Traditionally, file systems have been based on the notion of a hierarchy. There are two primitives in these hierarchical systems:
Directories are called 'folders' in some simpler OSes. Files are named objects and the names are unique (i.e., you cannot have two files with the same name). Over time, various applications have required the ability to build up databases of files that are queriable. E-mail clients, photo software, word processors, and other applications end up building their own databases so that users may query their data. However, this repetition by all applications points out a deficiency in the design of current file systems.
Application developers are building databases of files on top of hierarchical file systems; this common functionality should be refactored into the file system yielding a file system that is itself a database of files. The hierarchy notion will be disbanded. The SpoonFS project will provide an implementation of this database file system. Features will include type-safe attributes, anonymous and named relations of files and fast query time.
Switching to a relation file system holds great advantages to users. File meta-data can be removed from the files themselves and become attributes of the files in the file system. This abstraction will allow the file system to know about meta-data and to operate on it directly. The users can now search for files based on meta-data or many-to-many relations rather than having to decide on a strictly hierarchical one-to-many directory relationship.
With the new paradigm of file storage comes new challenges. All existing file browsers and explorers are based on the notion of a strict hierarchy. All existing file searchers follow the flat list metaphor. Both of these concepts were necessary in the old file system, but neither of them are compatible with a non-hierarchical relational file system. The hierarchical browsers simply won't work since there is no notion of hierarchy, and the flat list metaphor buries and hides the richness offered by the meta-data and additional relations. A new file explorer is needed. This document outlines a proposed new file explorer: Spoon Explorer.
The visualization project is to create a new file explorer for the SpoonFS project, which is a non-hierarchical relational file system. The viewer must allow the user to both search and browse for files, and to see a meaningful representation of results.
The task for the user in using the Spoon Explorer is to find files. The user may want to find a particular file (the most recent draft of the proposal for a given project), a group of given files (all photos of Candice on any of her vacations), a group of unknown files (the largest files that have not been accessed in the past two months), or to see files that are related to a given file (all documents related to a specified proposal).
