| A Pseudo-Natural Example |
In this section we produce evidence that there exists networks for which CVE is better than VE. The sole purpose of this experiment it to demonstrate that there potentially are problems where it is worthwhile using CVE. We use an instance of the water network [17] from the Bayesian network repository8 where we approximated the conditional probabilities to create contextual independencies. Full details of how the examples were constructed are in Appendix *. We collapsed probabilities that were within 0.05 of each other to create confactors. The water network has 32 variables and the tabular representation has a table size of 11018 (after removing variables from tables that made a difference of less that 0.05). The contextual belief network representation we constructed had 41 confactors and a total table size of 5834.
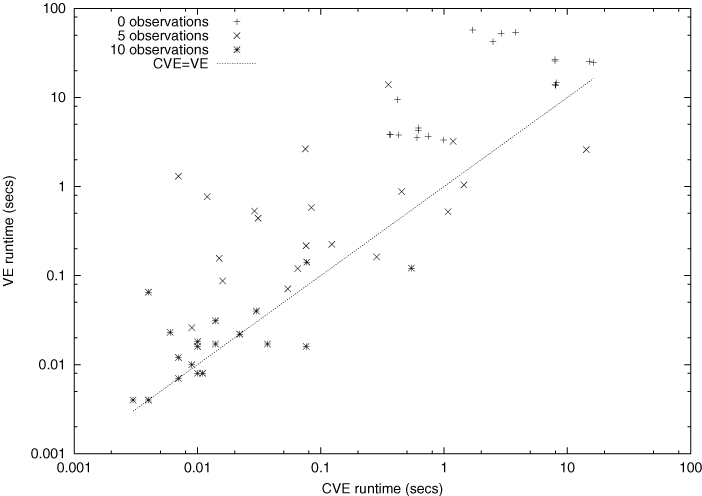
Figure * shows a scatter plot of 60 runs of random queries9. There were 20 runs each for 0, 5 and 10 observed variables. The raw data is presented in Appendix *. The first thing to notice is that, as the number of observations increases, inference becomes much faster. CVE was often significantly faster than VE. There are a few cases where CVE was much worse than VE; essentially, given the elimination ordering, the context-specific independence didn't save us anything in these example, but we had to pay the overhead of having variables in the context.
| A Pseudo-Natural Example |