V3DR
A benchmark for video-based mocap retrieval
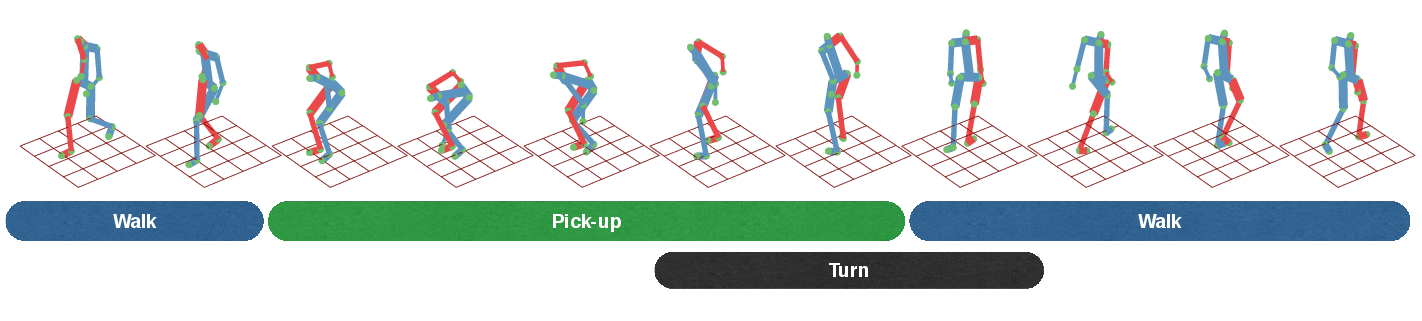
V3dr is the first benchmark for quantitative evaluation of mocap retrieval. V3dr uses 2000 files from CMU-mocap as database and provides a set of video queries. For a more detailed explanation of the benchmark, check out our paper below.

Video queries taken from YouTube with their top retrieved mocap sequences.