CPSC 533C Project Proposal 3
Exploratory Browsing in Music Space
by Heidi Lam (hllam@cs.ubc.ca)
Introduction
The motivation behind the proposed project is to investigate how the interface
can support fuzzy information seeking behaviour. In general, information
seeking behaviour can be classified based on the amount of information the user
has regarding the nature of the target and its location:
| |
Specified
Target |
Uncertain Target |
| Specified Location |
Navigation if a map of the space is present;
Otherwise, exploration
Redundent encoding (target and location) to evaluteif the target is found
|
Navigation if a map of the space is present;
Otherwise, exploration
Single encoding (location) to evalute if the target is found
|
| Uncertain Location |
Search/find with static
evaluation (i.e., looking for something defined) |
Browsing with potentially
dynanmic evaluation (i.e., target is ill-defined, and its properties
may change/be refined along the process). |
Table 1. Matrix of information seeking behaviours. By "uncertain",
I am referring to cases where the user may have some ideas about the target/location,
but these ideas are not specific/fixed.
Based on the nomaclecture described in Table 1, current search tools (e.g.
the file search tools provided by the Windows OS) are mostly designed for "search"
and "find" activities, and structured visualizations of the entire
space (e.g., the hierachical file Explorer) target navigation. To some degree,
search engines (e.g., Google search) supports browsing behaviour, but the support
is suboptimal.
Not surprisingly, the goals and natures of these information seeking tasks
differ. For tasks that at least one of target or location is specified, users'
goal is to obtain the target as quickly and as directly as possible. In short,
the process is not important to the user; the goal is. In these cases, the system
should provide the best algorithm to find information that matches the input
search terms, and rank them in a meaningful order. For the display, the main
purpose is to display these results in order, in enough detail to allow the
user to effectively evaluate the search results before viewing the entire piece
of information, and in a spatially compact manner to allow scanning. For example,
Google displays search results as a list ordered by relevance, and for each
results, lines of text where the search terms are found within the document
are included provide context for the user to evaluate the relevance of the obtained
web page. In the ideal situation, the user would be able to find the target
in the first few retrieved results, and the goal of the seeking task is accomplished.
Even given a perfect retrieval algorithm, the effectiveness of these kind of
tools hinges on at least three factors: the user's ability to summarize their
targets as search terms, their ability to convert those terms into a valid boolean
expression, and the ability for the display to provide enough context for evaluation.
Extracting search terms is arguably easier for if the target/location is specified,
but would be much more difficult in the case of browsing. Also, it is known
that most users have difficulty converting their search ideas into correct boolean
expressions, partly because the way we use "and", and "or"
in natural language differs from that in logic statements. As for the display,
while it may be easier to provide enough context for evaluation for text-based
information, either with text, and/or the thumbnail of the documents, music
information is more difficult to summarize.
For the task of browsing, the goal may not be just the target itself, but also
the satisfaction derived out of the process of browsing ("getting there
is part of the fun"). Also, since neither the target nor its location is
specified and fixed, refining the query criteria becomes an important part of
the process. In this case, not only the context of the individual information
retrieved is required (for evaluation), its association with the rest of the
retrieved results is important as well to give the user some idea as to where
to go next in their browsing process. Such browsing experience is well-known
to most of us. Imagine the situation where you walk into your favourite kind
of store without knowing exactly what you want to buy. You may navigate first
to your favourite area within the store (e.g., the Classical section of a music
store), and look for your favourite composer (e.g., J.S. Bach). While browsing
(e.g., going through the Bach collection linearly, or scanning the available
collection), one of the records you come across may catch your attention (e.g.,
a jazzified version of Bach). At this point, you may wish to navigate to another
part of the store based on what you have seen (e.g., the Jazz section).
This project is therefore an attempt to capture some of the essence of this
kind of browsing experience on a computer interface. The rest of the proposal
will provide further details for the domain (along with my personal experience
of the domain), the task, the dataset, the proposed info vis solution, and a
scenario of use illustrated with two initial design prototypes. The proposal
will conclude with a time-line.
