We have now established that VE1 is the most efficient VE -based algorithm for exploiting causal independencies. In this section we investigate how effective VE1 is.
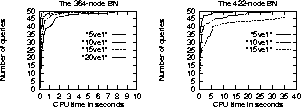
Figure 7: Time statistics for VE1 .
Experiments have been carried out in both of the two CPCS networks to answer this question. In the 364-node network, four types of queries with one query variable and five, ten, fifteen, or twenty observations respectively were considered. Fifty queries were randomly generated for each query type. The statistics of the times VE1 took to answer those queries are given by the left chart in Figure 7. When collecting the statistics, a ten MB memory limit and a ten second CPU time limit were imposed to guide against excessive resource demands. We see that all fifty five-observation queries in the network were each answered in less than half a second. Forty eight ten-observation queries, forty five fifteen-observation queries, and forty twenty-observation queries were answered in one second. There is, however, one twenty-observation query that VE1 was not able to answer within the time and memory limits.
In the 364-node network, three types of queries with one query variable and five, ten, or fifteen, observations respectively were considered. Fifty queries were randomly generated for each query type. Unlike in the previous section, no approximations were made. A twenty MB memory limit and a forty-second CPU time limit were imposed. The time statistics is shown in the right hand side chart. We see that VE1 was able to answer all most all queries and a majority of the queries were answered in little time. There are, however, three fifteen-observation queries that VE1 was not able to answer.