The methods for achieving spatial correspondence presented in the previous section enforce the powerful constraint that all parts of an object's projection must be consistent with a single viewpoint. This constraint allows us to bootstrap just a few initial matches into a complete set of quantitative relationships between model features and their image counterparts, and therefore results in a reliable decision as to the correctness of the original match. The problem of recognition has therefore been reduced to that of providing tentative matches between a few image features and an object model. The relative efficiency of the viewpoint solution means that only a small percentage of the proposed matches need to be correct for acceptable system performance. In fact, when matching to a single, rigid object, one could imagine simply taking all triplets of nearby line segments in the image and matching them to a few sets of nearby segments on the model. However, this would clearly result in unacceptable amounts of search as the number of possible objects increases, and when we consider the capabilities of human vision for making use of a vast database of visual knowledge it is obvious that simple search is not the answer. This initial stage of matching must be based upon the detection of structures in the image that can be formed bottom-up in the absence of domain knowledge, yet must be of sufficient specificity to serve as indexing terms into a database of objects.
Given that we often have no prior knowledge of viewpoint for the objects in our database, the indexing features that are detected in the image must reflect properties of the objects that are at least partially invariant with respect to viewpoint. This means that it is useless to look for features at particular sizes or angles or other properties that are highly dependent upon viewpoint. A second constraint on these indexing features is that there must be some way to distinguish the relevant features from the dense background of other image features which could potentially give rise to false instances of the structure. Through an accident of viewpoint or position, three-dimensional elements that are unrelated in the scene may give rise to seemingly significant structures in the image. Therefore, an important function of this early stage of visual grouping is to distinguish as accurately as possible between these accidental and significant structures. We can summarize the conditions that must be satisfied by perceptual grouping operations as follows:
The viewpoint invariance condition: Perceptual features must remain stable over a wide range of viewpoints of some corresponding three-dimensional structure.
The detection condition: Perceptual features must be sufficiently constrained so that accidental instances are unlikely to arise.
Although little-studied by the computational vision community, the perceptual organization capabilities of human vision seem to exhibit exactly these properties of detecting viewpoint invariant structures and calculating varying degrees of significance for individual instances. These groupings are formed spontaneously and can be detected immediately from among large numbers of individual elements. For example, people will immediately detect certain instances of clustering, connectivity, collinearity, parallelism, and repetitive textures when shown a large set of otherwise randomly distributed image elements (see Figure 5). This grouping capability of human vision was studied by the early Gestalt psychologists [29] and is also related to research in texture description [21,32]. Unfortunately, this important component of human vision has been missing from almost all computer vision systems, presumably because there has been no clear computational theory for the role of perceptual organization in the overall fuctioning of vision.

Figure 5: This figure illustrates the human
ability to spontaneously detect certain groupings from among an otherwise
random background of similar elements. This figure contains three
non-random groupings resulting from parallelism, collinearity, and endpoint
proximity (connectivity).
A basic goal underlying research on perceptual organization has been to discover some principle that could unify the various grouping phenomena of human vision. The Gestaltists thought that this underlying principle was some basic ability of the human mind to proceed from the whole to the part, but this lacked a computational or predictive formulation. Later research summarized many of the Gestaltists' results with the observation that people seem to perceive the simplest possible interpretation for any given data [14]. However, any definition of simplicity has depended entirely on the language that is used for description, and no single language has been found to encompass the range of grouping phenomena. Greater success has been achieved by basing the analysis of perceptual organization on a functional theory which assumes that the purpose of perceptual organization is to detect stable image groupings that reflect actual structure of the scene rather than accidental properties [30]. This parallels other areas of early vision in which a major goal is to identify image features that are stable under changes in imaging conditions.
Given these functional goals, the computational specification for perceptual organization is to differentiate groupings that arise from the structure of a scene from those that arise due to accidents of viewpoint or positioning. This does not lead to a single metric for evaluating the significance of every image grouping, since there are many factors that contribute to estimating the probability that a particular grouping could have arisen by accident. However, by combining these various factors and making use of estimates of prior probabilities for various classes of groupings, it is possible to derive a computational account for the various classes of grouping phenomena. An extensive discussion of these issues has been presented by the author in previous work [19], but here we will examine the more practical question of applying these methods to the development of a particular vision system. We will simplify the problem by looking only at groupings of straight line segments detected in an image and by considering only those groupings that are based upon the properties of proximity, parallelism, and collinearity.
