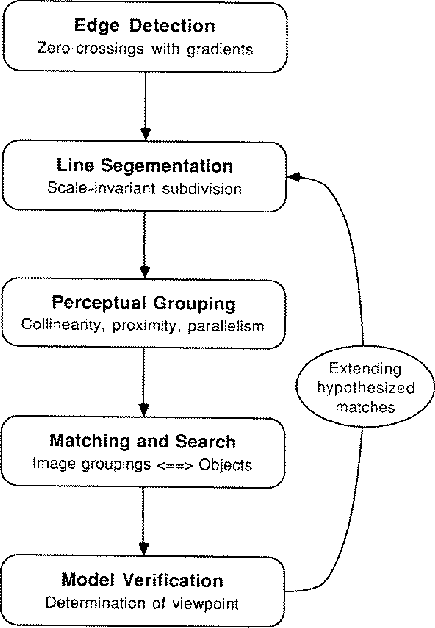
Figure 8: The components of the SCERPO vision system and the sequence of
computation.
The methods of spatial correspondence and perceptual organization described above have been combined to produce a functioning system for recognizing known three-dimensional objects in single gray-scale images. In order to produce a complete system, other components must also be included to perform low-level edge detection, object modeling, matching, and control functions. Figure 8 illustrates the various components and the sequence of information flow. Figures 9 to 16 show an example of the different stages of processing for an image of a randomly jumbled bin of disposable razors. Recognition was performed without any assumptions regarding orientation, position or scale of the objects; however, the focal length of the camera was specified in advance.

Figure 9: The original image of a bin of disposable razors, taken at a
resolution of 512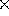 512 pixels.
512 pixels.
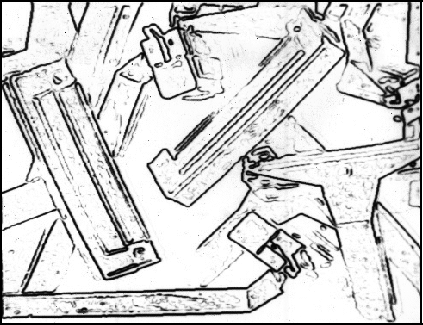
Figure 10: The zero-crossings of a
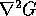 convolution. Grey levels are
proportional to gradient magnitude at the zero-crossing.
convolution. Grey levels are
proportional to gradient magnitude at the zero-crossing.

Figure 11: Straight line segments derived from the zero-crossing data of Figure
10 by a scale-independent segmentation algorithm.
In order to provide the initial image features for input to the perceptual
grouping process, the first few levels of image analysis in SCERPO use
established methods of edge detection. The 512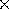 512 pixel image shown
in Figure 9 was digitized from the output of an inexpensive vidicon
television camera. This image was convolved with a Laplacian of Gaussian
function (
512 pixel image shown
in Figure 9 was digitized from the output of an inexpensive vidicon
television camera. This image was convolved with a Laplacian of Gaussian
function (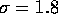 pixels) as suggested by the Marr-Hildreth
[23] theory of edge detection. Edges in the image should give rise to
zero-crossings in this convolution, but where the intensity gradient is low
there will also be many other zero-crossings that do not correspond to
significant intensity changes in the image. Therefore, the Sobel gradient
operator was used to measure the gradient of the image following the
pixels) as suggested by the Marr-Hildreth
[23] theory of edge detection. Edges in the image should give rise to
zero-crossings in this convolution, but where the intensity gradient is low
there will also be many other zero-crossings that do not correspond to
significant intensity changes in the image. Therefore, the Sobel gradient
operator was used to measure the gradient of the image following the 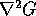 convolution, and this gradient value was retained for each point along
a zero-crossing as an estimate of the signal-to-noise ratio. Figure
10 shows the resulting zero-crossings in which the brightness of each
point along the zero-crossings is proportional to the magnitude of the
gradient at that point.
convolution, and this gradient value was retained for each point along
a zero-crossing as an estimate of the signal-to-noise ratio. Figure
10 shows the resulting zero-crossings in which the brightness of each
point along the zero-crossings is proportional to the magnitude of the
gradient at that point.
