416 Distributed Systems: Assignment 5
Due: Mar 10 at 9PM
2016W2, Winter 2017
In this assignment you will build on assignment 4 to create a distributed web crawler that runs in the Azure cloud. Your crawler will collect the web graph of linking relationships between websites starting at certain root sites provided by a client. Your crawler will store this graph in a distributed manner and will be able to respond to several kinds of queries about this graph.
High-level description
A web crawler makes HTTP GET requests to different websites to create an approximate snapshot of the world wide web. This snapshot typically includes web page content, linking relationships between pages, and other meta-data. In this assignment the basic version of your crawler will collect the linking relationships between web pages. For extra credit you can extend this basic crawler with more features.
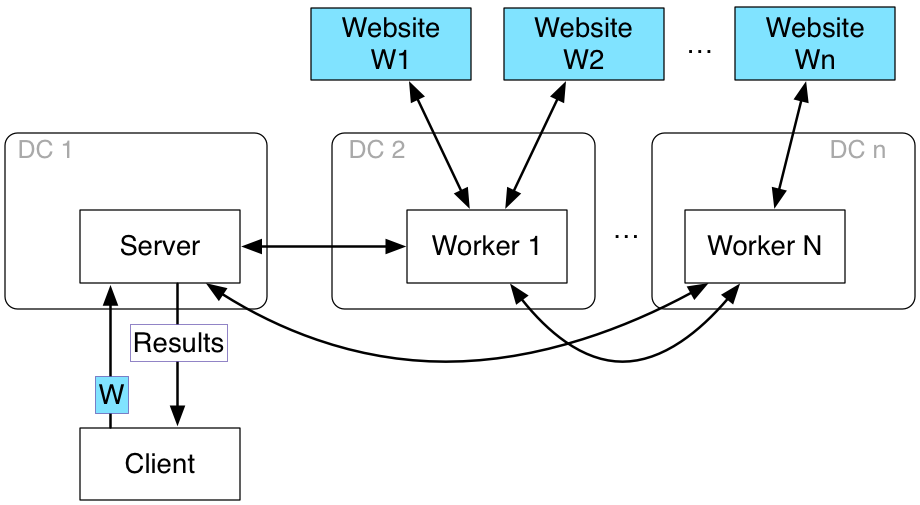
Your crawler components will be similar to those in A4: a server will coordinate several worker processes, which will do the crawling work. The server will communicate with clients through an RPC-based API. Clients can initiate the crawling, specifying an initial web page, and can also query the crawled dataset. As with A4, you should design your crawler system to run on Azure, with each worker and server running in an independent VM.
The details
As in A4 we provide interfaces that your system must use to communicate with the outside world (RPC to the server and HTTP protocol to websites). Internal communication and coordination between the server and the worker processes is up to you to design and implement.
In contrast to assignment 4, workers in this assignment are stateful --- they must store the web graph that they collect during their crawl. A worker can store everything in memory and assume that it will continue running without stopping (i.e., no need to store the graph to disk).
For the basic version of this assignment your graph needs to only encode the linking relationships between web-pages: a vertex is an html page, and an edge indicates that the source page has a link to the destination page (as <a href="...">...</a>). Your graph only needs to include html pages (pages that end in '.html'). Your workers must be able to correctly parse and explore relative URLs (URLs that include '.' and '..', and do not start with 'http://'). For example, the following URL:
http://www.cs.ubc.ca/~bestchai/teaching/../teaching/././../teaching/cs416_2016w2/assign5/index.htmlIs identical to this URL:
http://www.cs.ubc.ca/~bestchai/teaching/cs416_2016w2/assign5/index.htmlYour crawler must understand this and maintain a single page vertex for both versions of the URL.
You must follow the following constraints in maintaining this distributed graph:
- Pages data for any one domain must be stored by a single (owner) worker. We define a domain as the string between 'http://' and the next '/' that follows. So, in http://cs.ubc.ca/, cs.ubc.ca is the domain. This constraint means that pages http://cs.ubc.ca/index.html and http://cs.ubc.ca/otherpage.html (and others in this domain) must be stored by the same worker
- The owner worker for a domain is the worker that is closest to the domain in terms of network latency. The latency between a worker and a domain is the minimum observed HTTP GET latency from worker to the top-level index.html page for the domain. Use the same measurement algorithm as in A4 with a hard-coded samplesPerWorker = 5 (i.e., latency to domain is the minimum of the 5 measurements). That is, you should use the minimum of the minimum latencies from each worker to the domain, where the latency between a worker and a domain is the minimum observed HTTP GET latency from worker to the top-level index.html page for the domain.
- The graph is distributed. That is, some (logical) graph edges start at a page stored by one worker and end at a page stored by another worker. For example, a worker w1 may be responsible for a page that has links to pages hosted by domains owned by another worker w2. In this case w1's graph must have appropriate pointers to nodes in the graph at w2.
