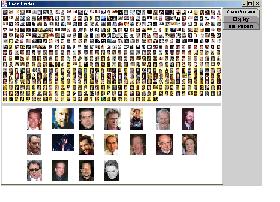
As the cursor moves over an image, the boundaries of images that share context change colour, as can be seen in Figure 1. Left clicking on an image, without pressing the alt key, will result in a larger image floating above the display.
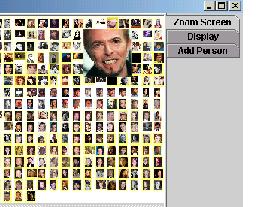
Images can also be enlarged in the focus screen by left clicking.
Images and personal information are added into the database in the Add Person screen, accessible from the main zooming screen.
The contexts selected are critical to later efficient searches. It would be very beneficial if there was some way for this process to be, if not automated, at least supported. Maybe providing a few default contexts, that were easily removed, would be useful. If this application was imbedded in a day planner, information from the day planner could be incorporated into the context, or form a secondary filter layer.
Attributes would be another feature that could filter searches effectively. Attributes would differ from contexts in that attributes would be true of an individual in a context or in relation with anyone, whereas contexts are defined from the perspective of the user of the application. Gender, eye colour, and height are examples of possible attributes, hockey, school, work are examples of possible contexts. Attributes could potentially be obtained from analyzing the images, thus alleviating some of the burden of manually organizing data.
Between 250 images and 400 images, response time deteriorates. This is a large span, and an initial evaluation would be needed to establish a goal for the optimal number of images selected for the focus pane. Once this was obtained, studies could be conducted to determine if the contexts people created resulted in quick selections of a subset of the database the met or passed the optimal number.
When searching in a set of 400 images, participants seemed to increase the amount of zooming in they did, enlarging the images beyond the level they were using to search when faced with a database of 250 images. Further studies need to be conducted to determine if the sheer number of images was overwhelming, or if their minute size was overwhelming, or a combination. This would have implications for small screen displays, but also for the presentation of thumbnails. If the small size is the critical factor, it may be the lack of visual cues contained in small thumbnails. In this condition participants also become lost within the data set, unsure which direction they had already seen. If these two factors are related, that the use of enhanced thumbnails would alleviate the issue, and possibly allow a far greater number of thumbnails to be processed efficiently.
FaceFinder addresses the problem of getting lost by introducing a context panel. A study could be done to determine if this extra pane does in fact make it easier to zoom in and out of a set of images. A great deal or real estate is given up by maintaining two panels, and therefore this study would be of great interest.
Finally, an evaluation could be done comparing the efficiency of searching for a target in FaceFinder with searching for a target in another interface. An alternative interface would be one where all thumbnails were displayed, and users scrolled through them looking for the target. In this scenario, a pilot study to determine the optimal size for the thumbnail would need to be conducted.