honorable mention
- Slides (PPTX, PDF)
- Pre-recorded video talk (CHI'23)
- Paper:
- Supplemental materials archived on OSF:
- Section 1: Related work on data science process papers and dirty data taxonomies
- Section 2: Interview study materials
- Section 3: Activity codes through the first two phases of our study
- Section 4: Issue code evolution
- Section 5: Analysis of tool usage among data journalists
- Section 6: Data integration challenges, including nightmare stories

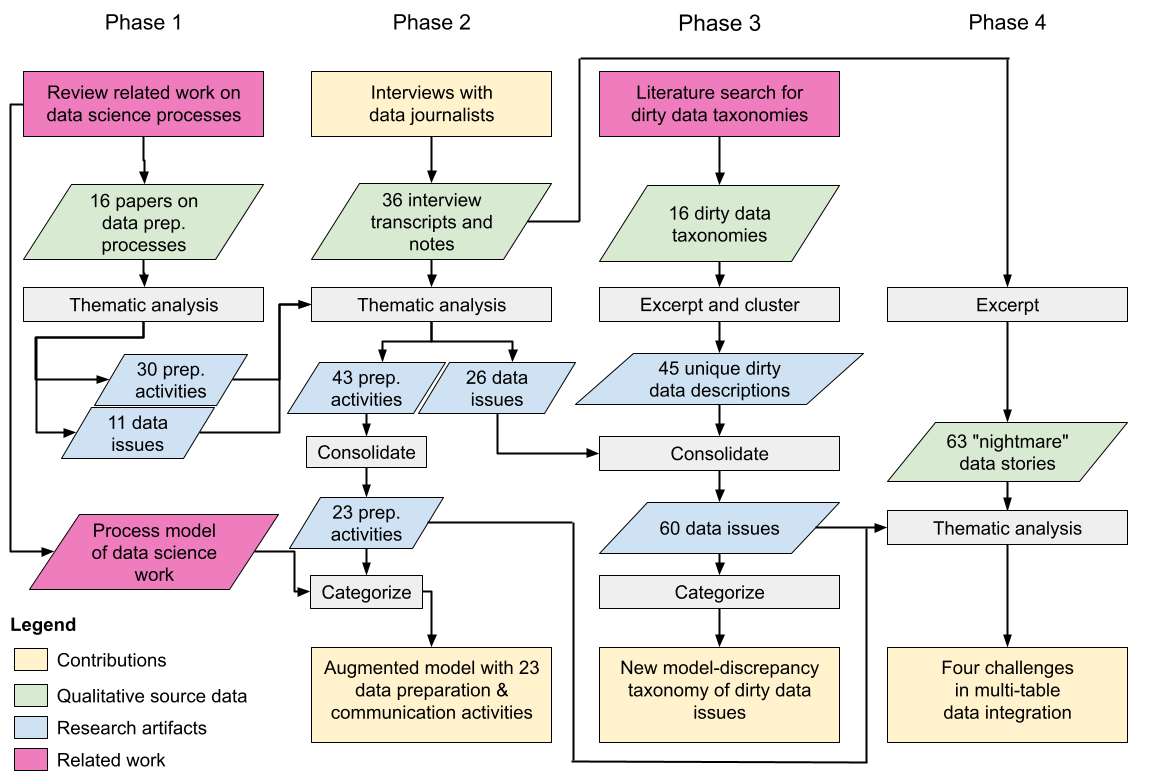
Figure 1: Process, products, and contributions: Our hybrid deductive-inductive thematic analysis [77] began by analyzing 16 studies of data science workflows to generate a priori codes pertaining to data preparation (Phase 1). We then conducted an interview study with 36 data journalists on their preparation processes, generating a posteriori codes from those transcripts (Phase 2). The resulting artifacts yielded combined code sets of preparation activities and data quality issues. Our categorization of these activities extended a previous model of data preparation activities. We then analyzed 16 taxonomies of dirty data issues (Phase 3), noting disparate coverage compared to our interview data. We produced a new model-discrepancy taxonomy for classifying dirty data issues to encompass them all. Finally, we reflected upon emergent patterns of data issues and preparation activities within the nightmare stories section of our interviews to identify four challenges for data integration (Phase 4).

Figure 2: Data preparation activities: From our thematic analysis, we identify 23 activities that data scientists and data journalists perform when preparing data; blue and green backgrounds highlight divergences.

Figure 3: (a) Sixty data issues and which source of data they occur in (data science workflows, data journalism interviews, or dirty data taxonomies), the source phase they were identified in (1-3), and the object and quality the issue corresponds to within our model-discrepancy framework. See Supp. Section 4 for a detailed explanation of each data issue. (b) The distribution of issues above in total and in each group of qualitative source data according to our new taxonomy for classifying dirty data.