The optimal decision tree is the one with more_info=true. It makes 5 errors. [It gets examples e2, e4, e5, e8 and e9 wrong.].
There is one non-leaf node, labelled with first. The tree is:
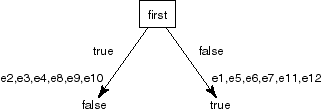
This has error of 3 (it misclassifies examples e3, e10 and e5).
There are many possible answers to this problem depending on how the arbitrary choices are resolved. All solutions have first at the root.
One solution is:

This tree can be written as:
if(first,
if(edu,
if(bought,true,false),
if(visited,true,false)),
if(edu,
true,
if(bought,
true,
if(visited,false,true))))
There are 4 instances that don't appear in the examples above:
The bias is that when first is true, visited is irrelevant when edu is true and bought is irrelevant when edu is false. When first is false, more_info is always false except for the example corresponding to e5.
bought edu first visited more_info true true true true true true true false false true true false true true true false true false true true
There are two different thing that you could notice from this dataset, in particular from noticing that there is only one example that is false when first is false. This single example results in a complex tree for first=false.
The first is that on which attribute to split on is for first=false is completely arbitrary. Depending on the arbitrary choice, the instance:
will be classified differently. We can (over)fit the data to models where this instance is true and to models where this instance is false.
bought edu first visited false true false true
The second that this example e5 could be noisy. It may be a better model to say that the user asks for more_info when first=false, but that there is one noisy example rather than there being a complex theory about the world.