A strong constraint on perceptual organization is provided by the viewpoint invariance condition, since there are only a relatively few types of two-dimensional image relations that are even partially invariant with respect to changes in viewpoint of a three-dimensional scene. For example, it would be pointless to look for lines that form a right angle in the image, since even if it is common to find lines at right angles in the three-dimensional scene they will project to right angles in the image only from highly restricted viewpoints. Therefore, even if an approximate right angle were detected in the image, there would be little basis to expect that it came from a right angle in the scene as opposed to lines at any other three-dimensional angle. Compare this to finding lines at a 180 degree angle to one another (i.e., that are collinear). Since collinear lines in the scene will project to collinear lines in the image from virtually all viewpoints, we can expect many instances of collinearity in the image to be due to collinearity in three dimensions. Likewise, proximity and parallelism are both preserved over wide ranges of viewpoint. It is true that parallel lines in the scene may converge in the image due to perspective, but many instances of parallelism occupy small visual angles so that the incidence of approximate parallelism in the image can be expected to be much higher than simply those instances that arise accidentally. In summary, the requirement of partial invariance with respect to changes in viewpoint greatly restricts the classes of image relations that can be used as a basis for perceptual organization.
If we were to detect a perfectly precise instance of, say, collinearity in the image, we could immediately infer that it arose from an instance of collinearity in the scene. That is because the chance of perfect collinearity arising due to an accident of viewpoint would be vanishingly small. However, real image measurements include many sources of uncertainty, so our estimate of significance must be based on the degree to which the ideal relation is achieved. The quantitative goal of perceptual organization is to calculate the probability that an image relation is due to actual structure in the scene. We can estimate this by calculating the probability of the relation arising to within the given degree of accuracy due to an accident of viewpoint or random positioning, and assuming that otherwise the relation is due to structure in the scene. This could be made more accurate by taking into account the prior probability of the relation occurring in the scene through the use of Bayesian statistics, but this prior probability is seldom known with any precision.
We will begin the analysis of perceptual organization by looking at the fundamental image relation of proximity. If two points are close together in the scene, then they will project to points that are close together in the image from all viewpoints. However, it is also possible that points that are widely separated in the scene will project to points arbitrarily close together in the image due to an accident of viewpoint. Therefore, as with all of the cases in which we attempt to judge the significance of perceptual groupings, we will consider a grouping to be significant only to the extent that it is unlikely to have arisen by accident.
An important example of the need to evaluate proximity is when attempting to form connectivity relations between line segments detected in an image. The proximity of the endpoints of two line segments may be due to the fact that they are connected or close together in the three-dimensional scene, or it may be due to a simple accident of viewpoint. We must calculate for each instance of proximity between two endpoints the probability that it could have arisen from unrelated lines through an accident of viewpoint. Since we often have no prior knowledge regarding the scene and since the viewpoint is typically unrelated to the structure of the three-dimensional objects, there is little basis for picking a biased background distribution of image features against which to judge significance. Therefore, this calculation will be based upon the assumption of a background of line segments that is uniformly distributed in the image with respect to orientation, position, and scale.
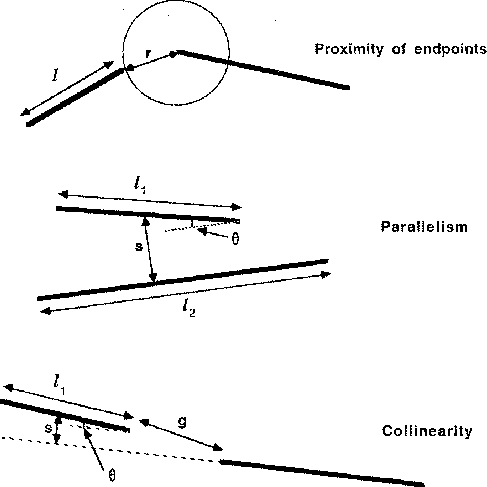
Figure 6: Measurements that are used to
calculate the probablity that instances of proximity, parallelism, or
collinearity could arise by accident from randomly distributed line
segments.