Domain
This project is in the domain of browsing among music files for entertainment
purposes. There are two aspects of the domain: visualization in information retrieval,
and music files. An important part of the information retrieval systems is the
algorithm to select and rank search results. This is not the focus of the current
project, and will only be briefly mentioned in the "Dataset" section.
In terms of visualization, most of the efforts are invested in text-based documents.
Some researches focus on visualizing the entire information space (e.g., InfoSky
[Kienreich et al, 2002]). Since this is not the nature of my proposed task,
I will focus on approaches that views a subset of the information space based
on user input query terms. Within this area, there are systems that combine
searches from different sources (i.e. meta-searches, e.g., MetaCrystal [Spoerri,
2004]). This is potentially relevant to the current task, but not directly pertainent
in my proposed domain and will not be further discussed in this proposal.
For query-criteria based from a single data source, there are four basic approahes
to visualizing the retrieved results:
(1) Spatial: Retrieved results are clusters into grouped based on
keywords, and displayed spatially. Some displays delineate the relationships
between these keywords (e.g., as a Venn diagram in InfoCrystal [Spoerri, 1993],
Cougar [Hearst, 1994] and VQuery [Jones, 1998], a modified Venn diagram in
Cluster Map [Fluit et al., 2003]), while some only present the clusters (e.g.,
Lighthouse with clusters and linear list with page names [Leuski & Allan,
2000]; VISER for images [Uptill, 2000]; BEAD on a 3D terrain [Chalmer, 1993],
and MusicPlasma). Some displays multiple
query results spatially (e.g., Sparkler [Havre et al., 2001]).
(2) List: Retrieved results are displayed as a linear list. This is
the 1D case of spatial displays. Stuff I've Seen presents results in a manner
similar to Google, and clustered by dates of the documents [Dumais, 2003].
VIEWER [Berenci, 1999] augments the linear list with distribution of query
terms among the retrieved data.
(3) Temporal: Retrieved results in the context of timelines. For example,
Milestones in Time provides personal events as landmarks on the time line
for the retrieved results [Ringel, 2003].
(4) Integrated: Multi-view with combinations of the above approaches.
For example, InfoSpace provides both spatial and temproal views [Ravasio,
2003].
To my knownledge, there are very few visualization systems that explicitly
support refinement of queries with new query terms. There are, however, systems
that support dynamic queries, where the values of existing query terms can be
modified interactively, and the system provides immediate feedback (e.g., HomeFinder
and FilmFinder [Ahlberg & Shneiderman, 1994]).
In terms of music files, they differ from text-based files in the sense that
it is difficult to compactly summarize their content. While the "list"
approach may be able to provide enough context for the user to evaluate the
search results in cases of text-based information, this may not be the case
in music files. It is possible to summarized music by a number of tags: composer,
title, performer(s), instrument (including vocal), and genre. To further characterize
the music, Eric Brochu at UBC dervied a system that can automatically assign
labels (e.g., "agressive", "bittersweet") (more details
in the "Dataset" section).
In terms of experience, I am currently a student in information visualization
coming from a background of human-computer interaction. For the musical aspects,
I have training in classical piano (Performer's Licentiate from Royal School of
Music, UK), played ensembles with students from the School of Music at UBC, and
a life-long passion with music in the Classical and Jazz genres. I have on-and-off
follow the Hong Kong/Taiwan pop-music culture, and recently, rap music.
Task
A typical task for the tool is to select a piece of music
for entertainment. The user may only have a fuzzy idea about the music he is
seeking, and can vaguely conceptualized with words like "celebratory",
"soothing" or "cheerful", or by genre like "Jazz"
or "Rock". The user will wish to explore the space to better conceptualize
his target piece of music and to help pin-point his search goals.
Here are some estimations of the dimension of the display.