These initial steps of processing were performed on a VICOM image processor
under the Vsh software facility developed by Robert Hummel and
Dayton Clark [7]. The VICOM can perform a 3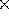 3 convolution
against the entire image in a single video frame time. The Vsh
software facility allowed the 18
3 convolution
against the entire image in a single video frame time. The Vsh
software facility allowed the 18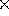 18 convolution kernel required for
our purposes to be automatically decomposed into 36 of the 3
18 convolution kernel required for
our purposes to be automatically decomposed into 36 of the 3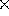 3
primitive convolutions along with the appropriate image translations and
additions. More efficient implementations which apply a smaller Laplacian
convolution kernel to the image followed by iterated Gaussian blur were
rejected due to their numerical imprecision. The VICOM is used only for the
steps leading up to Figure 10 , after which the zero-crossing image is
transferred to a VAX 11/785 running UNIX 4.3 for subsequent processing. A
program written in C reads the zero-crossing image and produces a file of
linked edge points along with the gradient magnitude at each point. All
other components are written in Franz Lisp.
3
primitive convolutions along with the appropriate image translations and
additions. More efficient implementations which apply a smaller Laplacian
convolution kernel to the image followed by iterated Gaussian blur were
rejected due to their numerical imprecision. The VICOM is used only for the
steps leading up to Figure 10 , after which the zero-crossing image is
transferred to a VAX 11/785 running UNIX 4.3 for subsequent processing. A
program written in C reads the zero-crossing image and produces a file of
linked edge points along with the gradient magnitude at each point. All
other components are written in Franz Lisp.
The next step of processing is to break the linked lists of zero-crossings into perceptually significant straight line segments, using the algorithm described in the previous section. Segments are retained only if the average gradient magnitude along their length is above a given threshold. It is much better to apply this threshold following segmentation than to the original zero-crossing image, since it prevents a long edge from being broken into shorter segments when small portions dip below the gradient threshold. The results of performing these operations are shown in Figure 11 . The recognition problem now consists of searching among this set of about 300 straight line segments for subsets that are each spatially consistent with model edges projected from a single viewpoint.
The straight line segments are indexed according to endpoint locations and orientation. Then a sequence of procedures is executed to detect significant instances of collinearity, endpoint proximity (connectivity), and parallelism. Each instance of these relations is assigned a level of significance using the formulas given above in the section on perceptual organization. Pointers are maintained from each image segment to each of the other segments with which it forms a significant grouping. These primitive relations could be matched directly against corresponding structures on the three-dimensional object models, but the search space for this matching would be large due to the substantial remaining level of ambiguity. The size of the search space can be reduced by first combining the primitive relations into larger, more complex structures.

Figure 12: The most highly-ranked perceptual groupings detected from among
the set of line segments. There is some overlap between groupings.
The larger structures are found by searching among the graph of primitive relations for specific combinations of relations which share some of the same line segments. For example, trapezoid shapes are detected by examining each pair of parallel segments for proximity relations to other segments which have both endpoints in close proximity to the endpoints of the two parallel segments. Parallel segments are also examined to detect other segments with proximity relations to their endpoints which were themselves parallel. Another higher-level grouping is formed by checking pairs of proximity relations that are close to one another to see whether the four segments satisfy Kanade's [16] skewed symmetry relation (i.e., whether the segments could be the projection of segments that are bilaterally symmetric in three-space). Since each of these compound structures is built from primitive relations that are themselves viewpoint-invariant, the larger groupings also reflect properties of a three-dimensional object that are invariant over a wide range of viewpoints. The significance value for each of the larger structures is calculated by simply multiplying together the probabilities of non-accidentalness for each component. These values are used to rank all of the groupings in order of decreasing significance, so that the search can begin with those groupings that are most perceptually significant and are least likely to have arisen through some accident. Figure 12 shows a number of the most highly-ranked groupings that were detected among the segments of Figure 11 . Each of the higher-level groupings in this figure contains four line segments, but there is some overlap in which a single line segment participates in more than one of the high-level groupings.
Even after this higher-level grouping process, the SCERPO system clearly makes use of simpler groupings than would be needed by a system that contained large numbers of object models. When only a few models are being considered for matching, it is possible to use simple groupings because even with the resulting ambiguity there are only a relatively small number of potential matches to examine. However, with large numbers of object models, it would be necessary to find more complex viewpoint-invariant structures that could be used to index into the database of models. The best approach would be to make use of some form of evidential reasoning to combine probabilistic information from multiple sources to limit the size of the search space. This approach has been outlined by the author in earlier work [19, Chap. 6,].