Given these assumptions, the expected number of endpoints, N, within a radius r of a given endpoint is equal to the average density of endpoints per unit area, d, multiplied by the area of a circle with radius r (see Figure 6):

For values of N much less than 1, the expected number is approximately equal to the probability of the relation arising accidentally. Therefore, significance varies inversely with N. It also follows that significance is inversely proportional to the square of the separation between the two endpoints.
However, the density of endpoints, d, is not independent of the length of the line segments that are being considered. Assuming that the image is uniform with respect to scale, changing the size of the image by some arbitrary scale factor should have no influence on our evaluation of the density of line segments of a given length. This scale independence requires that the density of lines of a given length vary inversely according to the square of their length, since halving the size of an image will decrease its area by a factor of 4 and decrease the lengths of each segment by a factor of 2. The same result can be achieved by simply measuring the proximity r between two endpoints as proportional to the length of the line segments which participate in the relation. If the two line segments are of different lengths, the higher expected density of the shorter segment will dominate that of the longer segment, so we will base the calculation on the minimum of the two lengths. The combination of these results leads to the following evaluation metric. Given a separation r between two endpoints belonging to line segments of minimum length l:

We are still left with a unitless constant, D, specifying the scale-independent density of line segments (the factor 2 accounts for the fact that there are 2 endpoints for each line segment). Since the measures of significance will be used mostly to rank groupings during the search process, the value chosen for a constant factor is of little importance because it will have no influence on the rankings. However, for our experiments we have somewhat arbitrarily assigned D the value 1. In fact, given a fairly dense set of segments with independent orientations and positions, and given the constraint that they do not cross one another, this scale independent measure will have a value close to 1.
This formula does a reasonable job of selecting instances of endpoint proximity that seem perceptually significant. Our concern with uniformity across changes in scale has had an important practical impact on the algorithm. It means that the algorithm will correctly pick out large-scale instances of connectivity between long segments, even if there are many short segments nearby which would otherwise mask the instance of endpoint proximity. This capability for detecting groupings at multiple scales is an important aspect of perceptual organization in human vision.
A similar measure can be used to decide whether an approximate instance of
parallelism between two lines in the image is likely to be non-accidental in
origin. Let  be the length of the shorter line and
be the length of the shorter line and 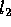 be the length
of the longer line. In order to measure the average separation s
between the two lines, we calculate the perpendicular distance from the
longer line to the midpoint of the shorter line. As in the case for
evaluating proximity, we assume that the density of line segments of length
greater than
be the length
of the longer line. In order to measure the average separation s
between the two lines, we calculate the perpendicular distance from the
longer line to the midpoint of the shorter line. As in the case for
evaluating proximity, we assume that the density of line segments of length
greater than  is
is  , for a scale-independent constant D.
Then, the expected number of lines within the given separation of the longer
line will be the area of a rectangle of length
, for a scale-independent constant D.
Then, the expected number of lines within the given separation of the longer
line will be the area of a rectangle of length 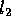 and width 2s
multiplied by the density of lines of length at least
and width 2s
multiplied by the density of lines of length at least  . Let
. Let  be the magnitude of the angular difference in radians between the
orientations of the two lines. Assuming a uniform distribution of
orientations, only
be the magnitude of the angular difference in radians between the
orientations of the two lines. Assuming a uniform distribution of
orientations, only  of a set of lines will be within
orientation
of a set of lines will be within
orientation 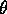 of a given line. Therefore, the expected number of
lines within the given separation and angular difference will be:
of a given line. Therefore, the expected number of
lines within the given separation and angular difference will be:

As in the previous case, we assign D the value 1 and assume that significance is inversely proportional to E.
Measuring the probability that an instance of collinearity has arisen by
accident shares many features in common with the case of parallelism. In
both cases, the ideal relation would involve two line segments with the same
orientation and with zero separation perpendicular to the shared
orientation. However, in the case of parallelism the line segments are
presumed to overlap in the direction parallel to their orientation, whereas
in collinearity the segments are expected to be separated along the
direction of their orientation with an intervening gap. Let g be the size
of this gap (the separation of the endpoints). As in the case of
parallelism, let s be the perpendicular distance from the midpoint of the
shorter line segment,  , to the extension of the longer line segment,
, to the extension of the longer line segment,
 . These bounds determine a rectangular region of length
. These bounds determine a rectangular region of length 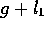 and
width 2s within which other lines would have the same degree of proximity.