Based on 2697 searches on online documents performed by participants
in their user study, [Hertzum& Frøkjær, 1996] found that 97%
of the free-style logical queries could be represented by a 3-term Venn diagram.
They concluded that limitation of a 3-term Venn would be of marginal importance.
Despite multimedia browsing being different from text searching, my initial
design allows up to three input terms per query, since with less specific targets,
users will more likely to have less instead of more input terms. As for the
total number of queries per task, the same study found that the number of queries
required to finish search tasks was 7.4 using logical statements, to 9.4 using
Venn diagrams on average. The average number of threads (queries without shared
keywords) in logical queries was found to be 2.5, and 1.5 using the Venn diagrams.
This, on the other hand, will unlikely hold in the browsing scenario with a
less defined target. From my experience, such behaviour is more likely to be
limited by the quality of the retrieved results (or to carry on with our music
store example, how much I like the collection), and by available time. Nonetheless,
I expect the number of queries per thread would be at most 10, since if the
retrieved results are interesting, the users would likely perform more local
browsing; if not, they would mostly likely terminate the query.
Dataset
The MP3 database created by Eric Brochu taken from www.allmusic.com, and is
currently on the BETA web server. It consists of 8556 mp3 files extracted from
714 albums by 315 different artists. The main genres represented in the database
are rock/pop and electronica. The music are also labelled with English terms
(see Appendix A of Brochu's master thesis). Information about the music is stored
in ASCII files. Here is one sample:
ALB Fever to Tell
ART Yeah Yeah Yeahs
REL Apr 29, 2003
GEN Rock
STY Indie Rock, Garage Punk
TON Cathartic, Exuberant, Boisterous, Passionate, Brittle
PAT /cs/beta/SCRATCH/music/mp3library/Yeah Yeah Yeahs/Fever to Tell
where
ALB is the album,
ART is the artist,
REL is the release date,
GEN is the genre,
STY is the style,
TON is the tone and
PAT is the path on the server computer.
For the project, ART, GEN, STY and TON will be treated as potential query terms.
Further clustering of retrieved results will be based on ART, STY, and GEN (see
"Scenario of use" for more details).
[For some reason, the Title of the song is missing. I am consulting
with Eric about these details, and he will unlikely reply by the deadline of
this proposal. Basically, I should have access to these ASCII files. I am also
under the impression that the same files can be obtained from allmusic.com (or
allclassical.com for this Classical geek)]
Proposed infovis solution
Based on the aboved discussion, the proposed solution should support,
(1) Browsing within the retrieved results in the context of query terms so
as to direct users to the specific area of interest;
(2) Guided navigation in retrieved results based on query terms;
(3) Refinement of query based on retrieved results;
To achieve these goals, the proposed visualization provides spatial maps of
retrieved results clustered by the query terms in the style of Venn diagrams.
This allows users to browse within each section in the context of the query
terms (similar to signs inside the stores). Understanding the structure of the
retrieved results is not the main goal for displaying them in a Venn diagram.
It is chosen to display retreived results for two reasons. First, similar results
are clustered together in all possible combinations. Results within each region
is therefore as "homogeneous" as possible. Second, since neighours
of subregions are all related to the subregions, going from one subregion to
another does not involve an "abrupt" change of information attribute.
In short, continuous navigation based on the Venn diagram will be "smooth"
conceptually.
To explicity support query refinement based on retrieved results, attributes
(or keywords) of each retrieved result that are not used in the current query
should be shown, and be potentailly used as new query terms. To continue with
the music store example, this is analogous to seeing a Jazzified version of
Bach, and wishing to explore the Jazz section of the store. Each new query will
create another map based on the new query term and the old associated terms.
Creating a new map not only explicitly depicts the departure from the old query
(e.g., leaving the Classical section), but allow allow for better orientation
in the visualization, since once created, the topology of the query maps does
not change. These queries can be linked together by their common search times,
both to provide context of the the new query, and to a trail of evolution of
these queries.
