CPSC 533C -
INFORMATION VISUALIZATION
PROJECT
PROPOSAL
Monday, March 1st. 2004
Team: Juan Gabriel Estrada Alvarez
(estrada@cs.ubc.ca)
DOMAIN
Heart disease is often one of the medical areas where doctors
spend much time - critical for any patient who might be affected by a severe
illness - trying to diagnose or narrow down the possibilities for what exactly
may be going on with a patient. This is in addition to diseases that may not
have yet been discovered, due precisely to this difficulty. One of the things
that most doctors would like to do in an easy - and not so cluttered - way is
to analyze time-series data corresponding to pulse intervals and/or blood
pressure. With an appropriate tool to do this, they might be able to perform
faster and more accurate diagnoses. Much study has been given to how Fourier or
Wavelet analysis can be used, but it is only until recently that new tools have
enabled researchers to gather enough data for time series long enough to do
further study. In this paper I propose to apply some techniques already in use
in InfoVis, particularly on clustering, to examine
some of the data recently taken from rabbits and rats. It shall be as an
alternative to Fourier or Wavelet analysis solutions, which are often hard to
interpret.
PERSONAL EXPERTISE
As part of my B. Sc. requirements, I worked on a
project whose goal was to develop a visualization of the data mentioned above.
In this project I became familiar with the data format used by the researchers
who initially posed the question of developing such a tool, to visualize the
thousands of time series they had recorded (and are still recording). As a
result I have several sources for data to further test. I have no previous experience
with clustering techniques. Similarly, I do not have a life sciences
background, save enough to be able to extract the data to be analyzed.
Notwithstanding, the data conversion code and the visualization proposed in the
past project might be useful for our current purposes.
THE SOLUTION
The solution will try to use clustering to try and
categorize the different time series available.
That is to say, the tool would ideally group the different types of time
series into clusters that correspond to the same "state of the
heart". Examining a cluster would then mean to examine the individual time
series contained in it. Upon examining a particular series, information about
its origing would be displayed and perhaps other
visualizations might be chosen for it (e.g. the 3d fractal terrain view that
was presented in the earlier project). At both the cluster and individual time
series levels, a querying tool like the one presented in the TimeSearcher application (Hochheiser,
H. Shneiderman, B. Visual Queries for Finding
Patterns in Time Series Data University of Maryland, Computer Science Dept.
Tech Report #CS-TR-4365, UMIACS-TR-2002-45) would be of utility to researchers
and allow comparison of time series that are not necessarily in the same
cluster. Given the lengths of the series available, the user would first be
presented with an overview on which she can zoom in as necessary (i.e. present
the data in different time scales). Finally, if and once a categorization can
be achieved, diagnosis would be realizable by providing a patient's recorded
time series as input to the tool and evaluating in which cluster it is
assigned.
SCENARIO OF USE
Under the current conception, the user would perform
the following steps in order to process data:
1) Load the data set from the file menu;
2) Select the kind of
clustering to be done on the data set from the clustering menu;
3) Once the clustering has been completed, the query
display will be updated showing an average time series per cluster;
4) The time series browser window will also be updated
and will display individual series;
5) The user may perform queries on the browser window
by using "time boxes" as defined in the TimeSearcher
application. Zooming on both the query window and the series browser is also
allowed. Which action is being carried out is specified by pressing an icon in
the lower left panel;
6) Upon placing a query (or timebox)
the query window is updated by showing only those cluster series that meet the
boundaries of the timebox. Similarly, the series
browser is updated to show only the time series in those clusters.
7) The user may refine queries by placing further timeboxes, which causes step 6 to be repeated;
8) The user could zoom in in
the query window on the resulting clusters. At this point, the series browser
might be refreshed to show the corresponding regions zoomed in. Zoom out would
have the same effect;
9) The user can now play with the categorizations and
determine if another kind of clustering might help instead.
Overview of
a possible arrangement of the application window:
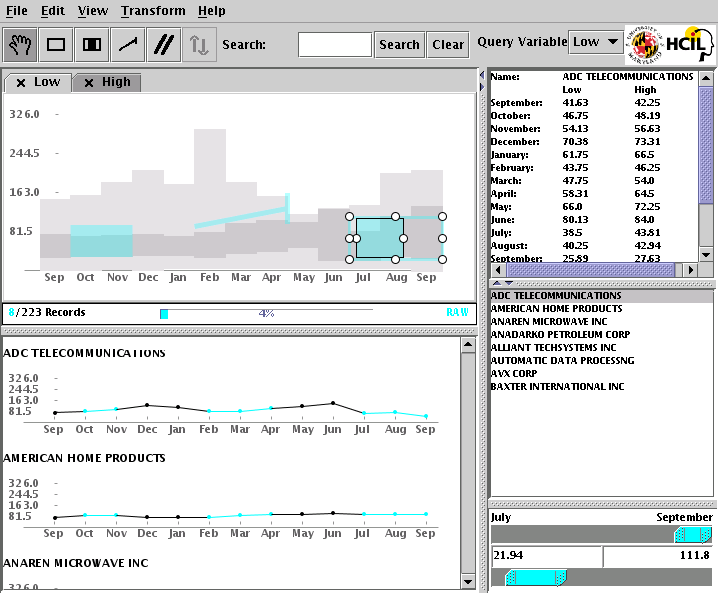
Clockwise from upper left: i)
time series browser; ii) individual info display, if available; iii) list of
the series currently being displayed; iv) possible sliders in order to fine
tune queries and zooms; vi) utilities panel, where zoom, query and cluster
icons reside. Note that this example is a snap of the TimeSearcher
application running. TimeSearcher does not do the
kind of clustering that is our objective and so its utilities panel does not
meet our needs. This layout is currently only an idea and will most likely
change. In particular, we may need the query display to be much bigger, and the
series browser to be displayed only when requested.
The possible
clustering menu:

The user can select among clustering approaches (if
available) and the number of clusters to produce.
How timeboxes and zooming would work:

Each timebox refines further
the amount of clusters displayed. Starting from the right, each query filters
out more clusters until we arrive at the leftmost graph. Zooming is performed
similarly, but the boxes are light transparent red instead of blue and do not
filter out clusters.
IMPLEMENTATION
Existing code for the previous project's visualization
is written in Java 2, whereas the format converting code is written in Mathematica. Current plans would rewrite the code into Java
2 and Also make use of the Piccolo toolkit (for Java)
for zoomable interfaces. Some of the existing code in
TimeSearcher - namely the querying code - would be
useful as a base. The goal is that the tool will be hardware independent.
PHASES
·
Contact the authors of TimeSearcher for a possible use of their querying code.
·
Establish and implement the
clustering algorithm(s) to be used.
·
Implement visualization through zoom
able 2D time graphs. Integrate the querying tool to the main display graph.
(Depending on the response from the authors of TimeSearcher,
this might have to be implemented from scratch)
·
Implement the GUI.
·
Integrate the visualizations into
the display
·
Determine if inclusion of the
visualization from the previous project can be useful and proceed to integrate
it as an alternative view.