The matching process consists of individually comparing each of the perceptual groupings in the image against each of the structures of the object model which is likely to give rise to that form of grouping. For each of these matches, the verification procedure is executed to solve for viewpoint, extend the match, and return an answer as to whether the original match was correct. Given the large number of potential matches and their varied potential for success, it is important to make use of a ranking method to select the most promising matches first. For example, every straight line detected in the image is a form of grouping that could be matched against every straight edge of the model, but this would involve a large amount of search. In general, the more complex a grouping is the fewer potential matches it will have against the model. Therefore, the only matches that are considered in the current implementation are those that involve image groupings that contain at least 3 line segments. This also has the important result that such a grouping will generally contain enough information to solve exactly for viewpoint from the initial match, which provides tight constraints to speed up the operation of the verification procedure.
A more precise specification of the optimal ordering for the search process
could be stated as follows. In order to minimize the search time, we would
like to order our consideration of hypotheses according to decreasing values
of 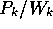 , where
, where 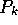 is the probability that a particular hypothesis
for the presence of object k is correct, and
is the probability that a particular hypothesis
for the presence of object k is correct, and 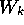 is the amount of work
required to verify or refute it. In general, increased complexity of a
grouping will lead to fewer potential matches against different object
features, and therefore will increase the probability
is the amount of work
required to verify or refute it. In general, increased complexity of a
grouping will lead to fewer potential matches against different object
features, and therefore will increase the probability 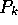 that any
particular match is correct. However, this probability is also very
dependent upon the particular set of objects that are being considered,
since some features will function more effectively to discriminate among one
particular set of objects than in another set. The most effective way to
determine the optimal values of
that any
particular match is correct. However, this probability is also very
dependent upon the particular set of objects that are being considered,
since some features will function more effectively to discriminate among one
particular set of objects than in another set. The most effective way to
determine the optimal values of 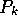 for each potential match would be
through the use of a learning procedure in which the actual probability
values are refined through experience in performing the recognition task.
These probability adjustments would in essence be strengthening or weakening
associations between particular image features and particular objects.
These object-specific values would be multiplied by the probability that a
grouping is non-accidental to determine the final estimate of
for each potential match would be
through the use of a learning procedure in which the actual probability
values are refined through experience in performing the recognition task.
These probability adjustments would in essence be strengthening or weakening
associations between particular image features and particular objects.
These object-specific values would be multiplied by the probability that a
grouping is non-accidental to determine the final estimate of 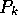 . The
. The
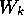 could be similarly learned through experience. The current
implementation of SCERPO simply uses the complexity of a grouping as a crude
estimate for these desired ranking parameters.
could be similarly learned through experience. The current
implementation of SCERPO simply uses the complexity of a grouping as a crude
estimate for these desired ranking parameters.
In order to speed the runtime performance of the matching process, the viewpoint-invariant groupings that each model can produce in the image are precomputed off-line. The model is simply checked for three-dimensional instances of the three primitive image relations that are detected during the perceptual grouping process: i.e., connectivity, collinearity, and parallelism. No attempt is made to find approximate instances of these relations, so in essence the relations are implicitly specified by the user during model input. These relations are then grouped into the same types of larger structures that are created during the perceptual grouping process, and are stored in separate lists according to the type of the grouping. Any rotational symmetries or other ambiguities are used to create new elements in the lists of possible matches. The runtime matching process therefore consists only of matching each image grouping against each element of a precomputed list of model groupings of the same type.
One important feature of this matching process is that it is opportunistic in its ability to find and use the most useful groupings in any particular image. Given that there is no prior knowledge of specific occlusions, viewpoint, amount of noise, or failures in the detection process, it is important to use a run-time ranking process that selects among the actual groupings that are found in any particular image in order to make use of those that are most likely to be non-accidental. Since each view of an object is likely to give rise to many characteristic perceptual groupings in an image, it is usually possible to find features to initiate the search process even when a substantial portion of the object is occluded. The current implementation of SCERPO is at a rather simple level in terms of the sophistication of perceptual grouping and matching, and as should be clear from the above discussion there are many opportunities for making these processes faster and more complete. As more types of groupings and other viewpoint-invariant features are added, the number of possible matches would increase, but the expected amount of search required for a successful match would decrease due to the increased specificity of the matches with the highest rankings.