More details of the initial prototypes will be discussed with a scenario.
A scenario of use
It is the end of a very long day. The user wishes to listen to a piece of music
that can help him relax and ease into the evening. He thus inputs three search
terms into the system: "soothing", "peaceful" and "meditative".
The system displays the search results as follows:
|
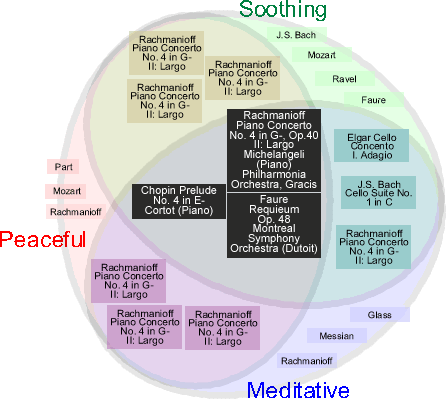
NOTE: The results retrieved should be unique--I just didn't have time
to find enough CDs to fill up the space at this stage :-(
|
Figure 1. Initial map: Design 1
Retrieved results are visually clustered based on the three search criteria
in the format of a Venn diagram.
Colour coding: Each main cluster of the Venn diagram is encoded
by a primary colour (red, green and blue), and the subregions (e.g. union
of "Soothing" and "Meditative") as the perceived addition
of the two colour (e.g. with "Soothing" being green and "Meditative"
being blue, the region indicating their union is aqua). The selection
of primary colour is due to their distinctiveness.
Perceptual layering: In order to emphasize the degree of relevance
of the search results, and reduce visual cluttering, the technqiue of
perceptual layering is used to create the illusion of layers. In the case
of three search criteria, three layers are created:
(1) Top most: Where the three criteria intersect, and is the most important
area
(2) Middle: Where two of the criteria intersect
(3) Lower most: No intersection
Semantic Zooming: Information related to the piece of music (the
title, the composer and the performers in the case of classical music)
are displayed for each search result. The degree of detail displayed depends
if the node is in focus or not. In the initial map, the most relevant
area (i.e. where the three search criteria intersect) is the focus by
default, and results belonging to this area is displayed in full detail.
The next level of zooming only shows the composer and the title of the
piece (i.e. the next most important pieces of information for classical
music), and the at the lowest zoom level, only the composer is displayed.
The lowest level is to display only the number of results in the subregion
(see Figure 4 below, the "Soothing"+"J.S.Bach" subregion).
Focus+Context: This technqiue is used to allow the user to explore
details of the retrieved results that are not shown at the highest zoom
level. As mentioned, there are four levels of zoom, and selection of a
subregion of the Venn diagram will increase the level to the highest.
Neigbouring subregion will decrement their zoom level (and the required
area) to accommodate for the larger requirement of space caused by the
change. The change in zoom levels will be animated (aside: since we
do not know otherwise. It is "safer" to follow convention wisdom
for now). For example, selection of the cluster "Soothing"+"Meditative"
increases the zoom-level of its elements, and to accomodate this change,
its immediate neighbour "Soothing"+"Meditative"+"Peaceful"
decreases its zoom-level to "release" enough display space.
In this case, only one other subregion is involved to recapture enough
space. Otherwise, more subregions will be involved. In cases where all
subregions are at the minimal zoom-level, and there still isn't enough
space to display all the results in that region in full, then only some
of the results can be enlarged, and the priority will be given to nodes
closer to the centre of the cluster (i.e. a quasi fisheye within the cluster).
|
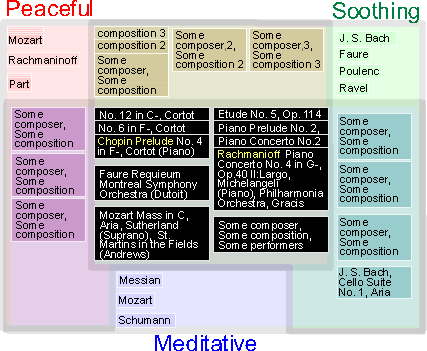 |
Figure 2. Initial map: Design 2
The above design has the weakness of scalability: it is already encountering
some problems when displaying 3-5 pieces of music in each subregion. This
is partly because the design does not take into account the nature of
music files that may help cluster the data within each subregion:
(1) Many compositions share the same composer. In the case of Classical
music, there are a few popular and/or productive composers. Also, users
may have a preference for certain composers. Such personal collections
may contain many pieces of compositions, but only by a handful of composers.