- Minimal storage/processing at server. The server's job is to service client requests, it should maintain minimal storage and do minimal processing; these must be instead done by the workers. In particular, the server can only be used to store a map that maps a domain to a worker and can help workers find each other and it should not store the crawled graph. For the overlap computation, the server should not gather/store anything nor compute anything related to overlap. It can/should receive a result for overlap from one of the workers and pass that back to the client.
- Computation on the graph must be distributed. Some queries, such as Overlap, PageRank (EC1), and Search (EC2) must be computed in a distributed fashion by the workers.
The server must listen to connections from one client as well as several workers. The server must be able to handle an arbitrary number of workers. The server must handle exactly one client that connects and invokes several RPCs. The client can invoke four kinds of RPCs against the server:
- workerIPsList ← GetWorkers()
- Returns the list of worker IPs connected to the server.
- workerIP ← Crawl(URL, depth)
- Instructs the system to crawl the web starting at URL to a certain depth. This is a blocking call: your system should complete the crawl before returning. For example, if depth is 0 then this should just crawl URL. If depth is 1, then this should crawl URL and then recursively crawl all pages linked from URL (with depth 0). This call must return the IP of the worker that is assigned as owner of the domain for URL. Your crawler should accumulate information with each Crawl invocation.
- domainsList ← Domains(workerIP)
- Returns a list of domains owned by the worker with IP workerIP.
- numPages ← Overlap(URL1, URL2)
- Returns the number of pages in the overlap of the worker domain page graphs rooted at URL1 and URL2.
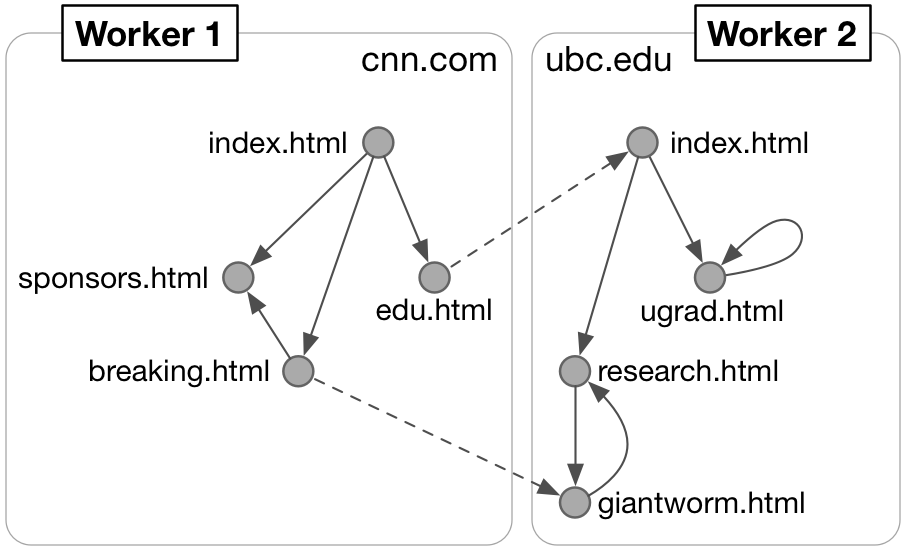
Overlap computation: given URL1 in domain D1 and URL2 in domain D2, overlap can be computed as follows: (1) compute the reachable graph within D1 from the page vertex corresponding to URL1, call this graph G1. (2) Compute a similar graph within D2 for URL2, call this graph G2. (3) Count the number of edges emitted from nodes in G1 to nodes in graph G2, and the number of edges emitted from nodes in G2 to nodes in G1. The sum of the two numbers is the overlap.
For example, the diagram on the right shows a distributed graph (of just two sites) stored by two workers. For this graph Overlap(http://www.cnn.com/index.html, http://www.ubc.edu/index.html) should return 2 (the two dotted edges). But, Overlap(http://www.cnn.com/edu.html, http://www.ubc.edu/research.html) should return 0. In this example, G1 includes the vertex [edu.html], while G2 includes vertices [research.html, giantworm.html]. None of the vertices in G1 are accessible from G2, and vice versa. Therefore overlap is 0.
Unreachable URLs. Your web graph must represent links to pages (if you fetched those pages), regardless of whether or not those pages were reachable. For example, if your crawler is at page p and p has a link to page q. If depth is n > 0, then the crawler has to fetch q to continue crawling. If the web server that is hosting q is unreachable (for whatever reason), then you have to do two things:
- You should have a node for q in your web graph and you should have a link from p to q in your graph.
- You should terminate (this particular crawl instance) at q: since you cannot fetch the page content of q, you cannot continue the crawl (follow links) from q.
Crawl depth. Crawl of depth 0 at URL U should result in one node in the graph -- the node corresponding to page at U. There should be no other vertices or edges in the graph.