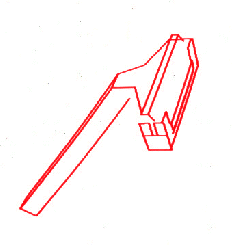
Figure 13: The three-dimensional wire-frame model of the razor shown from a
single viewpoint.
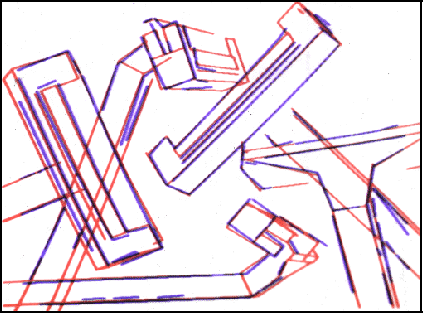
Figure 14: Successful matches between sets of image segments and particular
viewpoints of the model.
The implementation of the viewpoint-solving and verification process has already been described in detail in an earlier section. This is the most robust and reliable component of the system, and its high level of performance in extending and verifying a match can compensate for many weaknesses at the earlier stages. The low probability of false positives in this component means that failure at the earlier levels tends to result simply in an increased search space rather than incorrect matches. Figure 13 shows the three-dimensional model that was used for matching against the image data. Figure 14 shows the final set of successful matches between particular viewpoints of this model and sets of image segments. Once a particular instance of an object has been identified, the matched image segments are marked to indicate that they may no longer participate in any further matches. Any groupings which contain one of these marked segments are ignored during the continuation of the matching process. Therefore, as instances of the object are recognized, the search space can actually decrease for recognition of the remaining objects in the image.
Since the final viewpoint estimate is performed by a least-squares fit to greatly over-constrained data, its accuracy can be quite high. Figure 15 shows the set of successfully matched image segments superimposed upon the original image. Figure 16 shows the model projected from the final calculated viewpoints, also shown superimposed upon the original image. The model edges in this image are drawn with solid lines where there is a matching image segment and with dotted lines over intervals where no corresponding image segment could be found. The accuracy of the final viewpoint estimates could be improved by returning to the original zero-crossing data or even the original image for accurate measurement of particular edge locations. However, the existing accuracy should be more than adequate for typical tasks involving mechanical manipulation.
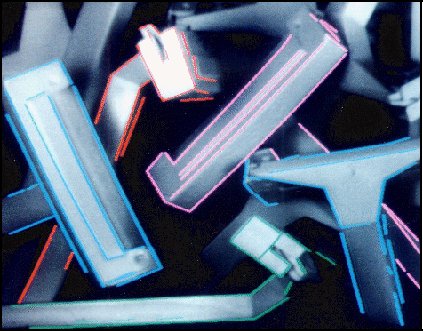
Figure 15: Successfully matched image segments superimposed upon the
original image.
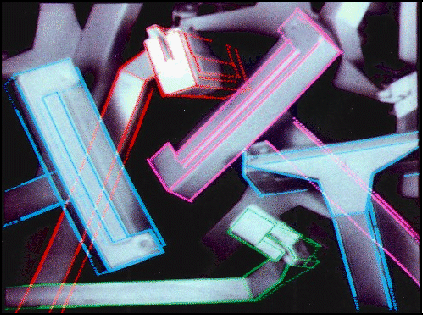
Figure 16: The model projected onto the image
from the final calculated viewpoints. Model edges are shown dotted where
there was no match to a corresponding image segment.
The current implementation of SCERPO is designed as a research and demonstration project, and much further work would be required to develop the speed and generality needed for many applications. Relatively little effort has been devoted to minimizing computation time. The image processing components require only a few seconds of computation on the VICOM image processor, but then the image must be transferred to a VAX 11/785 running UNIX 4.3 for further processing. It requires about 20 seconds for a program written in C to read the zero-crossing image and output a file of linked edge points. This file is read by a Franz Lisp routine, and all subsequent processing is performed within the Franz Lisp virtual memory environment. Segmentation into straight lines requires 25 seconds, indexing and grouping operations require about 90 seconds and the later stages of matching and verification took 65 seconds for this example. There are numerous ways in which the code could be improved to reduce the required amount of computation time if this were a major goal. Careful design of data structures would allow fast access of image segments according to predicted positions, lengths, and orientations. Each iteration of the crucial viewpoint-solving process requires at most several hundred floating point operations, so there is reason to believe that a carefully coded version of the basic search loop could run at high rates of speed.