Similar argument may be applicable to other genre of music, where it
is possible to aggregate the artist(s).
(2) Many compositions are inherently grouped. For classical music,
it is possible to "divide" a piece of work into sub-pieces
(i.e. movements, e.g., the 2nd movement of Beethoven's 5th symphony),
and many works are part of a collection (e.g., the 48 preludes and fugues
by J. S. Bach). These collections are typically similar in nature, and
more than one of the pieces from a single collection is likely to be
retrieved given a set of criteria. Similar ideas may be applied to "albums"
of other genre of music.
(3) A further grouping of music is by genre, like Indie
Rock and Garage Punk.
Given these characteristics of music, it is therefore possible to further
cluster retrieved results within each subregion. In Figure 2, in the focused
area, 3 of the 24 preludes by Chopin are retrieved, and can be "piled"
up to conserve screen space. At a higher level of clustering, pieces by
the same composer can be grouped (e.g., the three pieces by Rachmaninoff).
The common words are highlighted to indicate the theme of the collection
(e.g., "Chopin Prelude" and "Rachmaninoff"). Similar
technique can be used even when there is only enough space to display
the name of the composer (e.g., the piles of compositions by Mozart in
the "Peaceful" subregion). As in the physical world, the height
of the pile indicates the number of results in that cluster.
Another problem with design 1 is the display space usage. Since text
is rectangular, displaying text in non-rectangular containers is wasteful
in terms of space usage. In this case, since the texts are further contained
in boxes, using non-rectangular designs leads to more unusable space.
In view of this difficulty, design 2 modified the circular Venn digram
into a rectangular shape. As a result, the main regions are no longer
simple shapes (e.g., circle or squares). Admittedly, this makes it more
difficult to understand the structure of the digram (e.g., where is the
boundary of the "Meditative" cluster?). However, as mentioned
before, since conveying the structure is not the main aim of the map,
the benefits of using a rectangular display may be an adequate tradeoff.
(Due to the length of this proposal, the rest of the design sketches
use the rectangular form. I have drawn the corresponding circular models
as well.)
|
|
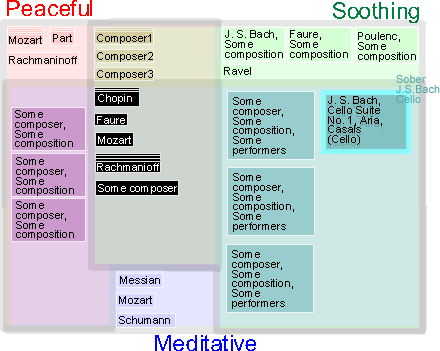
|
Figures 3. Selection of a piece
of music
User can select any pieces on the display by clicking on the description
to show additional keywords of the music that are not part of the query
map to which the music . These new keywords are then potential query terms
for a new query. For example, in this figure, the music with the label
"J.S. Bach Cello Suite No. 1 in C Casals (Cello)" is highlighted
with a perceptually salient border, and three other related keywords ("Sober",
"J.S. Bach" and "Cello") are displayed.