Therefore, by analogy in other respects with the case of parallelism, we get
and
width 2s within which other lines would have the same degree of proximity.
Therefore, by analogy in other respects with the case of parallelism, we get
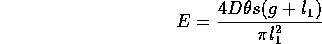
Notice that this measure is independent of the length of the longer line segment, which seems intuitively correct when dealing with collinearity.
The subsections above have presented methods for calculating the
significance of selected relationships between given pairs of straight line
segments. The most obvious way to use these to detect all significant
groupings in the image would be to test every pair of line segments and
retain only those pairs which have high levels of significance. However,
the complexity of this process would be 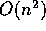 for n line segments,
which is too high for practical use in complex scenes.
for n line segments,
which is too high for practical use in complex scenes.
One method for limiting the complexity of this process is to realize that proximity is an important variable in all of the significance measures. Since significance decreases with the square of separation, two small segments that are widely separated in the image are unlikely to produce significant groupings regardless of their other characteristics (constraints on measurement accuracy limit the contribution that orientation or other measurements can make to judging significance). Therefore, complexity can be limited by searching only a relatively small region surrounding each segment for candidates for grouping. Since proximity is judged relative to the size of the component features, the size of the region that must be searched is proportional to the length of the line segment from which we are initiating the search. In order to make efficient use of these restrictions, all segments in the image should be indexed in a grid-like data structure according to the position of each endpoint. For further efficiency, the segments in each element of this position matrix can be further indexed according to orientation and length. The use of this index allows all groupings with interesting levels of significance to be detected in time that is essentially linear in the number of features. It is interesting to note that human vision also seems to limit the complexity of grouping in a similar way, although human vision apparently uses a more sophisticated method that also takes account of the local density of features [19].
The examples above have dealt with the grouping of line segments. However, the derivation of the line segments themselves is a very important segmentation problem that is based upon detecting significant instances of collinearity among edge points. Most common edge detection methods produce linked lists of points as their output (e.g., points which lie on the zero-crossing of an image convolved with a second-derivative operator). In order to carry out the higher forms of perceptual organization described above, these linked points must be grouped into line or curve descriptions that make explict the significiant curvilinear structures at all scales. The author has previously described a method for finding straight-line and constant-curvature segmentations at multiple scales and for measuring their significance [19, Chap. 4,]. However, here we will use a simplified method that selects only the single highest-significance line representation at each point along the curve.

Figure 7: This illustrates the steps of a scale-independent algorithm for
subdividing
a curve into its most perceptually significant straight line segments. The
input curve is shown in (a) and the final segmentation is given in (f).
The significance of a straight line fit to a list of points can be estimated by calculating the ratio of the length of the line segment divided by the maximum deviation of any point from the line (the maximum deviation is always assumed to be at least two pixels in size to account for limitations on measurement accuracy). This measure will remain constant as the scale of the image is changed, and it therefore provides a scale-independent measure of significance that places no prior expectations on the allowable deviations. This significance measure is then used in a modified version of the recursive endpoint subdivision method (see Figure 7). A segment is recursively subdivided at the point with maximum deviation from a line connecting its endpoints (Figure 7 (b,c)). This process is repeated until each segment is no more than 4 pixels in length, producing a binary tree of possible subdivisions. This representation is similar to the strip trees described by Ballard [1]. Then, unwinding the recursion back up the tree, a decision is made at each junction as to whether to replace the current lower-level description with the single higher-level segment. The significance of every subsegment is calculated by its length-to-deviation ratio mentioned above (Figure 7 (d)). If the maximum significance of any of the subsegments is greater than the significance of the complete segment, then the subsegments are returned. Otherwise the single segment is returned. The procedure will return a segment covering every point along the curve (Figure 7 (e)). Finally, any segments with a length-to-deviation ratio less than 4 are discarded.
This algorithm is implemented in only 40 lines of Lisp code, yet it does a reasonable job of detecting the most perceptually significant straight line groupings in the linked point data. An advantage compared to the methods traditionally used in computer vision (which usually set some prior threshold for the amount of ``noise'' to be removed from a curve), is that it will tend to find the same structures regardless of the size at which an object appears in an image. In addition, it will avoid breaking up long lines if its shorter constituents do not appear to have a stronger perceptual basis.