Place and scene recognition from video
While navigating in an
environment, a vision system has to be able to recognize where
it is and what the main objects in the scene are. We present a
context-based vision system for place and object
recognition. The goal is to identify familiar locations (e.g.,
office 610, conference room 941, Main Street), to categorize new
environments (office, corridor, street) and to use that
information to provide contextual priors for object recognition
(e.g., table, chair, car, computer). We have trained a system to
recognize over 60 locations (indoors and outdoors) and to
suggest the presence and locations of more than 20 different
object types. The algorithm has been integrated into a mobile
system that provides real-time feedback to the user.
As a test-bed for the approach
proposed, we use a helmet-mounted mobile system. The system is
composed of a web-cam that is set to
capture 4 images/second at a resolution of 120x160 pixels
(color). The web-cam is mounted on a
helmet in order to follow the head movements while the user
explores their environment. The user receives feedback
about system performance through a head-mounted
display.


Kevin Murphy
Antonio Torralba
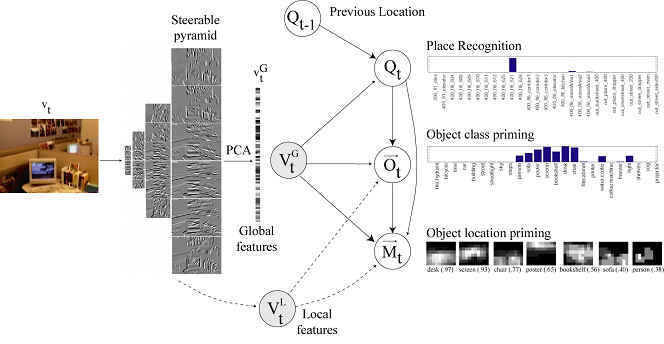
We use a low-dimensional global image representation that
captures the "gist" of the scene.
This can be used as input to a Bayes net/ HMM, as shown below.
(See our ICCV03 paper for details.)
Below we show the performance of place
recognition for a sequence that
starts indoors and then goes outdoors.
(ICCV03 Figure 3).
Top. The solid line represents
the true location, and the dots represent the posterior probability associated with each
location. There are 63
possible locations, but we only show those with non
negligible probability
mass. Middle. Estimated category of each location. Bottom. Estimated
probability of being indoors or outdoors.

Some images from the dataset.

Publications
Movies
- AVI of place recognition
using wearable camera.
If P(place-category(t)|vG(1:t)) > threshold, we print the category of
the place (office, kitchen, etc) in the top right corner
(black = correct, red = incorrect).
If P(place(t)|vG(1:t)) > threshold, we print the name of the specific
place (office 101, kitchen #3, etc) in the bottom right corner
(black = correct, red = incorrect).
- AVI of place recognition
using wearable camera. This one shows the HMM belief state
superimposed on a topological map.
Text output is the same as above movie.
The bottom half shows a map of the 9th floor of the AI lab (NE43).
Blue solid circle indicates P(place(t)|vG(1:t)) as computed using the HMM;
black hollow circle indicates P(place(t)|vG(t)) as computed using the
instantaneous gist;
red/green cross = true location.
The size of the circles is proportional to the probability.
Notice how the HMM provides temporal smoothing.
Nevertheless, there are discontinuous jumps, which apparently violate
topological constraints, because we apply Dirichlet smoothing to the
transition matrix. This effect can be reduced (at the cost of
increased latency upon moving to a new location) by down-weighting the
likelihood by an exponential factor (see equation for \tilde{b}_t on
p4 of ICCV paper).
- WMV movie which shows how Dan Roth
ported our place recognition system to an
ER1 mobile robot.
Data
- The video data used to generate the results in Figure 3 of the
ICCV03 paper is available
as part of the
MIT CSAIL
database of object and scenes.
Look for the folder called "paperSequence".
- The matlab file here contains the
80 dimensional gist vectors for the video sequence, and the place
numbers and names:
placeNames: {1x20 cell}
placeNums: [1x3430 double]
gists: [80x3430 double]
If you type
plot(foo.placeNums,'o-')
the results look slightly different from Figure 3, since the names of
the places were changed somewhat. But it is qualitatively similar.
Note that although we considered 63 places in the ICCV03 paper, only
20 occur in this particular sequence.
- The file gistsICCV03.zip (14MB) contains
17 files, similar to the above, for the 17 video sequences used
in the ICCV03 paper (see here for the list of files used for
training and testing).