Double clicking the target will play the music.
|
|
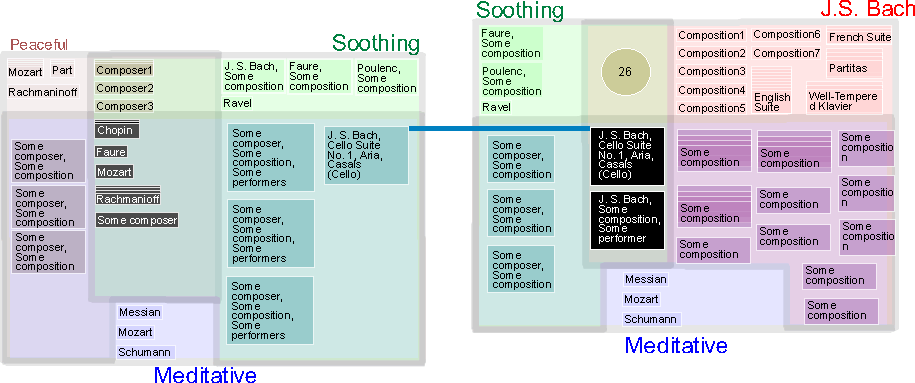
Figures 4. New query
After listening to J.S. Bach's Cello Suite No. 1, the user may wish to
continue the "Bach experience" by exploring other music by Bach,
but keeping with the general mood of the Cello Suite (i.e. soothing and
meditative). This requires adding a new keyword to the query. To allow
for fluid exploration, keywords of any displayed can be used to modify
the current query, and a new map will be created. Since the query basically
belong to the same thread as the original query (linked by a common piece
of music), this relationship is encoded by a direct path between the two
queries, with both ends of the path linked to the connecting piece of
music. In the new query, this connecting node becomes the starting node,
and is therefore placed at the focus of the new query map.
In this example, the user selected "J.S. Bach" as the new query
keyword in the context of "Soothing"+"Meditative. The "J.S.
Bach Cello Suite No. 1 in C Casal (Cello)" becomes the centre node
in the right cluster group, and is in focus. Since two of the terms in
the new cluster groups are from the original cluster group, they share
a number of nodes. However, based on the new criteria (i.e. "J.S.
Bach", instead of "Peaceful"), some of the nodes now belong
to different subregion in the new cluster group. To help the re-orientation,
ordering and positioning of the nodes are preserved when possible. Also,
to continue with the exploration metaphor, when the user continue with
the direction of travel, he should find more and more music satisfying
the new criteria, and less of the old. In this case, going towards the
"J.S. Bach" label will reveal more "J.S. Bach", and
less "Soothing"+"Meditative" results.
Animation: I am thinking to use animation to convey the transistion
in stages, to show:
(1) "growing" of the original piece of music into to a new
query map (the connecting node to the new focal region);
(2) "creation" of the new map with previous, common territories
(the common sub-regions)
(3) "addition" of the new part of the new map by linking the
newly selected query criteria, and its effect in the new map
Colour encoding with new queries : It is obvious that it will
not be possible to encode each search criteria with a distinctive colour.
In design 1, the three primary colours are reused. While such an encoding
scheme is appropriate for shared search criteria among the queries (e.g.,
"meditative" and "soothing"), it is disturbingly misleading
for different search criteria (e.g., "Peaceful" in query 1 and
"J.S.Bach" in query 2). To avoid this effect, old query search
criteria that are not resued will fade with each new additional query
to minimalize the unwanted colour grouping effect. Eventually, the all
the colour will fade away, leaving a grayscale display for old query criteria,
and a more saturated trail based on common terms.
Space allocation to queries: When the display runs out of viewable
space, there two choices: first, allow the space to expand and treat the
viewable space as a window to the entire display space (i.e. panning with
a hole), or second, reduce the size of the elements on the space to make
room. I propose to use the second approach for the prototype. When users
have "moved-onto" new queries, the old queries should be less
important, except for the reused query terms. Thus reducing the size of
these old query results not only to free up space, but also to help focus
user's attention to more relevant areas. This works in harmony with the
"fading colour" idea mentioned above.
|
Proposed implementation approach
The prototype will be implement using Java with the Eclipse IDE.
