|
|
High Resolution Passive Facial Performance CaptureDerek Bradley1 Wolfgang Heidrich1 Tiberiu Popa1,2 Alla Sheffer11) University of British Columbia 2) ETH Zurich |
|






ACM Transactions on Graphics (Proceedings of SIGGRAPH 2010)
Download: PDF Main Video Additional Video Slides (without the videos) Data
AbstractWe introduce a purely passive facial capture approach that uses only an array of video cameras, but requires no template facial geometry, no special makeup or markers, and no active lighting. We obtain initial geometry using multi-view stereo, and then use a novel approach for automatically tracking texture detail across the frames. As a result, we obtain a high-resolution sequence of compatibly triangulated and parameterized meshes. The resulting sequence can be rendered with dynamically captured textures, while also consistently applying texture changes such as virtual makeup. |
Overview
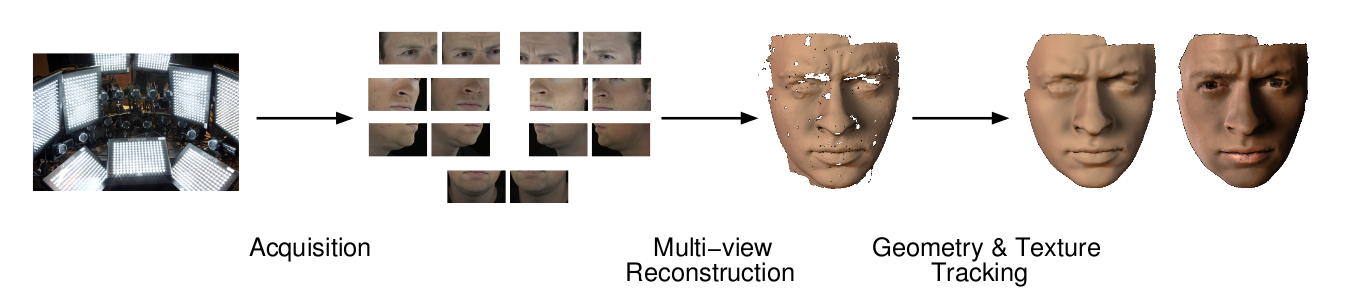
Our capture system consists of the three main components shown in the figure above:
- Acquisition setup: Our setup consists of 14 high definition video cameras, arranged in seven binocular stereo pairs. Each pair is zoomed-in to capture a small patch of the face surface in high detail under bright ambient illumination.
- Multi-view Reconstruction: We use an iterative binocular stereo method to reconstruct each of the seven surface patches independently, and then combine them into a single high-resolution mesh. The zoomed-in cameras allow us to use skin pores, hair follicles and blemishes as surface texture to guide the stereo algorithm, producing meshes with roughly 1 million polygons.
- Geometry and Texture Tracking: In order to consistently track geometry and texture over time, we choose a single reference mesh from the sequence, and compute a mapping between it and every other frame by sequentially using optical flow. The observed pores and other surface details not only serve to provide accurate per-frame reconstructions, but also allow us to compute cross-frame flow. Drift caused by inevitable optical flow error is detected in the per-frame texture maps and corrected in the geometry. In order to account for the high-speed motion generated by talking, the mapping is guided by an edge-based mouth-tracking process.
Results



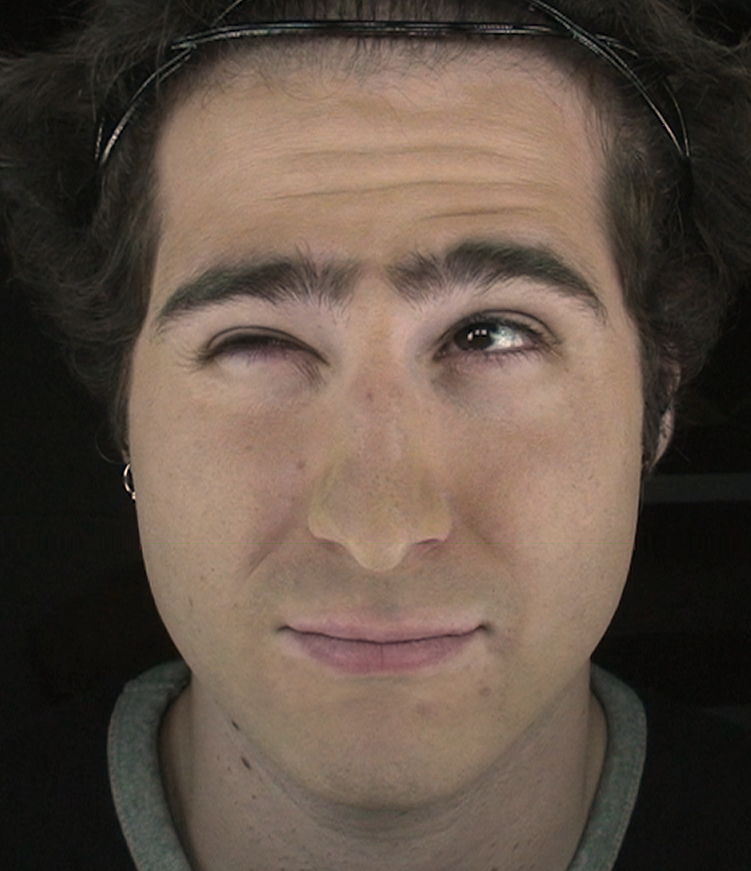




















Capture results for one sequence including the reference footage (top row), pure geometry result (2nd row), skin stretch visualization (3rd row), high-quality rendering with texture (4th row), and virtual makeup (bottom row).






Realistic renderings under various different illuminations and viewpoints.









Capture results for another sequence, including the reference frames (left), pure geometry result (center), and high-quality rendering with texture (right).









Capture results for yet another sequence, including the reference frames (left), pure geometry result (center), and high-quality rendering with texture (right).