Hierarchical Clustering and Tagging of Mostly Disconnected Data
Stephen Ingram, Tamara Munzner, and Jonathan Stray
University of British Columbia Department of Computer Science Technical Report TR-2012-01
PDF |
Abstract |
Software |
Video
Paper
Abstract
We define the document set exploration task as the production of an application-specific categorization. Computers can help by producing visualizations of the semantic
relationships in the corpus, but the approach of directly visualizing the vector space representation of the document set via multidimensional scaling (MDS) algorithms
fails to reveal most of the structure because such datasets are mostly disconnected, that is, the preponderance of inter-item distances are large and roughly equal.
Interpreting these large distances as disconnection between items yields a decomposition of the dataset into distinct components with small inter-item distances, that is,
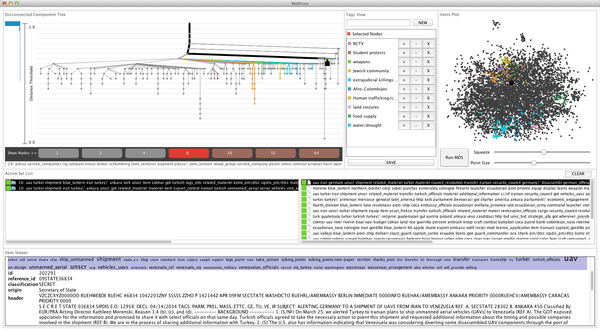
clusters. We propose the Disconnected Component Tree (DiscoTree) as a data structure that encapsulates the hierarchical relationship between components as the
disconnection threshold changes, and present a sampling-based algorithm for efficiently computing the DiscoTree in O(N) time where N is the number of items. We present the
MoDiscoTag application which combines the DiscoTree with an MDS view and a tagging system, and show that it succeeds in resolving structure that is not visible using
previous dimensionality reduction methods. We validate our approach with real-world datasets of WikiLeaks Cables and War Logs from the journalism domain.
Software
The MoDiscoTag software prototype has been incorporated into Overview, an open-source
project of the Associated Press funded by the Knight Foundation. See their site for installation instructions.
Video
- Video (quicktime, 28.9MB, 3 minutes 42 seconds, 960x540 with voiceover)
Stephen Ingram
Last modified: Mon May 14 2012