The Spoon Explorer is to serve two purposes. First, it is to be the primary explorer for the development and demo of the SpoonFS system. Second, it is to represent a proposed interaction system for a generalized relational file system. The goal is to make a system which will be useful to both power users (the developers of the system) and to every-day users.
To limit the scope of the project, file types handled by the system will be limited to the following:
Since the purpose of SpoonFS is to pull the meta-data for these files into the file system, the file system will own their specification.
The system will be expected to handle a "normal" amount of files of each type. My personal directories contain approximately 3,300 music files, 850 images, 3,300 documents, and 100 contacts. All of these file types, except for "documents," have well-defined classes of meta-data. The meta-data for the "document" type has yet to be well-defined.
This proposal ties in with my Operating Systems project, namely the SpoonFS file system. I have been reading, researching, and planning the operating systems side of the project for the last month, and it is reaching the finalization stage for its requirements (the API has not yet been finalized).
I have no prior experience with file systems, or with implementing visualization systems, file explorers, or novel GUIs. I have some relational database experience.
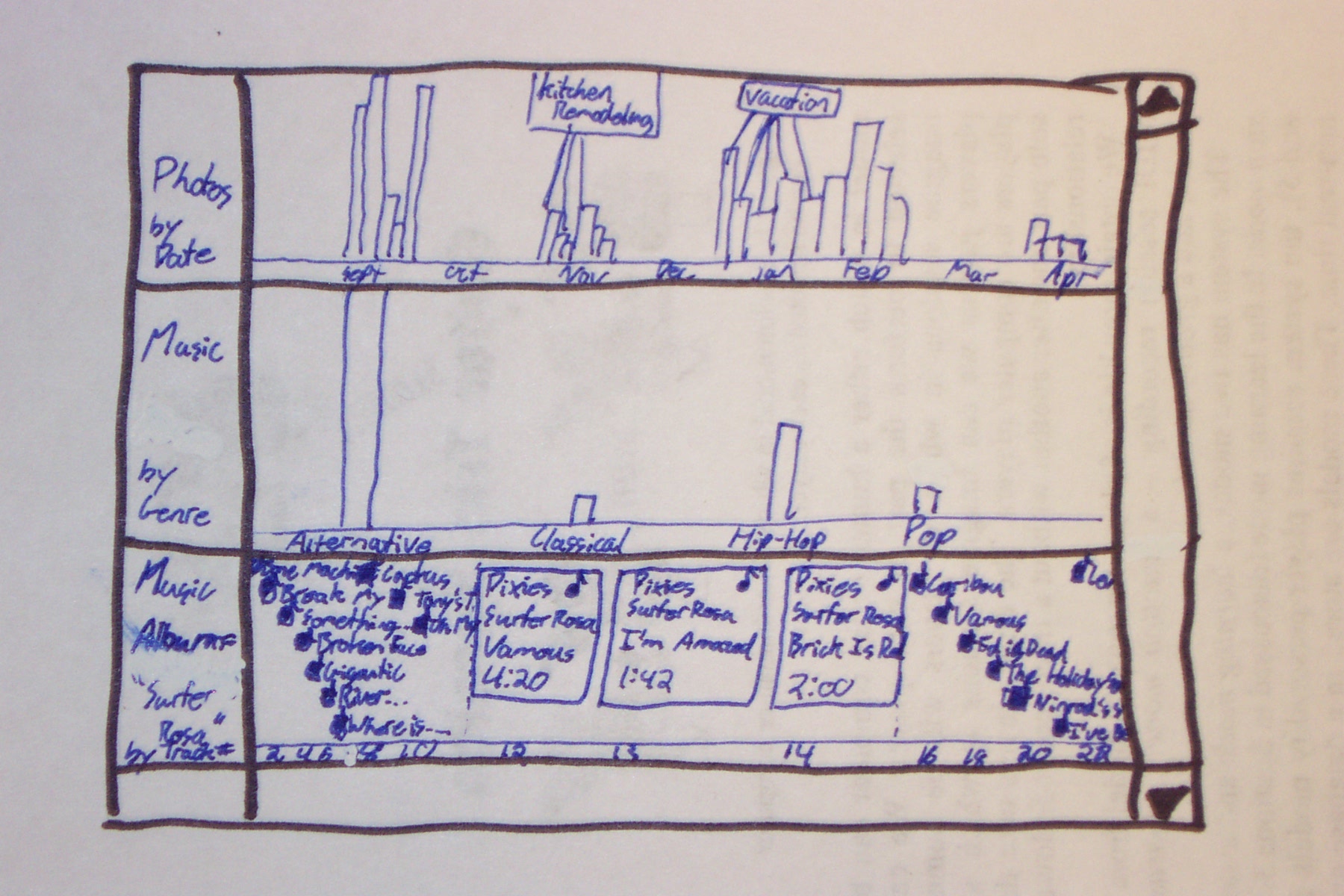
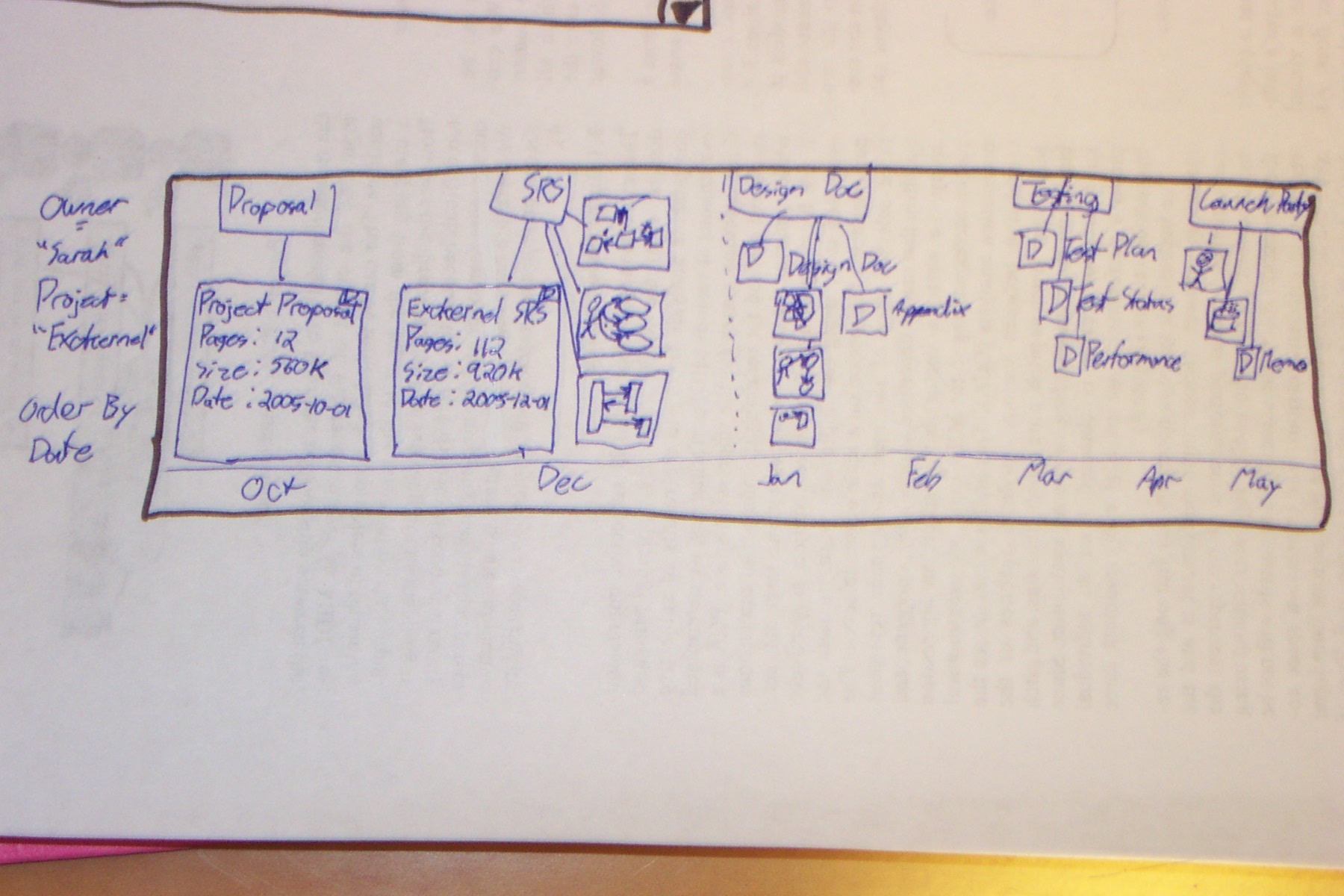
The proposed solution is to implement a multi-paned view into the file system. On application start, the user will be presented with a series of bands across the screen representing views onto the file-system.
Each band represents a single view onto the file system. It is analogous to a directory view in a traditional file system, but rather than having its contents be the contents of a specified directory, it represents a view onto the files which satisfy the search query corresponding to the band.
The contents of a band should be orderable according to a user specified attribute. The system should respect any reasonable ordering specified by the user (one for which a partial order exists). For example, the most common orderings expected are file size, date created, or date last modified, but a user could concievably want to order images by their resolution or some alphabetic ordering of any attribute.
