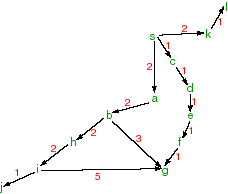
Suppose the neighbours are given by the following relations:
Suppose the heuristic estimate of the distance to g is:neighbours(s,[a,c,k]). neighbours(a,[b]). neighbours(b,[h,g]). neighbours(c,[d]). neighbours(d,[e]). neighbours(e,[f]). neighbours(f,[g]). neighbours(g,[]). neighbours(h,[i]). neighbours(i,[j]). neighbours(j,[]). neighbours(k,[l]). neighbours(l,[]).
h(a,2). h(b,3). h(c,4). h(d,3). h(e,2). h(f,1). h(g,0). h(h,4). h(i,5). h(j,6). h(k,5). h(l,6). h(s,4).
For each of the following search strategies to find a path from s to g:
~cs322/tools/search/search.
s -> a -> b -> h -> i -> g.
7.
It selects nodes in order irrespective of where the goal is.
It reports whatever path it finds first; this could be any path depending on the order of the neighbours.
s -> a -> b -> g.
9.
It selects all nodes that are two steps from the start node, irrespective of where the goal is, before it expands nodes that are three steps away and finds the goal.
It finds the path with the fewest arcs, not the shortest path.
s -> c -> d -> e -> f -> g.
10
It explores the paths in order of length, irrespective of where the goal is.
It wasn't; least cost first always finds the shortest path to the goal.
s -> a -> b -> g.
4
It chooses the node closest to the goal, and doesn't take into account the path length from the start node.
Node a was closer to the goal than node c, once it had nodes on the frontier that were close to goal, it never considered c.
7.
Node a looked as thought it was on a direct route to the goal. But, the deviation to go to b was greater than the cost of going via c.
It wasn't; A* always finds the shortest path to the goal.