Milestones
|
Nov 5: Proposal due
|
---
|
|
|
Nov 5-Nov12
Famliarize with database structure, refine prototype design (circle or
square?)
|
|
Nov 17: Project Update 1
|
---
|
|
|
Nov 13-19
Implement basic layout (Figure 1 or 2), and displaying and launching of
selected individual element (Figure 3) |
|
Nov 22: Project Update 2
|
---
|
|
|
Nov 20-26
Implement semantic zooming, F+C with animation (going from Figure 1 to 3) |
|
|
---
|
|
|
Nov 27-Dec 3
Implement new keyword query (spatial layout) (Figure 4) |
|
|
---
|
|
|
Dec 4-10
Implement new keyword query (animation) (Figure 4) |
|
Dec 15: Final report and presentation
|
---
|
---
|
Dec 11-15
Preparation of report and presentation |
References
Ahlberg, Chris and Ben Shneiderman (1994). Visual information seeking: Tight
coupling of dynamic query filters with starfield displays , Proc SIGCHI '94,
pp. 313-317.
Berenci, E., Carpineto, C., Giannini, V., and Mizzaro, S. (1999). Effectiveness
of keyword-based display and selection of retrieval results for interactive
searches. Lecture Notes In Computer Science. Proceedings of the Third European
Conference on Research and Advanced Technology for Digital Libraries, pp. 106
- 125.
Chalmers, M. (1993). Using a landscape metaphor to represent a corpus of documents.
In Proc. of the EuroConference on Spatial Information Theory (COSIT '93, Elba,
Italy, Sept.).
Dumais, Susan, Edward Cutrell , JJ Cadiz , Gavin Jancke , Raman Sarin , Daniel
C. Robbins (2003), Stuff I've seen: a system for personal information retrieval
and re-use, Proceedings of the 26th annual international ACM SIGIR conference
on Research and development in informaion retrieval, July 28-August 01, 2003,
Toronto, Canada.
Fluit, C., Sabou, M., and van Harmelen, F. (2003). Supporting User Tasks through
Visualisation - Of Light-Weight Ontologies. S. Staab and R. Studer ed. Handbook
on Ontologies in Information Systems. Springer-Verlag.
Havre, Susan, Elizabeth Hetzler, Ken Perrine, Elizebeth Jurrus, Nancy Miller.
(2001) Interactive visualization of multiple query results. IEEE Infovis 2001,
pp. 105-112.
Hearst, Marti A. (1994). Using categories to provide context for full-text
retrieval results. In Proc. of the RIAO '94, Intelligent Multimedia Information
Retrieval Systems and Management, pp. 115-130.
Hertzum, M and Frøkjær, E. (1996). Browsing and querying in online
documentation: a study of user interfaces and the interaction process. ACM Transactions
on Computer-Human Interaction (TOCHI) 3(2), 131-161.
Jones, Steve (1998). Graphical query specification and dynamic result previews
for a digital library. UIST' 98, 143-151.
Kienreich, W., Sabal, V, Granitzer, M., Kappe, F., Andrews, K. (2002) InfoSky:
A system for visual exploration of very large, hierarchically structured knowledge
space.
Leuski, Anton and James Allan (2000). Lighthouse: Showing the way to relevant
information, IEEE Infovis 2000, 125-129.
Ravasio, P., Vukelja, L., Rivera, G., and Norrie, M. C. (2003). Project infospace:
From information managing to information representation. In Interact 2003---Ninth
IFIP TC13 International Conference on Human-Computer Interaction, M. Rauterberg,
M. Menozzi, and J. Wesson, Eds. Zurich, Switzerland.
Ringel, M., Cutrell, E., Dumais, S., Horvitz, E. (2003). Milestones in time:
the value of landmarks in retrieving information from personal stores. Proceedings
of Interact 2003, p. 184-191.
Uphill, Trystan (2000). Consistency, clarity and control: development of a
new approach to WWW image retrieval. Bachelor of Information Technology Thesis
at Australian National University.