Crawl of depth 1 at URL U should result in 1+N nodes: the node corresponding to page at U, and N vertices that are linked to from U, one per anchor tag in the content of U. There should be no links from each of these child page nodes. There should be no other vertices in the graph.
You can test and debug your solution using the sample client code that we provide to you.
Assumptions you can make
- Your crawler should only handle HTTP links.
- Overlap will only be invoked on canonical URLs of pages (will include http prefix and html suffix) that have been crawled. Note that these are not necessarily the URLs that appeared as arguments to Crawl.
- Overlap will only be invoked on URLs in different domains.
- A worker can be an owner for multiple domains.
- Domain ownership does not change (you do not need to continuously measure latency to domains).
- You can assume that the web-graph you are crawling is static and does not change. That is, you do not need to re-crawl.
- The server will start at least 3s before any worker.
- There will be at most 256 workers.
- All workers will start at least 3s before a client will issue a request.
- Assume that round-trip time latency between any worker and the server is less than 1s.
- The server and workers do not fail and are always reachable.
- The client will wait indefinitely to receive a response from the server to the above RPC invocations.
- The website URL specified by the client is reachable by all workers and the website speaks HTTP over TCP port 80.
- For this assignment you do not need to follow robots.txt web crawlers policy.
Assumptions you cannot make
- You cannot assume where the worker or the server are located.
- You cannot assume anything about the target URLs being crawled or make assumptions about the structure of the resulting web graph.
Implementation requirements
- The client code must be runnable on Azure Ubuntu machines configured with Go 1.7.4 (see the linked azureinstall.sh script and the Google slides presentation for more info).
- Your solution can use the html package for parsing links from HTML. You can assume that it is installed in our marking environment and that you can import it as "golang.org/x/net/html". Besides this external library your solution can only use the standard library Go packages.
- Your solution code must be Gofmt'd using gofmt.
Extra credit
The assignment is extensible with three kinds of extra credit. You must create an EXTRACREDIT.txt file in your repository and specify in this file which extra credit features you have implemented.
EC1 (2% of final grade): Add support for computing the page rank of a crawled website based on the current distributed graph. In computing page rank you should follow the same constraints as in computing URL overlap (described above). That is, this must be a distributed computation. In your algorithm, use the formula PR(A) = (1-d) + d (PR(T1)/C(T1) + ... + PR(Tn)/C(Tn)), use a precision value of 0.01 (i.e., if you get a new page-rank value that differs from the prior iteration by less than this amount, then stop), and use a damping factor d=0.85. Refer to the original paper and this explanation for more details on the algorithm. Supporting page rank will require you to add a new RPC call to the server:
- rank ← PageRank(URL)
- Computes the page rank of a URL. URL that has not been crawled should return a rank of 0.
EC2 (1% of final grade). Add support for exact (case-sensitive) string search (for non-tag strings). For this, first extend your crawler to store page contents. Then, extend the server with an RPC that allows a client to query for a list of URLs that contain a particular string. Your search implementation must be distributed and follow the same constraints as with computing URL overlap (described above). The returned list of pages must be ordered in decreasing order of string occurrence on the page. You will also need to add a new RPC call at the server:
- urlList ← Search(searchString)
- Returns an ordered list of URLs that contain searchString.
EC3 (2% of final grade). Add support for adding new workers to the system. This EC lifts the assumption that domain ownership is constant and does not change. You will have to implement web-graph migration (since the new worker may be closer to some domains that have already been crawled). And, you have to provide proper concurrency control for ongoing client operations --- Crawl, Overlap, PageRank (if including EC1), Search (if including EC2).
Solution spec
Write two go programs called server.go and worker.go that behave according to the description above.
Server process command line usage:
go run server.go [worker-incoming ip:port] [client-incoming ip:port]
- [worker-incoming ip:port] : the IP:port address that workers use to connect to the server
- [client-incoming ip:port] : the IP:port address that clients use to connect to the server
Worker process command line usage:
go run worker.go [server ip:port]
- [server ip:port] : the address and port of the server (its worker-incoming ip:port).
Advice
- It is important that you compute a canonical URL for each page you access. There are many ways to refer to a page on the web (e.g., using relative URLs). You do not want these non-canonical links to create copies of the same page in your graph.
- Create a web sandbox within which you can test your crawler. Make this sandbox small and experiment with HTML syntax as well as linking relationships between your pages. Do this first, before crawling any public websites.
- You can run a web-server with your web sandbox on Azure. This way you can have your crawlers explore several different domains.
- By deploying your web-servers to different data centers, you will be able to debug your worker latency computation (which determines worker domain ownership).
Client code
Download the client code. Please carefully read and follow the RPC data structure comments at top of file.
Rough grading rubric
- 10%: GetWorkers RPC works as expected
- 10%: Crawl RPC works as expected
- 30%: Domains RPC works as expected
- 50%: Overlap RPC works as expected
Make sure to follow the course collaboration policy and refer to the assignments instructions that detail how to submit your solution.