Jordan Lee
61550984
CPSC 533C
01 Mar 04
InfoVis Project
Proposal: Powerset Explorer
Description
This information visualization application is targeted towards the field of data-mining. Traditionally, data-mining is a highly intuitive field where human intuition prevails. However, without much expertise in the dataset and a little bit of luck, it is difficult to extract information from the database. Furthermore, as the information quantity increases, the problem quickly becomes very difficult if not impossible.
More recently, the problem has been tackled by using immense quantities of resources to use brute-force analysis along side of artificial intelligence. However, with the abundance of information being stockpiled, analysis of such data is extremely costly and increasing exponentially.
One popular area of data-mining is the analysis of transaction databases. For example, Walmart contains transaction databases of tremendous proportions. This application hopes to be able to aid in the analysis of transaction databases of dataset size 100-1000. However, it will not focus on the data retrieval aspect of data-mining, only the analysis. It will take advantage of human intuition in pattern recognition. It will be highly scalable by using focus+context type visualization. And, there will be no dependence on the dataset. Therefore, the user will need no prior expertise of the dataset.
Scenario of Use
This application consists of a client interface and a server database application. The server database application sends database entry information across the network to the client interface. The client interface can request that the server refines its search parameters.
Upon initialization of the client application, the user must select a database server to connect to. (Image #1) Once selected, the client can then connect to the preferred database server and send the server some initial constraints to implement on the database. The server will then send its responses across the network to the client application.
As information is interpreted by the client application, a rectangle will be rendered onto the screen to represent the chunk of information. Depending on the application, different methods of display can be employed to display the information. (Image #2)
At any moment, the client can interrupt the server and update its list of constraints to further reduce or increase the server’s response. Following receipt of the requested information, the client can then browse the returned information via a focus+context style navigation. It is possible to “mark” certain information chunks to allow the user to landmark certain important chunks. (Image #5 and Image #6).
The user can also expand or shrink certain areas at will. This allows the user to “drill down” into complex information areas. (Image #3 and Image #4).
Proposed
Implementation Approach
This application will be developed in Java to ensure portability between operating systems and platforms. It will be primarily developed on a unix machine with large quantities of memory and CPU cycles. The TreeJuxtaposer architechture by Tamara Munzner will be modified to fit the above mentioned specifications.
Milestones
#1 Completion of the basic visualization of a randomized database of small set size (~10)
#2 Addition of a single level of “marking”.
#3 Addition of multiple levels of “marking” (6)
#4 Addition of background marking to demarcate areas of sets containing different amounts of items.
#5 Implement multiple constraints
#6 Increase maximum possible dataset size to at least 100.
Image #1
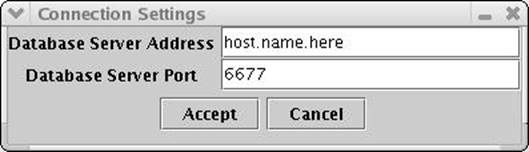
Image #2
Image #3
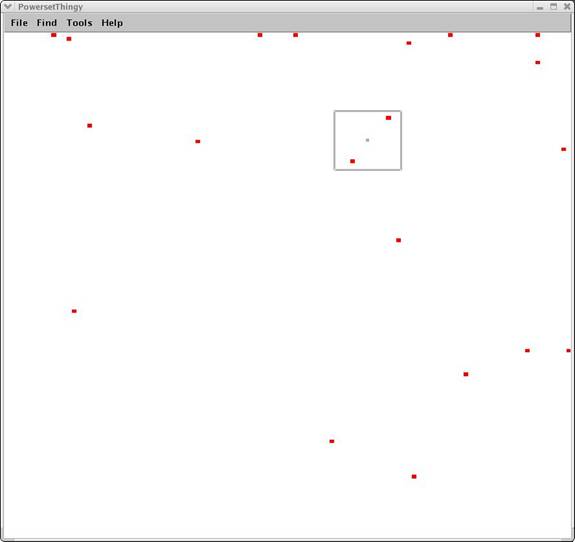
Image #4
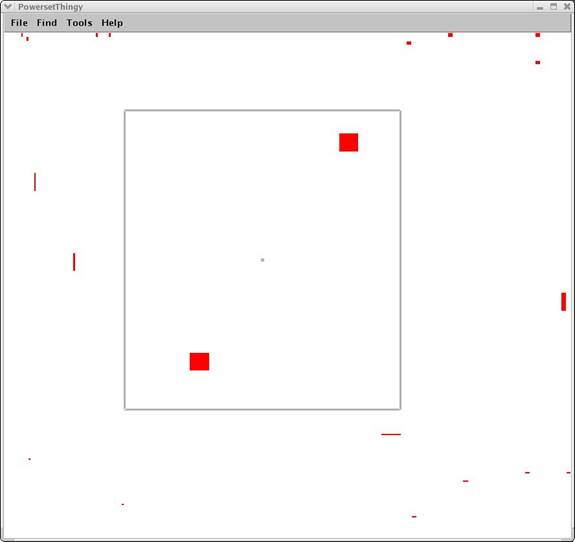
Image #5
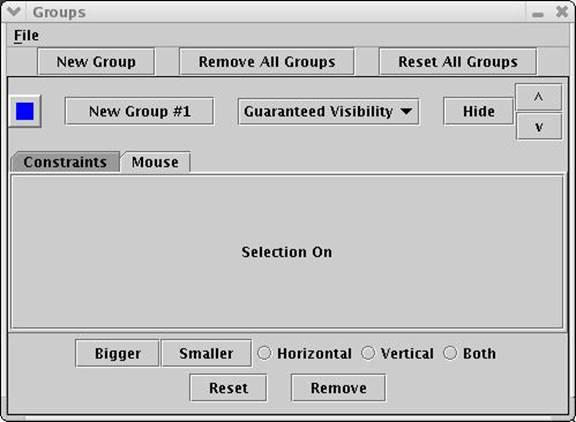
Image #6
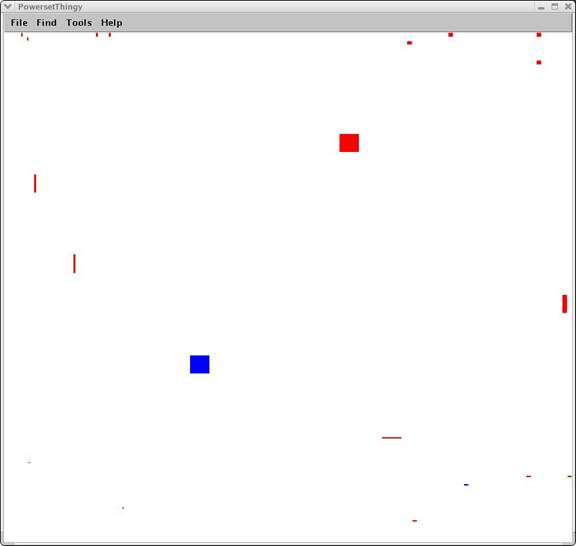
Image #7