Module 4: Protein Structure (2)
Idea:
Given energy function (force field) , we want to use ˇ°genetic algorithmˇ±
to find global minimal.
Generic Algorithm:
Optimization:
To minimize 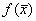 over space
of
over space
of 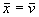
-
Look at population
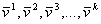 of such
values
of such
values
-
Use genetic operators: mutation, cross-over, to generate offspring
-
Use f to evaluate fitness of all individuals
-
Select individuals that constitute next generation (survivors)
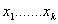
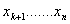

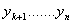
Can choose:
-
Mutation rate , how to mutate, cross-over
-
Initial population
-
Selection (usually population size = number of individuals is
kept constant, can use deterministic or probabilistic choice mechanisms)
Important points:
Historically, GA is defined to operate on binary data.
Thus, are bit vectors
and need to have good encoding scheme.
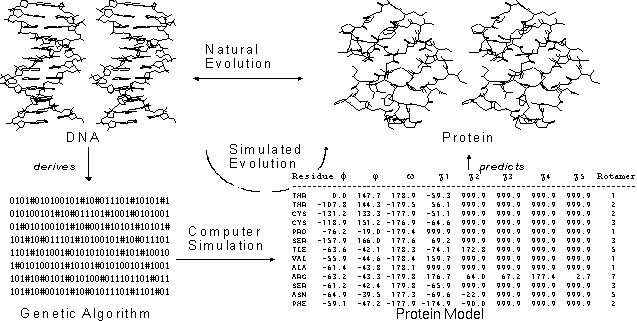
Evolutionary algorithm: like GA, but works directly on non-binary data.
Outline application of EA to tertiary structure prediction.
-
Initialization: starting population is randomly chosen (could also be
based on statistics from protein database, e.g. PDB)
-
Evaluate initial population
-
Generate new individuals
-
Mutate: replace a torsion angle to a randomly selected value (same as above)
-
Variation: increment/decrement torsion angle by
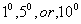
-
Crossover:
-
Two-point crossover (helps to keeps changes in structure reasonably local)
-
Uniform crossover (50%)
-
Generation replacement(selection):elitist

Results (how good is this?)
Crambin:
-
46 residues
-
structure is difficult to predict
-
high resolution structure known(1.5
 )
)
Applying EA (1000 generations, 10 individuals) gives very bad results
(structures found are quite different from native Crambin).
Reason:
The energy model is not good enough. It turns out that the energy of the result
structure is much lower than the energy of the native structure, according
to the energy model.
Note: The approach is much more successful for side-chain packing
Note: The EA can generally can be improved by using more sophisticated (problem specific) search operators (here: "local twist").
Protein Secondary Structure Prediction
Algorithm approaches:
Based on probability of accounting certain AAs as in given secondary
structure(estimate from PDB)
This method gives only about 50% prediction accuracy
-
Chou-Fasman method ( a better one)
-
DonˇŻt look at single AAs, but look at context(a window of AAs).
-
Normalize frequency counts by the frequency of the AA in a family or database of
proteins.
-
Based on normalized frequency counts use rules that predict structure elements
based on local contexts.
e.g. Predict as a -helix :segment of 6
residues
E[Pa ]>1.03
E[Pa ]>E[Pb ]
Not includes Proline.
Accuracy ? 63%
-
Neural Network approaches
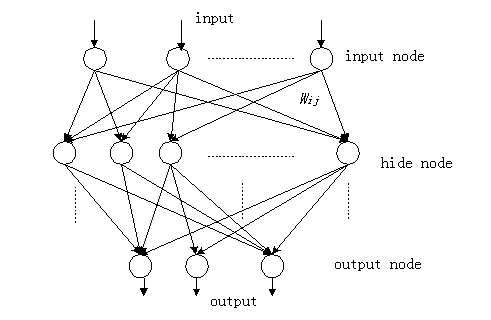
-
Neural network is a nature inspired method
Neural networks are typically organized in layers. Layers are made
up of a number of interconnected 'nodes', which contain an 'activation
function'. Patterns are presented to the network via the 'input layer',
which communicates to one or more 'hidden layers' where the actual processing
is done via a system of weighted 'connections'. The hidden layers then
link to an 'output layer' where the answer is output as shown in the graph
above.
-
Parameters learned from data which are correct 2nd structure.