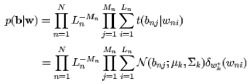|
 |
|
|
Object Recognition |
||||||||||
|
|
"No recognition is possible without knowledge. Decisions about classes or
groups into which recognized objects are classified are based on such
knowledge -- knowledge about objects and their classes gives the necessary
information for object classification." -- Milan Sonka, Vaclav Hlavac & Roger Boyle, Image Processing, Analysis, and Machine Vision Some methods exist for clustering image representations and text to produce models that link images with words (Barnard & Forsyth Exploting image semantics for picture libraries 2001, Barnard & Forsyth Learning the semantics of words and pictures 2001). This work is capable of predicting words for a given image by computing words that have a high posterior probability given the image. This process, referred to as auto-annotation, is useful in itself. In this form however, auto-annotation does not tell us which image structure gives rise to which word. The problem at hand is to construct and train a model using annotated images that allows us to automatically classify specific portions of an image. To make the classification process ammenable to human interpretation, we represent classes using English words. In doing so, the process of annotation becomes analogous to machine translation; we have a representation of one form (image regions) and we wish to turn it into another form (words). In particular, our task is to build a lexicon: a device that predicts one representation (image regions), given another representation (words). |
|
|
|||||||
|
Our solution Our approach is to segment images into regions and then learn to predict words from information about the regions (for background see Duygulu et al Object recognition as machine translation 2002). We use a Bayesian statistical model to find the correlation between the image regions (what we call "blobs") and the word labels. Following this, we guide you through the training process for our probabilistic translation model. |
||||||||||
|
||||||||||
|
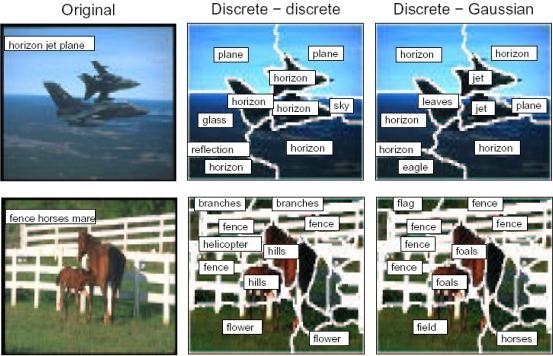
Results Once we have trained our probabilistic translation model using the process described above, we can use it to identify regions within an image. Below are some sample results. Note that we obtain a certain degree of variance in the results because we start with random initializations and therefore the model can end up in suboptimal likelihood (the EM algorithm only guarantees convergence to a local, not global, maximum). Therefore, results can be somewhat difficult to predict. Another problem is that if the training data is biases towards certain images (say, it contains a lot of horses) then the model will place a greater emphasis on the correspondences for those images, and as a result it will predict horses more often then other objects. |
|
|||||||||
|
Publications [1] Nando de Freitas and Kobus Barnard. Bayesian Latent Semantic Analysis of Multimedia Databases. UBC TR 2001-15. [2] Pinary Duygulu, Kobus Barnard, Nando de Freitas and David Forsyth. I. Jordan. Object Recognition as Machine Translation: Learning a Lexicon for a Fixed Image Vocabulary. ECCV 2002. Best Paper prize on Cognitive Computer Vision. [3] Peter Carbonetto, Nando de Freitas, Paul Gustafson and Natalie Thompson. Bayesian Feature Weighting for Unsupervised Learning, with Application to Object Recognition. AI-Stats 2003. |
||||||||||