Some ordering attributes may be quantitative while others may be simply ordinal. In the ordinal case, it is expected that elements of the band are simply layed out one beside the other. For quantitative orderings, it is expected that the quantitative position holds meaning, and that gaps between elements hold meaning.
The user should be able to directly alter the search query. The user should also be able to refine the query by selecting meta-data about a displayed document and choosing to filter the query (positively or negatively) on that attribute's value. The refined query should appear as a new query band below the existing one.
The results of the query are displayed in the band. The band must support multiple levels of zooming. For very large results (beyond a few hundred) the band should not attempt to render representations of the actual documents. It is proposed that instead the band show a histogram indicating where the files fall in the ordering. This does not seem particularly clever for non-quantitative order attributes, but no other solution is immediately apparent. The user can select on an area to zoom to with the mouse.
For display results of less than a few hundred, it is proposed that the band displays a semantically zoomed prospective wall. The "far" part of the prospective wall will contain glyph representations of the data and the "near" part will show a more meaningful representation. Images are proposed to be represented by thumbnails, documents by glyphs and meta-data, music by glyphs and meta-data, and contacts by a representative image and meta-data.
The SpoonFS allows for named relations between files. These are essentially labels. Labels should be displayed above the average position of its elements and each element should be visibly linked to the label by a line. Labels which contain a large number of elements should be culled.
SpoonFS also allows for unnamed relations. These are groupings of files which are considered related to one another, but not deserving of a first class name. If files in an anonymous relation are near each other, they should be linked together by edges. If they are far, then the user should be able to select the file and press a button (or key) to have the related files become highlighted.
The system will be implemented in Java.
| Nov 12 | GUI skeleton |
| Nov 12 | Test stubs |
| Nov 12 | Ability to change initial queries |
| Nov 19 | Display for fixed of histogram for large data |
| Nov 19 | Scrollable rendered view for small data sets |
| Dec 19 | Add relations to rendered view for small data sets |
| Nov 26 | Semantic zoom for medium and small data sets |
| Dec 3 | Click histogram to semantic zoom |
| Dec 3 | Filter queries on meta-data |
| Dec 10 | Change order parameters |